AWS Compute Blog
Avoiding recursive invocation with Amazon S3 and AWS Lambda
Serverless applications are often composed of services sending events to each other. In one common architectural pattern, Amazon S3 send events for processing with AWS Lambda. This can be used to build serverless microservices that translate documents, import data to Amazon DynamoDB, or process images after uploading.
To avoid recursive invocations between S3 and Lambda, it’s best practice to store the output of a process in a different resource from the source S3 bucket. However, it’s sometimes useful to store processed objects in the same source bucket. In this blog post, I show three different ways you can do this safely and provide other important tips if you use this approach.
The example applications use the AWS Serverless Application Model (AWS SAM), enabling you to deploy the applications more easily to your own AWS account. This walkthrough creates resources covered in the AWS Free Tier but usage beyond the Free Tier allowance may incur cost. To set up the examples, visit the GitHub repo and follow the instructions in the README.md file.
Overview
Infinite loops are not a new challenge for developers. Any programming language that supports looping logic has the capability to generate a program that never exits. However, in serverless applications, services can scale as traffic grows. This makes infinite loops more challenging since they can consume more resources.
In the case of the S3 to Lambda recursive invocation, a Lambda function writes an object to an S3 object. In turn, it invokes the same Lambda function via a put event. The invocation causes a second object to be written to the bucket, which invokes the same Lambda function, and so on:

If you trigger a recursive invocation loop accidentally, you can press the “Throttle” button in the Lambda console to scale the function concurrency down to zero and break the recursion cycle.
The most practical way to avoid this possibility is to use two S3 buckets. By writing an output object to a second bucket, this eliminates the risk of creating additional events from the source bucket. As shown in the first example in the repo, the two-bucket pattern should be the preferred architecture for most S3 object processing workloads:

If you need to write the processed object back to the source bucket, here are three alternative architectures to reduce the risk of recursive invocation.
(1) Using a prefix or suffix in the S3 event notification
When configuring event notifications in the S3 bucket, you can additionally filter by object key, using a prefix or suffix. Using a prefix, you can filter for keys beginning with a string, or belonging to a folder, or both. Only those events matching the prefix or suffix trigger an event notification.
For example, a prefix of “my-project/images” filters for keys in the “my-project” folder beginning with the string “images”. Similarly, you can use a suffix to match on keys ending with a string, such as “.jpg” to match JPG images. Prefixes and suffixes do not support wildcards so the strings provided are literal.
The AWS SAM template in this example shows how to define a prefix and suffix in an S3 event notification. Here, the S3 invokes the Lambda function if the key begins with ‘original/’ and ends with ‘.txt’:
S3ProcessorFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/
Handler: app.handler
Runtime: nodejs14.x
MemorySize: 128
Policies:
- S3CrudPolicy:
BucketName: !Ref SourceBucketName
Environment:
Variables:
DestinationBucketName: !Ref SourceBucketName
Events:
FileUpload:
Type: S3
Properties:
Bucket: !Ref SourceBucket
Events: s3:ObjectCreated:*
Filter:
S3Key:
Rules:
- Name: prefix
Value: 'original/'
- Name: suffix
Value: '.txt'
You can then write back to the same bucket providing that the output key does not match the prefix or suffix used in the event notification. In the example, the Lambda function writes the same data to the same bucket but the output key does not include the ‘original/’ prefix.
To test this example with the AWS CLI, upload a sample text file to the S3 bucket:
aws s3 cp sample.txt s3://myS3bucketname
Shortly after, list the objects in the bucket. There is a second object with the same key with no folder name. The first uploaded object invoked the Lambda function due to the matching prefix. The second PutObject action without the prefix did not trigger an event notification and invoke the function.

