Amazon Web Services ブログ
低コストで高性能な生成系 AI 推論用の Amazon EC2 Inf2 インスタンスが一般公開されました
深層学習 (DL) のイノベーション、特に大規模言語モデル (LLM) の急速な成長は、業界を席巻しました。DL モデルのパラメータ数は数百万から数十億に増え、画期的な新機能を実証しています。それらは、生成系 AI などの新たなアプロケーションや、ヘルスケアやライフサイエンスにおける高度な研究を促進しています。AWS は、チップ、サーバー、データセンターの接続、ソフトウェアにわたる革新を進め、このような DL ワークロードを大規模に高速化してきました。
AWS re:Invent 2022 において、AWS が設計した最新の ML チップである AWS Inferentia2 を搭載した Amazon EC2 Inf2 インスタンスのプレビューを発表しました。Inf2 インスタンスは、高性能な DL 推論アプリケーションをグローバル規模で実行するように設計されています。これらは、GPT-J や Open Pre-Trained Transformer (OPT) 言語モデルなど、 AI の最新のイノベーションをデプロイするための Amazon EC2 で最も費用対効果が高くエネルギー効率の高いオプションです。
4月13日、Amazon EC2 Inf2 インスタンスの一般提供を開始したことをお知らせします!
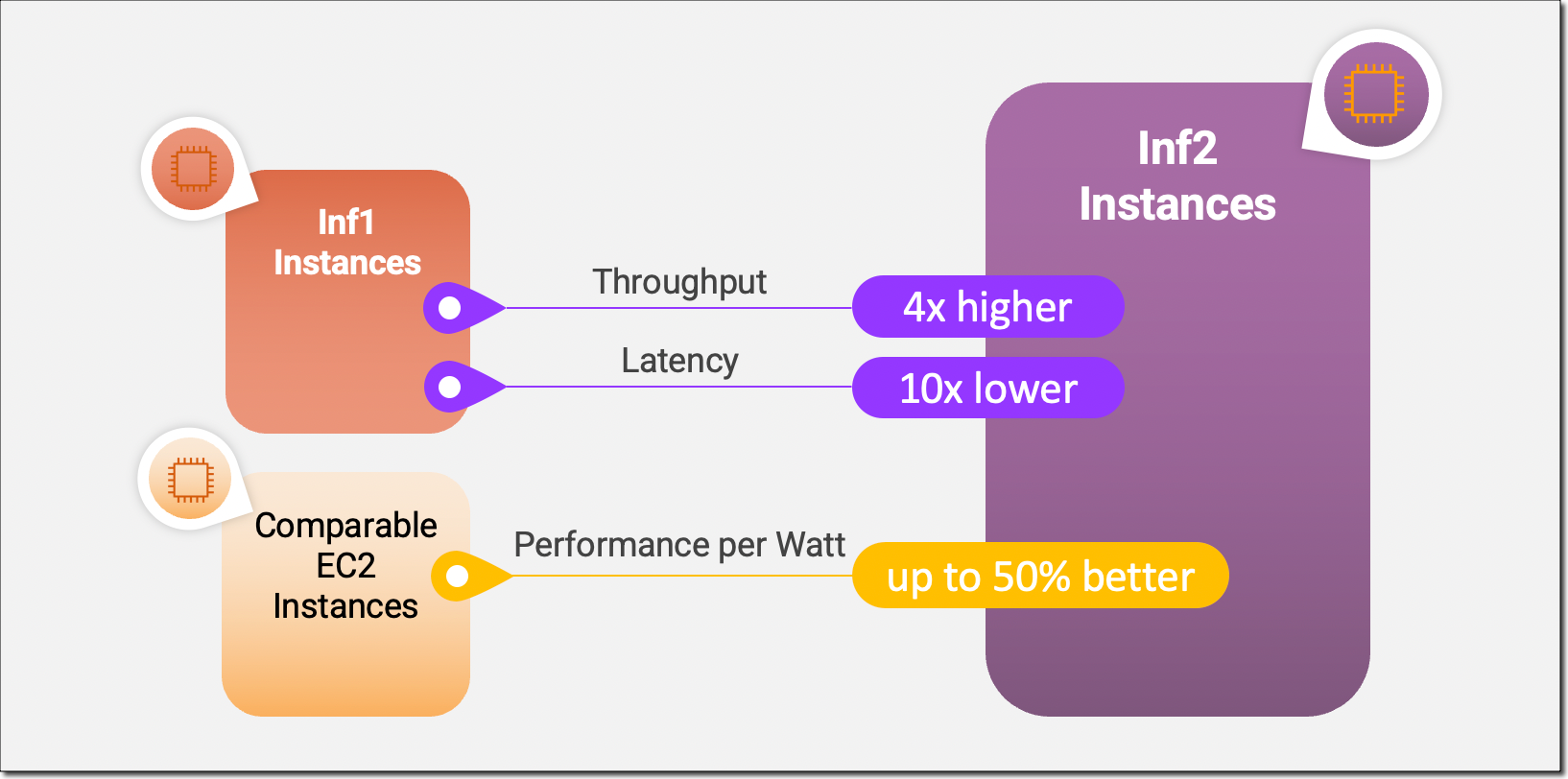
Inf2 インスタンスは、Amazon EC2 初の推論最適化インスタンスで、アクセラレータ間の超高速接続によるスケールアウト分散推論をサポートします。Inf2 インスタンス上の複数のアクセラレータにわたって、数千億のパラメータを持つモデルを効率的にデプロイできるようになりました。Amazon EC2 Inf1 インスタンスと比較して、Inf2 インスタンスはスループットが最大 4 倍高く、レイテンシーが最大 10 倍低くなります。以下は、新しい Inf2 インスタンスで実現した主なパフォーマンスの向上について説明したインフォグラフィックです。
新しい Inf2 インスタンスのハイライト
Inf2 インスタンスは現在 4 つのサイズで利用可能で、最大 12 個の AWS Inferentia2 チップと 192 個の vCPU を搭載しています。BF16 または FP16 データタイプで合計 2.3 ペタフロップスの計算能力を発揮し、チップ間の超高速 NeuronLink 相互接続が特徴です。NeuronLink は、複数の Inferentia2 チップにわたって大規模なモデルをスケーリングし、通信のボトルネックを回避し、より高性能な推論を可能にします。
Inf2 インスタンスは最大 384 GB の共有アクセラレータメモリを提供し、各 Inferentia2 チップには 32 GB の高帯域幅メモリ (HBM) が搭載され、総メモリ帯域幅は 9.8 TB/s です。このタイプの帯域幅は、メモリが限られている大規模言語モデルの推論をサポートするために特に重要です。
基盤となる AWS Inferentia2 チップは DL ワークロード専用に設計されているため、Inf2 インスタンスは他の同等の Amazon EC2 インスタンスよりもワットあたりのパフォーマンスが最大 50% 向上します。AWS Inferentia2 のシリコンイノベーションについては、このブログ記事の後半で詳しく説明します。
次の表は、Inf2 インスタンスのサイズと仕様を詳細に示しています。
| インスタンス名
|
vCPU | AWS Inferentia2 チップ | アクセラレーターメモリ | NeuronLink | インスタンスメモリ | インスタンスネットワーク |
| inf2.xlarge | 4 | 1 | 32 GB | 該当なし | 16 GB | 最大 15 Gbps |
| inf2.8xlarge | 32 | 1 | 32 GB | 該当なし | 128 GB | 最大 25 Gbps |
| inf2.24xlarge | 96 | 6 | 192 GB | あり | 384 GB | 50 Gbps |
| inf2.48xlarge | 192 | 12 | 384 GB | あり | 768 GB | 100 Gbps |
AWS Inferentia2 イノベーション
