AWS Cloud Operations Blog
Viewing Amazon CloudWatch metrics with Amazon Managed Service for Prometheus and Amazon Managed Grafana
Monitoring AWS services comprising of a customer workload with Amazon CloudWatch is important for resiliency of a workload. Customers can bring their CloudWatch data alongside their existing Prometheus data sources to improve their ability to join or query across for a holistic view of their systems. The Amazon Managed Service for Prometheus is a serverless monitoring service for metrics compatible with open-source Prometheus. Amazon Managed Grafana is a fully managed service with rich, interactive data visualizations to help customers analyze, monitor, and alarm on metrics, logs, and traces across multiple data sources.
Typically, an application deployment depends on external resources for provision infrastructure components, such as Elastic Load Balancing (ELB). The metrics from these components are collected in CloudWatch. For the overall visibility into the performance of an application, metrics for these external resources must be analysed. This post describes how customers and partners can ingest CloudWatch metrics for AWS Application Load Balancer (ALB) with Amazon Managed Service for Prometheus and visualize the same with Amazon Managed Grafana.
Using Amazon Managed Service for Prometheus helps ingest metrics with a single query language and options to rewrite, replace, or include only some of the metrics. Note that Amazon Managed Grafana supports CloudWatch as a data source. Therefore, when designing a monitoring solution, you must decide between using Amazon Managed Grafana only to save costs. Or, add Amazon Managed Service for Prometheus for metrics manipulation.
| Time to read | 6 minutes |
| Time to complete | 15 minutes |
| Cost to complete (estimated) | $30 (at publication time) |
| Learning level | Intermediate (200) |
| Services used |
Amazon Elastic Compute Cloud (Amazon EC2) |
Solution overview
As shown in the following figure, this post will use three Amazon Elastic Compute Cloud (Amazon EC2) instances in three different Availability Zones, where two instances will be behind an ALB with metrics getting published to CloudWatch. The third EC2 instance will run yet-another-cloudwatch-exporter (yace) to make CloudWatch metrics available in the Prometheus format. These metrics are scraped using AWS Distro for OpenTelemetry (ADOT) collector and written remotely in to Amazon Managed Service for Prometheus. The ADOT collector will run on the third EC2 instance.
Note that yace is an open-source project that is not maintained by AWS. This post utilizes this open-source project as is. It’s highly recommended that you consider using this tooling and perform necessary security and performance validations before deploying to your environment.
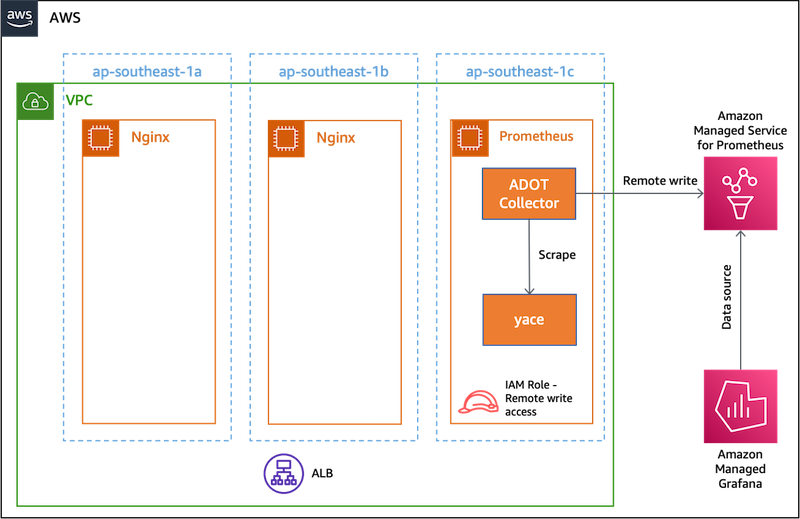
Figure 1 Flow for CloudWatch metrics into Amazon Managed Service for Prometheus and Amazon Managed Grafana
The EC2 instance that runs the ADOT Collector will be configured with an AWS Identity and Access Management (IAM) Role that has the AmazonPrometheusRemoteWriteAccess policy. This policy enables you to remotely write metrics to Amazon Managed Service for Prometheus workspace. The Amazon Managed Grafana workspace is configured to use the Amazon Managed Service for Prometheus as the data source. The Amazon Managed Grafana workspace will have dashboards to display the metrics.
Walkthrough
Following is the overview of the solution to be implemented in this demonstration:
- Install
Nginxon EC2 instances. - Create and configure ALB.
- Install
yaceon the third EC2 instance. - Create the Amazon Managed Service for Prometheus workspace.
- Install ADOT Collector on the third EC2 instance.
- Configure ADOT collector to remote write metrics to Amazon Managed Service for Prometheus workspace.
- Launch the Amazon Managed Grafana workspace.
- Launch the dashboard in Amazon Managed Grafana by importing an existing dashboard as JSON to view metrics.
Prerequisites
You will need the following to complete the steps in this post:
- An AWS account
- Create EC2 instance with Ubuntu Linux distribution. You should create three such instances in three different availability zones of the default VPC. Name the first two of these EC2 instances with nginx-1 and nginx-2 respectively. The third one may be named prometheus.
- AWS Command Line Interface (AWS CLI) installed on your local environment.
- hey tool installed on your local environment.
Install Nginx
Select the EC2 instances named nginx-1 and nginx-2 respectively. Follow these instructions to install Nginx:
- Connect to your Linux instance using Session Manager.
- Run the following commands:
Create and configure ALB
On your local environment, run the following commands to create an ALB with a target group pointing to the Nginx instances:
Configure Nginx instances to receive traffic from ALB
Run the following commands to configure Nginx on EC2 instances to receive traffic from ALB. These commands should be run from the same shell where you ran the the previous set of commands for creating ALB:
Download yace
The GitHub project for yace has numerous binaries in its release page. Since this post uses Ubuntu as the operating system, the x86_64 binary will be used. Select the EC2 instance named prometheus and run the following commands:
- Connect to your Linux instance using Session Manager.
- Run the following commands:
Configure yace
- Copy the following configuration into yace-config.yaml
- Change the following in the configuration file appropriately:
-
- regions: For this post, since only one ALB must be monitored, enter one value for the region where the ALB is being run. This file uses ap-southeast-1 as an example.
- dimensions.value: This is the last portion of the ALB ARN.
For complete details on the configuration file, see the GitHub page.
Launch yace
- Launch yace with the following command to scrape Amazon CloudWatch metrics every 10 seconds and expose a Prometheus metrics end-point at port 9102.