Providing that your application logic can handle different prefixes and suffixes for source and output objects, this provides a way to use the same bucket for processed objects.
(2) Using object metadata to identify the original S3 object
If you need to ensure that the source object and processed object have the same key, configure user-defined metadata to differentiate between the two objects. When you upload S3 objects, you can set custom metadata values in the S3 console, AWS CLI, or AWS SDK.
In this design, the Lambda function checks for the presence of the metadata before processing. The Lambda handler in this example shows how to use the AWS SDK’s headObject method in the S3 API:
const AWS = require('aws-sdk')
AWS.config.region = process.env.AWS_REGION
const s3 = new AWS.S3()
exports.handler = async (event) => {
await Promise.all(
event.Records.map(async (record) => {
try {
// Decode URL-encoded key
const Key = decodeURIComponent(record.s3.object.key.replace(/\+/g, " "))
const data = await s3.headObject({
Bucket: record.s3.bucket.name,
Key
}).promise()
if (data.Metadata.original != 'true') {
console.log('Exiting - this is not the original object.', data)
return
}
// Do work ... /
} catch (err) {
console.error(err)
}
})
)
}
To test this example with the AWS CLI, upload a sample text file to the S3 bucket using the “original” metatag:
aws s3 cp sample.txt s3://myS3bucketname --metadata '{"original":"true"}'
Shortly after, list the objects in the bucket – the original object is overwritten during the Lambda invocation. The second S3 object causes another Lambda invocation but it exits due to the missing metadata.
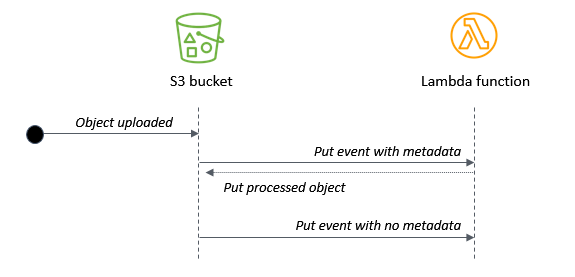
This allows you to use the same bucket and key name for processed objects, but it requires that the application creating the original object can set object metadata. In this approach, the Lambda function is always invoked twice for each uploaded S3 object.
(3) Using an Amazon DynamoDB table to filter duplicate events
If you need the output object to have the same bucket name and key but you cannot set user-defined metadata, use this design:

In this example, there are two Lambda functions and a DynamoDB table. The first function writes the key name to the table. A DynamoDB stream triggers the second Lambda function which processes the original object. It writes the object back to the same source bucket. Because the same item is put to the DynamoDB table, this does not trigger a new DynamoDB stream event.
To test this example with the AWS CLI, upload a sample text file to the S3 bucket:
aws s3 cp sample.txt s3://myS3bucketname
Shortly after, list the objects in the bucket. The original object is overwritten during the Lambda invocation. The new S3 object invokes the first Lambda function again but the second function is not triggered. This solution allows you to use the same output key without user-defined metadata. However, it does introduce a DynamoDB table to the architecture.
To automatically manage the table’s content, the example in the repo uses DynamoDB’s Time to Live (TTL) feature. It defines a TimeToLiveSpecification in the AWS::DynamoDB::Table resource:
## DynamoDB table
DDBtable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: ID
AttributeType: S
KeySchema:
- AttributeName: ID
KeyType: HASH
TimeToLiveSpecification:
AttributeName: TimeToLive
Enabled: true
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_IMAGE
When the first function writes the key name to the DynamoDB table, it also sets a TimeToLive attribute with a value of midnight on the next day:
// Epoch timestamp set to next midnight
const TimeToLive = new Date().setHours(24,0,0,0)
// Create DynamoDB item
const params = {
TableName : process.env.DDBtable,
Item: {
ID: Key,
TimeToLive
}
}
The DynamoDB service automatically expires items once the TimeToLive value has passed. In this example, if another object with the same key is stored in the S3 bucket before the TTL value, it does not trigger a stream event. This prevents the same object from being processed multiple times.
Comparing the three approaches
Depending upon the needs of your workload, you can choose one of these three approaches for storing processed objects in the same source S3 bucket:
| 1. Prefix/suffix | 2. User-defined metadata | 3. DynamoDB table | |
| Output uses the same bucket | Y | Y | Y |
| Output uses the same key | N | Y | Y |
| User-defined metadata | N | Y | N |
| Lambda invocations per object | 1 | 2 | 2 for an original object. 1 for a processed object. |
Monitoring applications for recursive invocation
Whenever you have a Lambda function writing objects back to the same S3 bucket that triggered the event, it’s best practice to limit the scaling in the development and testing phases.
Use reserved concurrency to limit a function’s scaling, for example. Setting the function’s reserved concurrency to a lower limit prevents the function from scaling concurrently beyond that limit. It does not prevent the recursion, but limits the resources consumed as a safety mechanism.
Additionally, you should monitor the Lambda function to make sure the logic works as expected. To do this, use Amazon CloudWatch monitoring and alarming. By setting an alarm on a function’s concurrency metric, you can receive alerts if the concurrency suddenly spikes and take appropriate action.
Conclusion
The S3-to-Lambda integration is a foundational building block of many serverless applications. It’s best practice to store the output of the Lambda function in a different bucket or AWS resource than the source bucket.
In cases where you need to store the processed object in the same bucket, I show three different designs to help minimize the risk of recursive invocations. You can use event notification prefixes and suffixes or object metadata to ensure the Lambda function is not invoked repeatedly. Alternatively, you can also use DynamoDB in cases where the output object has the same key.
To learn more about best practices when using S3 to Lambda, see the Lambda Operator Guide. For more serverless learning resources, visit Serverless Land.