Amazon Web Services ブログ
新発表 — Amazon EMR on Amazon Elastic Kubernetes Service (EKS)
数万社のお客様が、Amazon EMR を使用して、Apache Spark、 Hive、HBase、Flink、Hudi、および Presto などのフレームワークでビッグデータ分析アプリケーションを大規模に実行しています。EMR は、これらのフレームワークのプロビジョニングとスケーリングを自動化し、さまざまな EC2 インスタンスタイプでパフォーマンスを最適化して、価格とパフォーマンスの要件を満たします。お客様は現在、Kubernetes を使用して組織全体でコンピューティングプールを統合しています。Amazon Elastic Kubernetes Service (EKS) で Apache Spark を管理しているお客様の一部には、EMR を使用して、フレームワークのインストールと管理、AWS のサービスとの統合などの手間のかかる作業を排除したいと考えているお客様もいらっしゃいます。さらに、EMR が提供するより高速なランタイムや開発およびデバッグのツールも活用したいと考えています。
本日、Amazon EMR on Amazon EKS の一般提供を発表いたします。これは、EMR の新しいデプロイオプションであり、EKS でのオープンソースのビッグデータフレームワークのプロビジョニングと管理を自動化できます。EKS で EMR を使用すると、同じ EKS クラスターで Spark アプリケーションを他のタイプのアプリケーションとともに実行し、リソース使用率を向上させ、インフラストラクチャ管理を簡素化することができます。
他のタイプのアプリケーションと同じ EKS クラスタに EMR アプリケーションをデプロイできるため、リソースを共有し、すべてのアプリケーションを運用および管理する単一のソリューションで標準化できます。最新のフレームワークへのアクセス、パフォーマンスが最適化されたランタイム、アプリケーション開発用の EMR Notebooks、デバッグ用の Spark ユーザーインターフェイスなど、現在 EC2 で使用しているのと同じ EMR 機能をすべて EKS で利用できます。

Amazon EMR は、アプリケーションをビッグデータフレームワークを使用してコンテナに自動的にパッケージ化し、他の AWS のサービスと統合するための事前構築済みのコネクタを提供します。そして、EMR はアプリケーションを EKS クラスターにデプロイし、ログ記録と監視を管理します。EKS で EMR を使用すると、EMR に含まれているパフォーマンスが最適化された Spark ランタイムを使用して、EKS の標準の Apache Spark と比較して、3 倍のパフォーマンスを得ることができます。
