AWS Database Blog
Implementing priority queueing with Amazon DynamoDB
Queuing is a commonly used solution for separating computation components in a distributed processing system. It is a form of the asynchronous communication system used in serverless and microservices architectures. Messages wait in a queue for processing, and leave the queue when received by a single consumer. This type of messaging pattern is known as point-to-point communication.
This post describes how to convert any of your Amazon DynamoDB tables into a queue that can enqueue (placing a message into the queue) and dequeue (reading and removing the message from the queue), as you would do with any other large-scale queuing systems.
DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a serverless and fully managed service that you can use for mobile, web, gaming, ad tech, IoT, and other applications that need low-latency data access at a large scale.
There are many queuing implementations that offer persistence, single-message processing, and distributed computing. Some popular queuing solutions are Amazon SQS, Amazon MQ, Apache ActiveMQ, RabbitMQ, and Kafka. Those services handle various queuing features and functions with several different characteristics, such as methods of implementation, scaling, and performance.
However, most of those queuing systems cannot easily change the order of the items after they arrive in the queue. Discussed implementation with DynamoDB can change the order in the queue or cancel items before processing.
This post also discusses important aspects of DynamoDB’s queuing system, such as changing an item’s priority, allowing only one consumer per message, removing a message upon successful processing, how to guarantee the order of message processing, and how to handle exceptions.
Regular and priority queues
A queue is an abstract data type that defines a linear data structure to keep a collection of items (messages) in an order. A single consumer processes an individual message only once. One of the most common queuing methods is a first-in-first-out (FIFO) structure, in which new items join at the end of the queue and the queue processes in order from the front (head).
This post demonstrates how to enhance a typical message queuing implementation by adding a feature to sort messages in the queue by a message’s characteristic. This is known as a priority queue.
In a priority queue, each item has an additional attribute that defines its priority in the queue. As the priority changes, the order of the items in the queue changes. Priority queues frequently use a structure known as a heap, or use self-balancing trees.
DynamoDB uses a global secondary index (GSI) for sorting items (records) dynamically. As long the queue item is still visible (not yet processed), you can alter the order of the item in the queue.
Solution Architecture
This post uses a scenario in which you have a microservice that uses a table in the DynamoDB. The post also introduces a shipment, a hypothetical application object, to illustrate the main queuing idea. You can’t ship the shipment before locating all the items in the warehouse and confirm they are ready to ship. When the shipment is ready, you can mark it as such and place it in your FIFO queue for downstream processing, in which the queue uses an item’s timestamp as its priority attribute.
The following diagram illustrates this workflow:

The architecture for this post is relatively simple. You can create a simple domain-specific language (DSL) with JSON to describe your AWS services. The file gets parsed into metadata and goes to an AWS Cloud Development Kit (AWS CDK), which builds and deploys the necessary pieces in AWS (IAM Role, DynamoDB, Lambda, and Amazon S3). AWS CDK is a software development framework that supports several programming languages to define cloud infrastructure in code and provision it through AWS CloudFormation. For more information, see What Is the AWS CDK?
Once the basic example is covered, we will discuss some other important aspects of a queueing systems, such as changing item’s priority, allowing only one consumer per message, removing a message upon successful processing, how to guarantee the order of the message processing, and exception handling.
Architectural Overview
Architecture for this Blog post is relatively simple. We have created a simple Domain Specific Language (DSL) for describing our services in AWS, using JSON. JSON file gets parsed into metadata and it is fed to a Cloud Development Kit (CDK) which in turn builds and deploys all necessary infrastructure components in AWS, such as DynamoDB. CDK is a software development framework, supporting number of programming languages, for defining cloud infrastructure in code and provisioning it through AWS CloudFormation.

