Amazon Web Services 한국 블로그
Amazon Redshift ML 정식 출시 – SQL기반 기계 학습 모델 생성 및 예측 수행 (서울 리전 포함)
Amazon Redshift를 사용하면 SQL로 엑사바이트의 구조적 및 반구조화된 데이터를 데이터 웨어하우스, 운영 데이터베이스및 데이터 레이크 전반에서 쿼리하고 결합할 수 있습니다. 이제 AQUA (고급 쿼리 가속기) 를 일반적으로 사용할 수 있으므로 추가 비용 및 코드 변경 없이 쿼리 성능을 최대 10배까지 향상시킬 수 있습니다. 실제로 Amazon Redshift는 다른 클라우드 데이터 웨어하우스보다 최대 3배 향상된 가격 대비 성능을 제공합니다.
그러나 한 단계 더 나아가서 이 데이터를 처리하여 기계 학습(ML) 모델을 훈련하고 이러한 모델을 사용하여 웨어하우스의 데이터에서 통찰력을 창출하려면 어떻게 해야 할까요? 예를 들어 매출 예측, 고객 이탈 예측, 이상 징후 탐지 등의 사용 사례를 구현하려면 어떻게 해야 합니까? 이전에는 Amazon Redshift에서 Amazon S3 버킷으로 훈련 데이터를 내보낸 다음 기계 학습 모델 훈련 과정을 구성하고 시작해야 했습니다 (예시:Amazon SageMaker). 이 과정을 완료하려면 여러 가지 기술이, 그리고 일반적으로 한 명 이상의 사람이 필요했습니다. 더 쉽게 만들 수 있을까요?
현재 Amazon Redshift ML은 Amazon Redshift 클러스터에서 직접 기계 학습 모델을 생성, 훈련 및 배포할 수 있도록 일반적으로 제공됩니다. 기계 학습 모델을 만들려면 간단한 SQL 쿼리를 사용하여 모델을 학습하는 데 사용할 데이터와 예측할 출력 값을 지정합니다. 예를 들어 마케팅 활동의 성공률을 예측하는 모델을 만들려면 이전 마케팅 캠페인의 고객 프로필과 결과를 포함하는 열을 하나 이상의 테이블에서 선택하여 입력을 정의하고출력 열을 예측할 수 있습니다. 이 예에서 출력 열은 고객의 캠페인에 대한 관심 여부를 보여 주는 열이 될 수 있습니다.
SQL 명령을 실행하여 모델을 생성한 후 Redshift ML은 Amazon Redshift에서 S3 버킷으로 지정된 데이터를 안전하게 내보내고 Amazon SageMaker Autopilot을 호출하여 데이터 (전처리 및 기능 엔지니어링) 를 준비하고 적절한 사전 구축 알고리즘을 구현하고 모델 학습을위한 알고리즘을 적용할 수 있습니다. 선택적으로 사용할 알고리즘을 지정할 수 있습니다 (예시: XGBoost).

Redshift ML은 훈련 및 컴파일에 관련된 모든 단계를 포함하여 Amazon Redshift, S3 및 SageMaker 간의 모든 상호 작용을 처리합니다. 모델이 훈련되면 Redshift ML은 Amazon SageMaker Neo를 사용하여 배포를 위해 모델을 최적화하고 SQL 함수로 사용할 수 있도록 합니다. SQL 함수를 사용하여 쿼리, 보고서 및 대시보드의 데이터에 기계 학습 모델을 적용할 수 있습니다.
이제 Redshift ML에는 Amazon Virtual Private Cloud(VPC) 지원을 포함하여 미리 보기 중에 사용할 수 없었던 많은 새로운 기능이 포함되어 있습니다. 예를 들면 다음과 같습니다.
- 이제 SageMaker 모델을 Amazon Redshift 클러스터로 가져올 수 있습니다 (로컬 추론).