EKS での Amazon EMR – 使い方
Spark ジョブを実行する EKS クラスターがすでにある場合は、 AWS マネジメントコンソール、AWS コマンドラインインターフェイス (CLI) または API を使用して、既存の EKS クラスターを EMR に登録するだけで、Spark アプリケーションをデプロイできます。
たとえば、EKS クラスターを登録する簡単な CLI コマンドを次に示します。
$ aws emr create-virtual-cluster \
--name <virtual_cluster_name> \
--container-provider '{
"id": "<eks_cluster_name>",
"type": "EKS",
"info": {
"eksInfo": {
"namespace": "<namespace_name>"
}
}
}'EMR マネジメントコンソールに、仮想クラスターの一覧が表示されます。
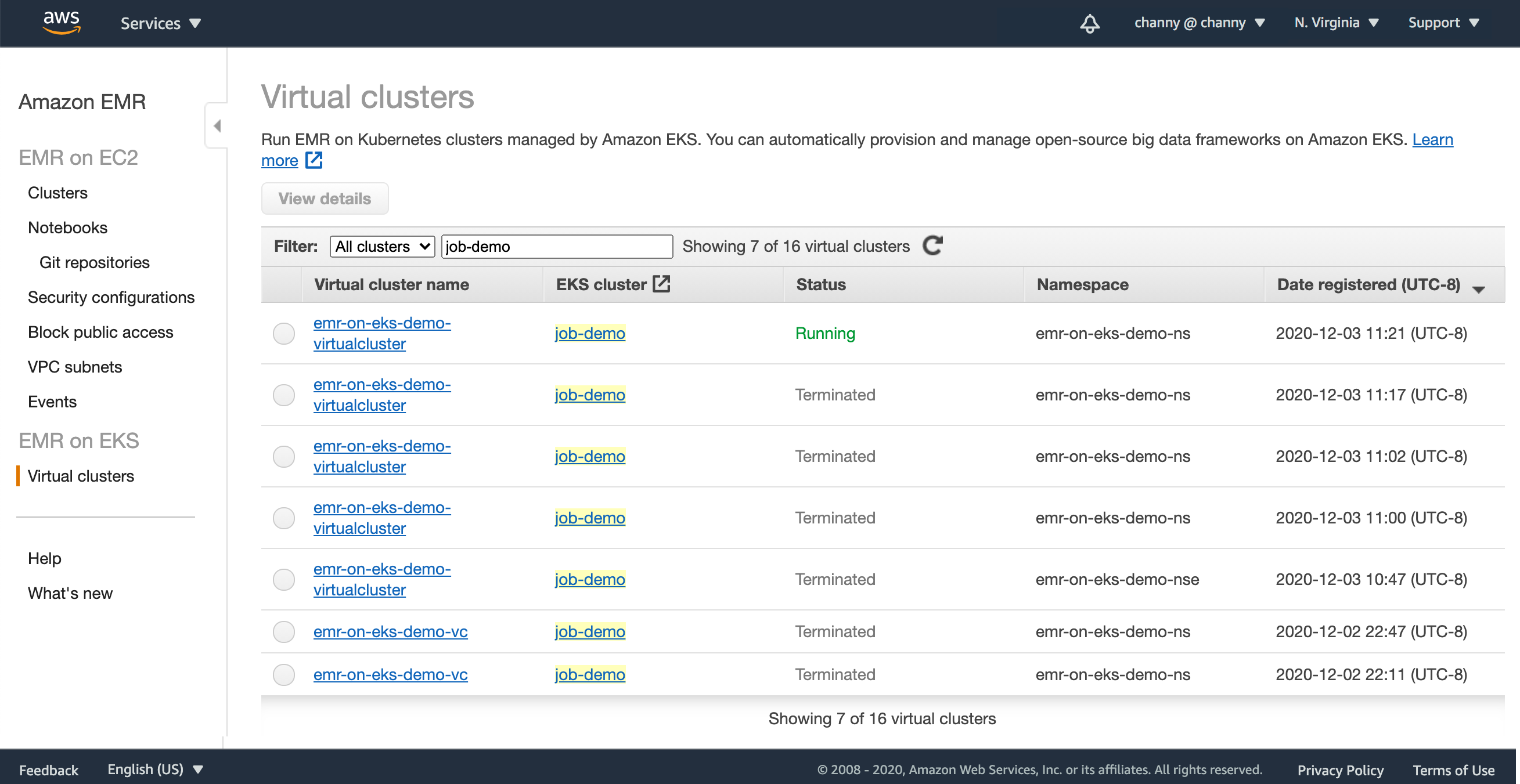
Amazon EKS クラスターが登録されると、EMR ワークロードが Kubernates ノードとポッドにデプロイされてアプリケーションの実行と自動スケーリングを管理し、ノートブックと SQL クライアントを接続できるように管理対象エンドポイントをセットアップします。EMR は、分析アプリケーションで使用されるオープンソースフレームワーク用のパフォーマンスを最適化したランタイムを構築およびデプロイします。
Spark ジョブを開始するだけです。
$ aws emr start-job-run \
--name <job_name> \
--virtual-cluster-id <cluster_id> \
--execution-role-arn <IAM_role_arn> \
--virtual-cluster-id <cluster_id> \
--release-label <<emr_release_label> \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": <entry_point_location>,
"entryPointArguments": ["<arguments_list>"],
"sparkSubmitParameters": <spark_parameters>
}