AWS Trainium チップと同様に、各 AWS Inferentia2 チップには 2 つの改良された NeuronCore – v2 エンジン、HBM スタック、およびマルチアクセラレータ推論を実行するときの計算と通信の操作を並列化するための専用の集合計算エンジンが搭載されています。
各 NeuronCore – v2には、DL アルゴリズム専用のスカラー、ベクトル、テンソルエンジンが搭載されています。テンソルエンジンは行列演算に最適化されています。スカラーエンジンは、ReLU (整流線形単位) 関数などの要素単位の演算に最適化されています。ベクトルエンジンは、バッチ正規化やプーリングなど、要素単位ではないベクトル演算に最適化されています。
AWS Inferentia2 チップとサーバーハードウェアのその他のイノベーションについて簡単にまとめると、次のようになります。
- データ型 – AWS Inferentia2 は FP32、TF32、BF16、FP16、UINT8 などの幅広いデータ型をサポートしているため、ワークロードに最適なデータ型を選択できます。また、構成可能な新しい FP8 (cFP8) データ型もサポートしています。これは、モデルのメモリフットプリントと I/O 要件を減らすため、特に大規模モデルに適しています。以下の画像では、サポートするデータ型を比較しています。

- 動的実行、動的入力シェイプ – AWS Inferentia2 には、動的実行を可能にする汎用デジタル信号プロセッサ (DSP) が組み込まれており、制御フロー演算子をホスト上で展開、実行する必要はありません。AWS Inferentia2 は、テキストを処理するモデルなど、入力テンソルのサイズが不明なモデルにとって重要な動的入力シェイプもサポートしています。
- カスタム演算子 – AWS Inferentia2 は C++ で記述されたカスタム演算子をサポートしています。Neuron カスタム C++ 演算子は、NeuronCore 上でネイティブに実行される C++ カスタム演算子を記述できます。標準の PyTorch カスタム演算子プログラミングインターフェイスを使用して CPU カスタム演算子を Neuron に移行し、新しい実験的演算子を実装できます。これらはすべて NeuronCore ハードウェアに関する詳細な知識がなくても可能です。
- NeuronLink v2 – Inf2 インスタンスは、チップ間の直接超高速接続 (NeuronLink v2) による分散推論をサポートする、Amazon EC2 初の推論最適化インスタンスです。NeuronLink v2 は、all-reduce などの集団通信 (CC) 演算子を使用して、すべてのチップにわたって高性能な推論パイプラインを実行します。
以下の Inf2 分散推論ベンチマークでは、OPT – 30B と OPT – 66B モデルのスループットとコストが、推論に最適化された同等の Amazon EC2 インスタンスと比較して改善されていることが示されています。

それでは、Amazon EC2 Inf2 インスタンスの開始方法をご紹介します。
Inf2 インスタンスの使用を開始する
AWS Neuron SDK は、AWS Inferentia2 を PyTorch などの一般的な機械学習 (ML) フレームワークに統合します。Neuron SDK にはコンパイラー、ランタイム、プロファイリングツールが含まれており、新機能やパフォーマンスの最適化により常に更新されています。
この例では、利用可能な PyTorch Neuron パッケージを使用して、Hugging Face の事前トレーニング済みの BERT モデルを EC2 Inf2 インスタンスにコンパイルしてデプロイします。 PyTorch Neuron は PyTorch XLA ソフトウェアパッケージをベースにしており、PyTorch の演算を AWS Inferentia2 命令に変換することができます。
Inf2 インスタンスに SSH 接続し、PyTorch Neuron パッケージを含む Python 仮想環境をアクティブ化します。Neuron が提供する AMI を使用している場合は、次のコマンドを実行してプレインストール環境をアクティブ化できます。