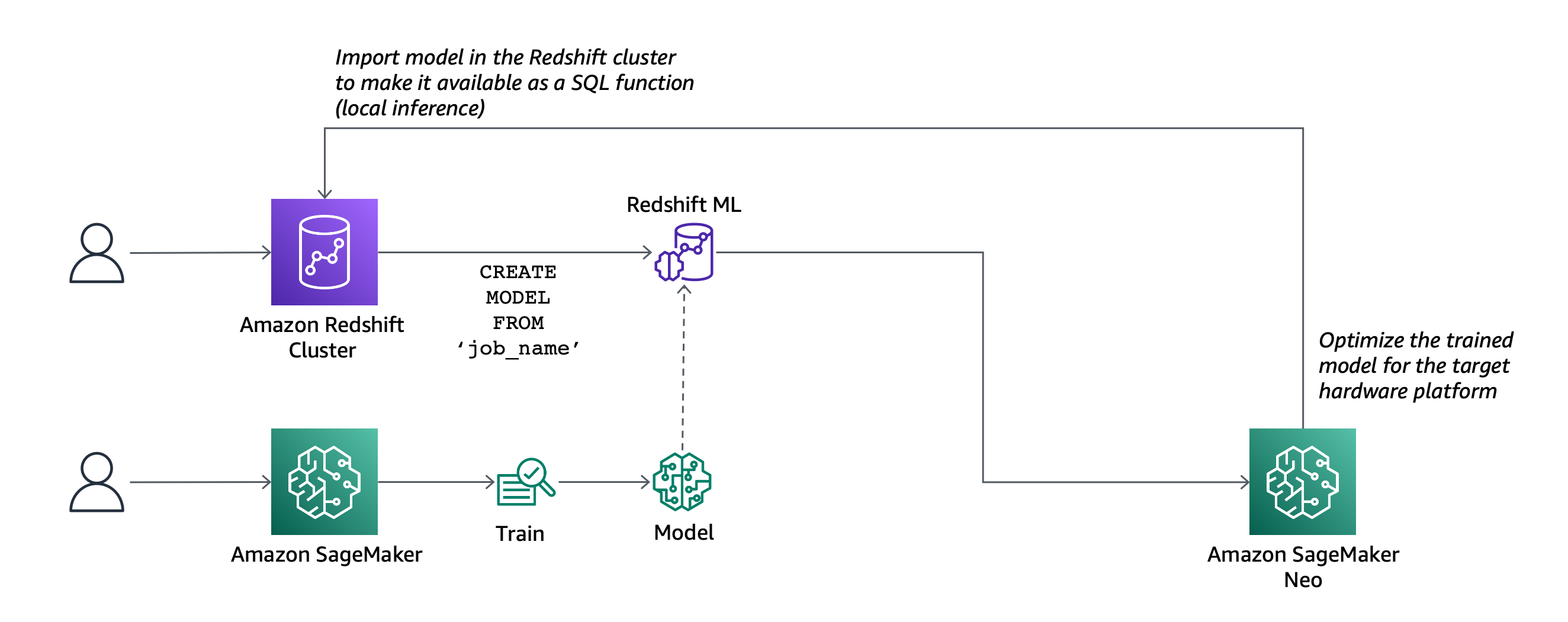
- 기존 SageMaker 엔드포인트를 사용하여 예측 (원격 추론) 을 수행하는 SQL 함수를 생성할 수도 있습니다. 이 경우 Redshift ML은 처리 속도를 높이기 위해 엔드포인트에 대한 호출을 일괄 처리합니다.

이러한 새로운 기능을 실제로 사용하는 방법을 살펴보기 전에 AWS 데이터베이스 및 분석 서비스의 Redshift ML과 유사한 기능의 차이점을 알아보겠습니다.
