AWS Compute Blog
Creating a scalable serverless import process for Amazon DynamoDB
Amazon DynamoDB is a web-scale NoSQL database designed to provide low latency access to data. It’s well suited to many serverless applications as a primary data store, and fits into many common enterprise architectures. In this post, I show how you can import large amounts of data to DynamoDB using a serverless approach. This uses Amazon S3 as a staging area and AWS Lambda for the custom business logic.
This pattern is useful as a general import mechanism into DynamoDB because it separates the challenge of scaling from the data transformation logic. The incoming data is stored in S3 objects, formatted as JSON, CSV, or any custom format your applications produce. The process works whether you import only a few large files or many small files. It takes advantage of parallelization to import data quickly into a DynamoDB table.
This is useful for applications where upstream services produce transaction information, and can be effective for handling data generated by spiky workloads. Alternatively, it’s also a simple way to migrate from another data source to DynamoDB, especially for large datasets.
In this blog post, I show two different import applications. The first is a direct import into the DynamoDB table. The second explores a more advanced method for smoothing out volume in the import process. The code uses the AWS Serverless Application Model (SAM), enabling you to deploy the application in your own AWS Account. This walkthrough creates resources covered in the AWS Free Tier but you may incur cost for large data imports.
To set up both example applications, visit the GitHub repo and follow the instructions in the README.md file.
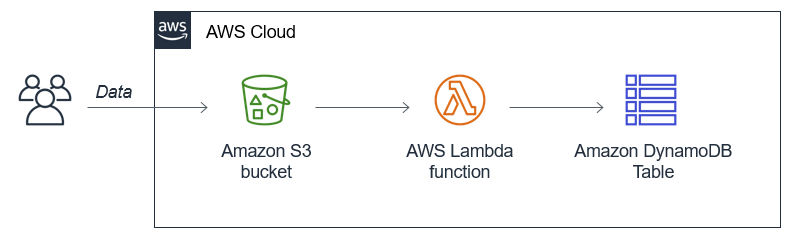
Directly importing data from S3 to DynamoDB
The first example application loads data directly from S3 to DynamoDB via a Lambda function. This uses the following architecture:

- A downstream process creates source import data in JSON format and writes to an S3 bucket.
- When the objects are saved, S3 invokes the main Lambda function.
- The function reads the S3 object and converts the JSON into the correct format for the DynamoDB table. It uploads this data in batches to the table.
The repo’s SAM template creates a DynamoDB table with a partition key, configured to use on-demand capacity. This mode enables the DynamoDB service to scale appropriately to match the number of writes required by the import process. This means you do not need to manage DynamoDB table capacity, as you would in the standard provisioned mode.
DDBtable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: ID
AttributeType: S
KeySchema:
- AttributeName: ID
KeyType: HASH
BillingMode: PAY_PER_REQUEST
The template defines the Lambda function to import the data:
ImportFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: importFunction/
Handler: app.handler
Runtime: nodejs12.x
MemorySize: 512
Environment:
Variables:
DDBtable: !Ref DDBtable
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref DDBtable
- S3ReadPolicy:
BucketName: !Ref InputBucketName
Events:
FileUpload:
Type: S3
Properties:
Bucket: !Ref InputS3Bucket
Events: s3:ObjectCreated:*
Filter:
S3Key:
Rules:
- Name: suffix
Value: '.json'
This uses SAM policy templates to provide write access to the DynamoDB table and read access to S3 bucket. It also defines the event that causes the function invocation from S3, filtering only for new objects with a .json suffix.
Testing the application
- Deploy the first application by following the README.md in the GitHub repo, and note the application’s S3 bucket name and DynamoDB table name.
- Change into the dataGenerator directory:
cd ./dataGenerator - Create sample data for testing. The following command creates 10 files of 100 records each:
node ./app.js 100 10 - Upload the sample data into your application’s S3 bucket, replacing your-bucket below with your bucket name:
aws s3 cp ./data/ s3://your-bucket --recursiveYour console output shows the following, confirming that the sample data is uploaded to S3.
- After a few seconds, enter this command to show the number of items in the application’s DynamoDB table. Replace your-table with your deployed table name:
aws dynamodb scan --table-name your-table --select "COUNT"Your console output shows that 1,000 items are now stored in the DynamoDB and the files are successfully imported.
With on-demand provisioning, the per-table limit of 40,000 write request units still applies. For high volumes or sudden, spiky workloads, DynamoDB may throttle the import when using this approach. Any throttling events appears in the Metrics tab of the table in the DynamoDB service console. Throttling is intended to protect your infrastructure but there are times when you want to process these high volumes. The second application in the repo shows how to address this.
Handling extreme loads and variability in the import process
In this next example, the goal is to smooth out the traffic, so that the load process into DynamoDB is much more consistent. The key service used to achieve this is Amazon SQS, which holds all the items until a loader process stores the data in DynamoDB. The architecture looks like this:

- A downstream process creates source import data in JSON format and writes to an S3 bucket.
- When the objects are saved, S3 invokes a Lambda function that transforms the input and adds these as messages in an Amazon SQS queue.
- The Lambda polls the SQS queue and invokes a function to process the messages batches.
- The function converts the JSON messages into the correct format for the DynamoDB table. It uploads this data in batches to the table.
Testing the application
In this test, you generate a much larger amount of data using a greater number of S3 objects. The instructions below creates 100,000 sample records, so running this code may incur cost on your AWS bill.
- Deploy the second application by following the README.md in the GitHub repo, and note the application’s S3 bucket name and DynamoDB table name.
- Change into the dataGenerator directory:
cd ./dataGenerator
- Create sample data for testing. The following command creates 100 files of 1,000 records each:
node ./app.js 1000 100
- Upload the sample data into your application’s S3 bucket, replacing your-bucket below with your deployed bucket name:
aws s3 cp ./data/ s3://your-bucket --recursiveThis process takes around 10 minutes to complete with the default configuration in the repo. - From the DynamoDB console, select the application’s table and then choose the Metrics tab. Select the Write capacity graph to zoom into the chart:

The default configuration deliberately slows down the load process to illustrate how it works. Using this approach, the load into the database is much more consistent, consuming between 125-150 write capacity units (WCUs) per minute. This design makes it possible to vary how quickly you load data into the DynamoDB table, depending upon the needs of your use-case.
How this works
In this second application, there are multiple points where the application uses a configuration setting to throttle the flow of data to the next step.
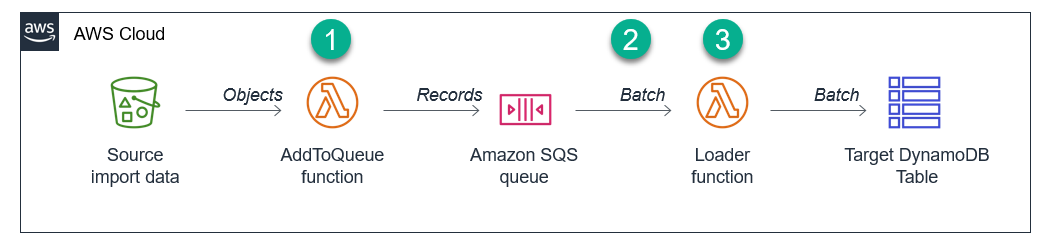
- AddToQueue function: this loads data from the source S3 object into SQS in batches of 25 messages. Depending on the size of your source records, you may add more records into a single SQS message, which has a size limit of 256 Kb. You can also compress this message with gzip to further add more records.
- Function concurrency: the SAM template sets the Loader function’s concurrency to 1, using the ReservedConcurrentExecutions attribute. In effect, this stops Lambda from scaling this function, which means it keeps fetching the next batch from SQS as soon as processing finishes. The concurrency is a multiplier – as this value is increased, the loading into the DynamoDB table increases proportionately, if there are messages available in SQS. Select a value greater than 1 to use parallelization in the load process.
- Loader function: this consumes messages from the SQS queue. The BatchSize configured in the SAM template is set to four messages per invocation. Since each message contains 25 records, this represents 100 records per invocation when the queue has enough messages. You can set a BatchSize value from 1 to 10, so could increase this from the application’s default.
When you combine these settings, it’s possible to dramatically increase the throughput for loading data into DynamoDB. Increasing the load also increases WCUs consumed, which increases cost. Your use case can inform you about the optimal balance between speed and cost. You can make changes, too – it’s simple to make adjustments to meet your requirements.
Additionally, each of the services used has its own service limits. For high production loads, it’s important to understand the quotas set, and whether these are soft or hard limits. If your application requires higher throughput, you can request raising soft limits via an AWS Support Center ticket.
Conclusion
DynamoDB does not offer a native import process and existing solutions may not meet your needs for unplanned, large-scale imports. The AWS Database Migration Service is not serverless, and the AWS Data Pipeline is schedule-based rather than event-based. This solution is designed to provide a fully serverless alternative that responds to incoming data to S3 on-demand.
In this post, I show how you can create a simple import process directly to the DynamoDB table, triggered by objects put into an S3 bucket. This provides a near-real time import process. I also show a more advanced approach to smooth out traffic for high-volume or spiky workloads. This helps create a resilient and consistent data import for DynamoDB.
To learn more, watch this video to see how to deploy and test the DynamoDB importer application.