For the purpose of running your code quickly, we have provided a Cloud Formation JSON template that you can use to create a demo table in DynamoDB. To run the demo, there are no need to deploy any other AWS components. You need only your terminal and capability to run Java code.
Accompanying project comes with the following artifacts:
- DSL (JSON) defining our infrastructure and services components
- Code build scripts
- CDK (build and deploy AWS components) + Cloud Formation JSON template
- Custom Shipment SDK
- Shipment model
- Queue management
- APIs
- Test application scripts (producer and consumer)
- Command Line interface (CLI) for educational and testing purposes
DynamoDB model attributes
Our Shipment’s DynamoDB data model is simple, initially composed from a few attributes, such as:
- id, as a partition (primary) key
- data, attribute storing all your application data as a Map
- system_info as a map of various system information that we’ll use to track the state of the application object, and finally
- last_updated_timestamp, to keep the value of the latest timestamp in UTC.
Once the record is stored in the DynamoDB table, any further activity on the record is tracked within system_info map, keeping various timestamps, status info and queueing information.
Here is an example of the record’s system information, initially stored in the database:
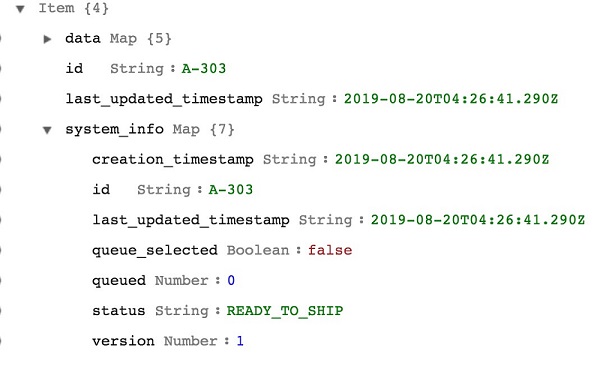
The main entity for modeling a queueing behavior is a ‘queued’ attribute. And corresponding GSI, named queued-last_updated_timestamp-index.

This post uses a sparse index. Only records that have the queued attribute appear in the index. To sort the records, this post uses last_updated_timestamp, which creates a priority queue based on an item’s timestamp. You can choose to sort in ascending or descending order. Depending on your business case, you can add any other attribute to implement your own priority mechanism. For more information, see Take Advantage of Sparse Indexes.
Adding or removing the queued attribute either adds or removes the item from the GSI, which either adds or removes it from the queue. In this post, you only need to place a small number of records from the large table into the queue, so implementing the solution is efficient.
When processing is complete, the item leaves the queue but stays in the table.
This post uses DynamoDB’s update expression with the help of optimistic locking, which checks the version’s number before and during a record’s update. For more information, see Update Expressions and Optimistic Locking with Version Number.
Shipment object lifecycle
The solution follows a specific lifecycle; however, you can apply its general principles to many use cases.
While waiting for all the shipment items to be available, the shipment object is in anUNDER_CONSTRUCTION state. The object joins the queue when its status changes to READY_TO_SHIP. After the record is retrieved from the queue by the consumer, using peek() method, the record status changes to PROCESSING_SHIPMENT. When the status changes to COMPLETED, the record leaves the queue.
In the case of processing failure, the record rejoins the queue and is ready to be peeked at for reprocessing. The object returns to the state READY_TO_SHIP. If multiple failures occur, the record moves from this queue to the dead-letter queue (DLQ) for inspection. Its state changes IN_DLQ. If the record is fixed, the restore process returns it to the queue for processing.
Your implementation might not use any states to track the object’s lifecycle, except the queuing attributes.
The following diagram shows the steps of this lifecycle:

Coding language for this solution
You use any coding language that supports the AWK SDK and APIs for DynamoDB. This post uses Java 8.
For Java developers, there is additional value in the code that you can use for your next project. This is not a production-ready code, but rather an excellent first step in your journey. This post presents both high-level APIs, such as Java’s DynamoDBMapper, as well as lower-level APIs, found in Java AWS SDK, such as DynamoDB and AmazonDynamoDB.
Implementing the solution
Storing and getting data from DynamoDB by partition key is a basic action that this post doesn’t focus too much on. The relevant information is that the queued attribute is not initially present in the record. When the attribute is present, the record qualifies for queue placement. Additionally, when a record initially arrives in the database, the version attribute value is set to 1. This attribute is relevant for optimistic locking, which makes sure that no other consumers are updating the record while you are making updates.
There are a few general practices in the code:
- The assumption that there is a reasonable number of records in the queue at any time. For more information, see Best Practices for Designing and Using Partition Keys Effectively.
- Queries use the default setting
scanIndexForward = true, which prioritizes the oldest record first in the query list. Depending on your priority and ordering needs, you might need to change this parameter to false, for example, when sorting the records by highest score. - It is better to remove the unneeded attribute with REMOVE update expression than to keep the attribute that would be never used again
- Duplicate attributes that group system attributes together and satisfy the requirement that partition and sort keys have top-level attributes. For example,
SET last_updated_timestamp = :lut, #sys.last_updated_timestamp = :lut. - Name placeholders for your update expression avoid conflicts with reserved names. For example,
#vfor the version or#stfor a status attribute. - Attributes projection improves the efficiency of your DynamoDB query returns. You don’t need to return application data when only handling system attributes.
- The main table acts both as database records holder as well as queue persistence. If your microservice architecture prefers stricter separation of concerns, you can create another table dedicated to the queuing needs.
- Shipment statuses track when a shipment is not yet constructed, ready to ship, in processing, and finally completed or failed.
- A feature to delay consumers from peeking at the messages. While not covered in this post, this is useful if you want to implement an exponential backoff, in which you delay processing a failed message incrementally over time. This is a sound approach if the downstream system is temporarily unavailable.
Queue methods
The following code excerpts are from the QueueSdkClient.java.
enqueue(ID)
Enqueuing is an operation that marks the record as it joins the queue. No real movement occurs, only the attrition of a queued attribute. For this solution, you can only place ready-to-ship records in the queue.
The following is the code to update the record:
In the preceding code example, you can see the essential elements when deciding to place the record in the queue. SET #q = :one creates the queued attribute at the root of your record. You cannot nest the partition and sort key attributes for the GSI; they need to be top-level attributes. The attribute type allowed for the GSI’s partition key can be String, Numeric, or Binary. This post uses the Numeric value with an integer value of 1. Using an integer value greater than zero, provides an opportunity to support multiple queue types for the same application, such as a regular queue, in-flight records queue, and DLQ.

Additionally, the code updates the timestamp of when the last record updated and joined the queue. All timestamp values are a string representation of the UTC timestamp. This string provides a sorting property automatically.
This solution uses a condition expression to make sure that the record hasn’t changed since the last time you saw it. Any nested attribute uses dereference operator.
If the record updates successfully, the queued attribute has a value of 1 and the version attribute increases by 1. This solution does some additional reads to construct the returning shipment object easily. You can optimize this as the update API call returns the new record.
If you are using Java’s DynamoDBMapper API for updates, optimistic locking is built in. You only need to annotate your version attribute with @DynamoDBVersionAttribute.
peek()
The peek() method retrieves the item from the queue that meets your specified priority. This post sorts by latest timestamp. The default setting scanIndexForward = true places the older record at the head of your priority queue. See the following code example:
After you retrieve the records that have a queued attribute value at 1, iterate over the records, looking for the first item that is eligible for processing. There are two scenarios in which this could be true: the record visibility timeout is reached, and therefore it is eligible for retrieval, and the record is not yet marked for processing.
Once you determine the record ID, update the record’s attributes that manage queuing. See the following code example:
The system_info.queue_selected attribute has the Boolean value true. This attribute denotes that the record is retrieved from the queue and it is in the processing stage. During message processing, the record is invisible to other consumers. If for any reason application processing doesn’t complete during the duration of the visibility timeout value, the underlying queuing peek() logic makes it visible again, for any other consumer to peek at the queue.
Similarly, the dequeue() method gives the record to the consumer and removes the record from the queue immediately, regardless of if the processing was successful or not. For this reason, you should always use peek() method instead of dequeue().
If the record updates successfully, the queued and queue_selected attributes have a value of 1 and the version attribute increases by 1. The timestamp of the peek() operation is stored. For this post, the status of the shipment record changes to StatusEnum.PROCESSING_SHIPMENT.
The implementation in this post makes sure that no other consumer can accidentally peek at the same record. If no records are found in the queue, the returning PeekResult object denotes a failed operation and the reference to the shipment object is null.
Example of the system_info for the record that is retrieved (peek) is as follows:

Once the consumer retrieves the record, it is their responsibility to process the record and to call one of the SDK methods to flag if the record is properly processed or if the process has failed.
An example of the successful processed record:

As you can see from the screen shot above, status attribute has value COMPLETED. The attribute denoting queue belonging, is set to 0, and it is removed from the root of the object. Further, system_info.queue_selected is set to false, indicating that the message is not anymore in processing mode. No further actions will be allowed for this record.
remove(ID)
Queue item removal is a simple operation that removes the queued attribute from the record and sets the queue_selected attribute to 0. See the following code example:
In the above implementation, we have decided to remove the record from the queue regardless if it is still in processing or not. You can add additional logic to restrict removal if the record is in processing and the invisible timeout is still active.
restore(ID)
This method is similar to enqueue() but works for items already in the queue and selected for the processing. This method is useful when consumers encounter issues with the downstream system and abort processing, thereby returning the message to the end of the queue. See the following code example:
The preceding code removes system_info.queue_selected and DLQ, regardless of if those attributes exist. You can use this function to move a fixed record from the DLQ back to the regular queue.
You can also modify the duration of time that the record is invisible for any processing.
touch(ID)
This is a simple method that updates the last_updated_timestamp attribute with the latest timestamp value. When you touch() a record waiting in the queue, it sends the record to the back of the queue, because your GSI index has this attribute as a sort key. See the following code example:
As with other methods, this code increases the record’s version number by an increment of 1.
You can create a similar method to update your record’s priority. As long as your GSI sorts by priority attribute, it moves the record to its new priority position. With a little creativity, you can use composite sort keys to sort your records by both priority and timestamp.
sendToDLQ(ID)
When there is an issue in processing records, for example, detecting a record with invalid data that would cause issues downstream, you need to take the record off the queue for corrective action. This method is similar to enqueue(), in which you create a new queued attribute that causes the GSI index to recognize the record and show it in its index. See the following code example:
The following screenshot shows a Shipment record that failed to process and went to the DLQ for fixing. As you can see, the number of attributes in the system_info has increased over time, as the record goes through various state changes.

Once the record is fixed, you can use the restore(ID) call to remove the DLQ attribute and place the record back in the queue.
Checking the state of the queue
You can use a query to check the state of your queue. See the following code example:
Accessing the solution GitHub repo
The project code is far richer in content than what this post covers. For more information, see this post’s GitHub repo. To experiment with the demo, download the project. To build, deploy, and run the demos, you’ll need a valid AWS account, Java 8+, and AWS CLI. For builders, the repo provides pom.xml.
The instructions from the README.md file explain how to build and deploy the AWS services for this project. After this is completed, you can use the project provided CLI implementation to experiment with the queuing solution.
Improvements
You can stream any changes in DynamoDB to create an event-driven solution. Those changes trigger a Lambda function that can do any type of processing. Depending on your needs, you can update metric values in DynamoDB (in another table) or store Change Data Capture (CDC) in S3 for further analytics. For more information, see Capturing Table Activity with DynamoDB Streams.
If you use any of these ideas for your production implementation, make sure to use proper exception handling. If you miss this step, the behavior of the system can be unpredictable or break the processing flow. For example, if you use peek() but never properly handle an exception, the record reappears for processing constantly. In this example, use the sendToDLQ() method in the queuing SDK.
The solution in this post handles many features and functionalities found in dedicated queuing solutions. One of those is a guarantee of a single delivery as well as ordering. If you need to block other consumers from removing records from the queue, you can use the peek() method. The peek() iterates from the head of the queue; if any other record has system_info.queue_selected set to 1, it returns a null object, because there are no eligible records.
Summary
This post discussed the versatility of DynamoDB. It covered modeling a DynamoDB table, advanced GSI use, using a sparse index for efficient data processing, plus programming tips and tricks with DynamoDB attributes. The post also provided all the code for you to start your next project. Depending on the programming language you use, you can alter the code to suit your needs and abstract queuing SDK for any type of table or record. With some of the discussed design concepts, you can add advanced features to your solution without needing to introduce new components to the architecture.
About the Author

Zoran Ivanovic is a Big Data Principal Consultant with AWS Professional Services in Canada. After 5 years of experience leading one of the largest big data teams in Amazon, he moved to AWS to share his experience with larger enterprise customers who are interested in leveraging AWS services to build their mission-critical systems in the cloud.