| ML 기능 | 데이터 | SQL에서
훈련 |
SQL 함수를 사용한
예측 |
| Amazon Redshift ML |
데이터 웨어하우스 S3 데이터 레이크 ( Redshift 스펙트럼 포함) |
예,
Amazon SageMaker 오토파일럿을 사용합니다 |
예. 모델을 Amazon Redshift 클러스터 내에서 가져오고 실행하거나 SageMaker 엔드포인트를 사용하여 호출할 수 있습니다. |
| Amazon Aurora ML | 관계형 데이터베이스
(MySQL 또는 PostgreSQL과 호환) |
아니요 |
예, SageMaker 엔드포인트를사용합니다. 정서 분석을 위해 Amazon Comprehend와의 천연 통합도 사용할 수 있습니다. |
| Amazon Athena ML |
S3 데이터 레이크 다른 데이터 원본은 Athena Federated Query를 통해 사용할 수 있습니다. |
아니요 | 예, SageMaker 엔드포인트를사용합니다. |
Redshift ML을 사용하여 기계 학습 모델 구축
고객이 마케팅 제안을 수락하거나 거부할지 예측하는 모델을 구축해 보겠습니다.
S3 및 SageMaker와의 상호 작용을 관리하기 위해 Redshift ML은 이러한 리소스에 액세스할 수 있는 권한이 필요합니다. AWS Identity and Access Management(IAM) 역할을 설명서에 설명된 대로 만듭니다. 역할 이름에 RedShiftML을 사용합니다. 역할의 신뢰 정책은 Amazon Redshift와 SageMaker가 다른 AWS 서비스와 상호 작용할 수 있는 역할을 허용함을 기억하십시오.
Amazon Redshift 콘솔에서 클러스터를 만듭니다. 클러스터 권한에서 RedshiftML IAM 역할을 연결합니다. 클러스터를 사용할 수 있을 때 이 매우 흥미로운 SageMaker Autopilot이 발표된 시기에 제 동료 Julien이 작성한 블로그 게시물에 사용된 동일한 데이터셋을 로드합니다.
제가 사용하는 파일 (bank-additional-full.csv)은 CSV 형식입니다. 각 라인은 고객과의 직접 마케팅 활동을 설명합니다. 마지막 열 (y) 은 활동의 결과를 설명합니다 (고객이 고객에게 마케팅한 서비스에 가입한 경우).
다음은 처음 몇 개의 줄입니다. 첫 번째 줄은 헤더를 포함합니다.
내 S3 버킷에 파일을 저장합니다. S3 버킷은 데이터를 언로드하고 SageMaker 훈련 아티팩트를 저장하는 데 사용됩니다.
그런 다음 콘솔에서 Amazon Redshift 쿼리 편집기를 사용하여 데이터를 로드하는 테이블을 만듭니다.
CREATE TABLE direct_marketing (
age DECIMAL NOT NULL,
job VARCHAR NOT NULL,
marital VARCHAR NOT NULL,
education VARCHAR NOT NULL,
credit_default VARCHAR NOT NULL,
housing VARCHAR NOT NULL,
loan VARCHAR NOT NULL,
contact VARCHAR NOT NULL,
month VARCHAR NOT NULL,
day_of_week VARCHAR NOT NULL,
duration DECIMAL NOT NULL,
campaign DECIMAL NOT NULL,
pdays DECIMAL NOT NULL,
previous DECIMAL NOT NULL,
poutcome VARCHAR NOT NULL,
emp_var_rate DECIMAL NOT NULL,
cons_price_idx DECIMAL NOT NULL,
cons_conf_idx DECIMAL NOT NULL,
euribor3m DECIMAL NOT NULL,
nr_employed DECIMAL NOT NULL,
y BOOLEAN NOT NULL
);COPY 명령을 사용하여 데이터를 테이블에 로드합니다. 동일한 S3 버킷을 사용하여 데이터를 가져오고 내보내기 때문에 이전에 만든 IAM 역할 (RedShiftML)을 사용할 수 있습니다.
이제 새로운 CREATE MODEL 문을 사용하여 SQL 인터페이스를 직접 모델을 생성합니다.
CREATE MODEL direct_marketing
FROM direct_marketing
TARGET y
FUNCTION predict_direct_marketing
IAM_ROLE 'arn:aws:iam::123412341234:role/RedshiftML'
SETTINGS (
S3_BUCKET 'my-bucket'
);이 SQL 명령에서는 모델 생성에 필요한 매개 변수를 지정합니다.