}'ジョブを監視およびデバッグするには、monitoringConfiguration の一部として設定された Amazon CloudWatch および Amazon Simple Storage Service (S3) のロケーションにアップロードされた検査ログを使用できます。また、コンソールからワンクリックエクスペリエンスを使用して Spark 履歴サーバーを起動することもできます。
Amazon EMR Studio との統合
これで、AWS SDK と AWS CLI、Amazon EMR Studio ノートブック、および Apache Airflow などのワークフローオーケストレーションサービスを使用して分析アプリケーションを送信することができます。Amazon EMR on EKS 用の新しい Airflow Operator も開発しました。このコネクタは、セルフマネージド Airflow で使用することもできますし、Amazon Managed Workflows for Apache Airflow で Plugin Location に追加することもできます。
新しくプレビューした Amazon EMR Studio を使用して、ウェブベースの統合開発環境 (IDE) でデータ分析やデータエンジニアリングのタスクを実行することもできます。Amazon EMR Studio では、Studio インターフェイスを使用して、EKS にデプロイされた EMR クラスターにノートブックコードを送信できます。Studio ユーザーが Workspace をアタッチできる管理対象エンドポイントを 1 つ以上セットアップすると、EMR Studio は仮想クラスターと通信できます。
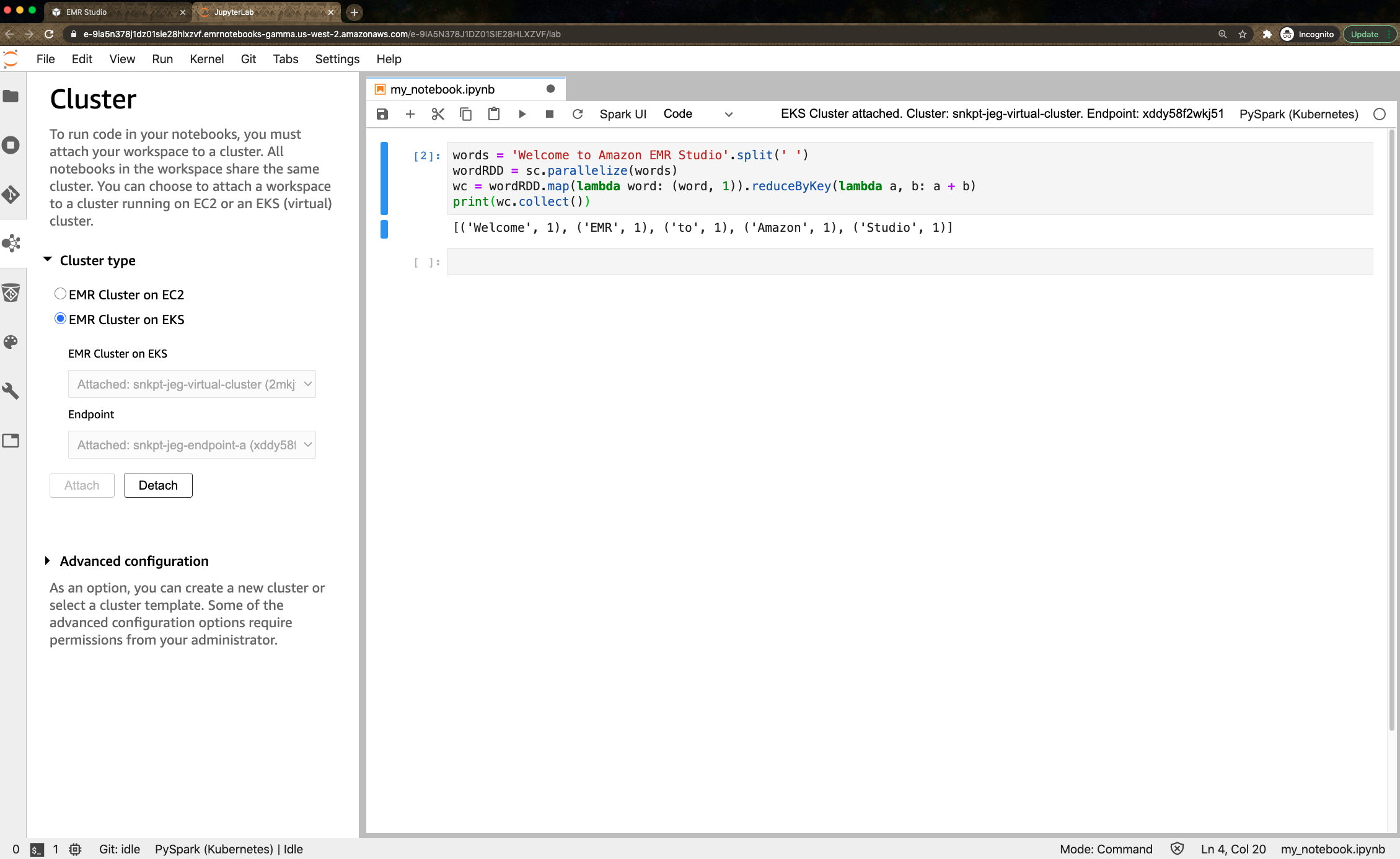
EMR Studio プレビューでは、仮想クラスター用に管理対象エンドポイントを作成しても追加コストはありません。詳細については、ブログ記事とガイドドキュメントを参照してください。
今すぐご利用いただけます
現在、Amazon EMR on Amazon EKS は、米国東部 (バージニア北部)、米国西部 (オレゴン)、および欧州 (アイルランド) の各リージョンでご利用になれます。AWS Fargate for EKS で EMR ワークロードを実行できるため、サーバーレスオプションとしてポッドのインフラストラクチャをプロビジョニングおよび管理する必要がなくなります。
詳細については、ドキュメントを参照してください。フィードバックは、Amazon EMR の AWS フォーラム、または通常の AWS サポート担当者を通じてお寄せください。
Amazon EMR on Amazon EKS に関するすべての詳細を確認し、 今すぐ始めましょう。
— Channy