FROM–direct_marketing테이블의 모든 행을 선택하지만 테이블 이름을 중첩 쿼리로 바꿀 수 있습니다 (아래 예시 참조).TARGET– 예측하고자 하는 열입니다 (이 사례에서y).FUNCTION– 예측을 수행할 SQL 함수의 이름입니다.IAM_ROLE– 모델을 생성, 훈련 및 배포하기 위해서 Amazon Redshift와 SageMaker에서 가정하는 IAM 역할입니다.S3_BUCKET– 학습 데이터가 임시로 저장되는 S3 버킷이며, 모델 객체의 복사본을 유지하도록 선택한 경우 모델 객체가 저장되는 위치입니다.
여기 CREATE MODEL 문에 대한 간단한 구문을 사용하고 있습니다. 고급 사용자의 경우 다음과 같은 다른 옵션을 사용할 수 있습니다.
MODEL_TYPE– XGBoost 또는 다층 퍼셉트론 (MLP) 등의 특정 모델 유형을 훈련에 사용합니다. 이 매개 변수를 지정하지 않으면 SageMaker 오토파일럿은 사용할 적절한 모델 클래스를 선택합니다.PROBLEM_TYPE– 해결할 문제 유형(회귀, 이항 분류 또는 다중 클래스 분류)을 정의합니다. 이 매개 변수를 지정하지 않으면 데이터를 기반으로 학습하는 동안 문제 유형이 발견됩니다.목표– 모델의 품질을 측정하는 데 사용되는 목표 측정 단위입니다. 이 지표는 학습 중에 최적화되어 데이터에서 최상의 추정치를 제공합니다. 메트릭을 지정하지 않으면 회귀 분석에 MSE (평균 제곱 오차), 이진 분류의 경우 F1 점수 및 다중 클래스 분류의 정확도를 사용하는 것이 기본 동작입니다. 다른 사용 가능한 옵션은 F1매크로 (다중 클래스 분류에 F1 점수 적용) 와 곡선 아래의 영역 (AUC)입니다. 목표 지표에 대한 자세한 내용은 SageMaker 설명서에서 확인할 수 있습니다.
모델의 복잡성과 데이터 양에 따라 모델을 사용할 수 있으며, 약간의 시간이 걸릴 수 있습니다. SHOW MODEL 명령을 사용하여 사용 가능한 시기를 확인합니다.
콘솔에서 쿼리 편집기를 사용하여 이 명령을 실행하면 다음과 같은 출력을 얻습니다.

예상대로 모델이 현재 TRAINING 상태입니다.
이 모델을 만들 때 테이블의 모든 열을 입력 매개 변수로 선택했습니다. 소량의 입력 매개 변수를 사용하는 모델을 만들면 어떻게 됩니까? 클라우드를 사용하며 제한된 리소스로 인해 속도가 느려지지 않으므로 테이블의 열 하위 집합을 사용하여 다른 모델을 생성합니다.
CREATE MODEL simple_direct_marketing
FROM (
SELECT age, job, marital, education, housing, contact, month, day_of_week, y
FROM direct_marketing
)
TARGET y
FUNCTION predict_simple_direct_marketing
IAM_ROLE 'arn:aws:iam::123412341234:role/RedshiftML'
SETTINGS (
S3_BUCKET 'my-bucket'
);얼마 후 첫 번째 모델이 준비되었으며 SHOW MODEL에서 이 출력을 얻었습니다. 콘솔의 실제 출력은 여러 페이지에 있으며 해당 결과를 병합하여 쉽게 따라갈 수 있었습니다.

결과에서 모델이 BinaryClassification로 올바르게 인식되고, F1이 목표로 선택되었음을 알 수 있습니다. F1 점수는 정밀도 및 리콜을 모두 고려하는 지표입니다. 1 (완벽한 정밀도 및 리콜) 과 0 (가능한 가장 낮은 점수) 사이의 값을 반환합니다. 모델의 최종 점수 (validation:f1)는 0.79입니다. 이 표에서 모델에 대해 생성된 SQL 함수 (predict_direct_marketing) 이름, 그 해당 매개 변수 및 유형 및 훈련 비용 추정도 찾았습니다.
두 번째 모형이 준비되면 F1 점수를 비교합니다. 두 번째 모델의 F1 점수는 첫 번째 점수보다 낮습니다 (0.66). 그러나 매개 변수가 적을수록 SQL 함수는 새 데이터에 더 쉽게 적용할 수 있습니다. 기계 학습의 경우와 마찬가지로 복잡성과 유용성 사이의 적절한 균형을 찾아야 합니다.
Redshift ML을 사용하여 예측 생성
이제 두 모델이 준비되었으므로 SQL 함수를 사용하여 예측할 수 있습니다. 첫 번째 모델을 사용하여 훈련에 사용된 동일한 데이터에 모델을 적용 할 때 얼마나 많은 거짓 양성 (잘못된 긍정적 예측)과 거짓 음성 (잘못된 부정적 예측)을 확인합니다.
SELECT predict_direct_marketing, y, COUNT(*)
FROM (SELECT predict_direct_marketing(
age, job, marital, education, credit_default, housing,
loan, contact, month, day_of_week, duration, campaign,
pdays, previous, poutcome, emp_var_rate, cons_price_idx,
cons_conf_idx, euribor3m, nr_employed), y
FROM direct_marketing)
GROUP BY predict_direct_marketing, y;쿼리의 결과는 모델이 긍정적 결과가 아닌 부정적 결과를 예측하는 편이 더 낫다는 것을 보여줍니다. 사실 실제 음성이 실제 양성보다 훨씬 많더라도, 거짓 음성보다 거짓 양성이 훨씬 많습니다. 결과의 의미를 명확히 하기 위해 다음 스크린 샷에 녹색과 빨간색의 주석을 추가했습니다.

두 번째 모델을 사용하면 마케팅 캠페인에 얼마나 많은 고객이 관심을 가질 수 있는지 알 수 있습니다. 이상적으로는 훈련에 사용한 동일 데이터가 아닌 새로운 고객 데이터에 대하여 이 쿼리를 실행해야 합니다.
카운트 셀렉트(*)
FROM direct_marketing
WHERE predict_simple_direct_marketing(
age, job, marital, education, housing,
contact, month, day_of_week) = true;놀랍네요, 결과를 보면 7,000개 이상의 전망이 있습니다!

가용성 및 요금
Redshift ML은 현재 미국 동부(오하이오), 미국 동부(버지니아 북부), 미국 서부(오레곤), 미국 서부(샌프란시스코), 캐나다(중부), EU(프랑크푸르트), EU(아일랜드), EU(파리), EU(스톡홀름), 아시아 태평양(홍콩), 아시아 태평양(도쿄), 아시아 태평양(싱가포르), 아시아 태평양(시드니) 및 남아메리카(상파울루) 외 AWS 리전에서 사용할 수 있습니다. 자세한 내용은 AWS 리전 서비스 목록을 참조하십시오.
Redshift ML을 사용할 때는 사용한 만큼만 요금을 지불합니다. 새 모델을 훈련할 때 Redshift ML에서 사용하는 Amazon SageMaker 오토파일럿 및 S3 리소스에 대한 비용을 지불합니다. 예측 시 이 게시물에서 사용된 예시처럼 Amazon Redshift 클러스터로 가져온 모델에 대한 추가 비용은 청구되지 않습니다.
또한 Redshift ML을 사용하면 기존 Amazon SageMaker 엔드포인트를 추론할 수 있습니다. 이 경우 실시간 추론에 대한 일반적인 SageMaker 가격이 적용됩니다. 여기에서 Redshift ML을 사용하여 비용을 제어하는 방법에 대한 몇 가지 팁을 찾을 수 있습니다.
자세한 내용은 Redshift ML이 미리 보기 및 설명서에서발표된 시기의 블로그 게시물을 볼 수 있습니다.
Redshift ML을 사용하여 데이터에서 더 나은 통찰력을 얻을 수 있습니다.
— Danilo