source aws_neuron_venv_pytorch_p37/bin/activateこれで、コードを少し変更するだけで、PyTorch モデルを AWS Neuron に最適化された TorchScript にコンパイルできます。まず、torch、PyTorch Neuron パッケージの torch_neuronx、および Hugging Face のトランスフォーマーライブラリをインポートすることから始めましょう。
torch をインポート
torch_neuronx をインポート トランスフォーマーから AutoTokenizer、AutoModelForSequenceClassification をインポート
トランスフォーマーをインポート
...次に、トークナイザーとモデルを構築しましょう。
name = "bert-base-cased-finetuned-mrpc"
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForSequenceClassification.from_pretrained(name, torchscript=True)入力例を使用してモデルをテストできます。モデルは入力として 2 つの文章を想定しており、それらの文が互いに言い換えられるかどうかを出力します。
def encode(tokenizer, *inputs, max_length=128, batch_size=1):
tokens = tokenizer.encode_plus(
*inputs,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors="pt"
)
return (
torch.repeat_interleave(tokens['input_ids'], batch_size, 0),
torch.repeat_interleave(tokens['attention_mask'], batch_size, 0),
torch.repeat_interleave(tokens['token_type_ids'], batch_size, 0),
)
# 入力例
sequence_0 = 「Hugging Face はニューヨーク市に拠点を置いています」
sequence_1 = 「りんごは健康に特に悪いです」
sequence_2 = 「Hugging Face の本社はマンハッタンにあります」
paraphrase = encode(tokenizer, sequence_0, sequence_2)
not_paraphrase = encode(tokenizer, sequence_0, sequence_1)
# サンプルで元の PyTorch モデルを実行する
paraphrase_reference_logits = model(*paraphrase)[0]
not_paraphrase_reference_logits = model(*not_paraphrase)[0]
print('Paraphrase Reference Logits: ', paraphrase_reference_logits.detach().numpy())
print('Not-Paraphrase Reference Logits:', not_paraphrase_reference_logits.detach().numpy())出力は次のようになります。
Paraphrase Reference Logits: [[-0.34945598 1.9003887 ]]
Not-Paraphrase Reference Logits: [[ 0.5386365 -2.2197142]]これで、torch_neuronx.trace () メソッドはオペレーションをニューロンコンパイラー (neuron-cc) に送ってコンパイルし、コンパイルされたアーティファクトを TorchScript グラフに埋め込むようになりました。このメソッドは、モデルとサンプル入力のタプルを引数として受け取ります。
neuron_model = torch_neuronx.trace(model, paraphrase)Neuron でコンパイルされたモデルを、入力例を使ってテストしてみましょう。
paraphrase_neuron_logits = neuron_model(*paraphrase)[0]
not_paraphrase_neuron_logits = neuron_model (*not_paraphrase) [0]
print('Paraphrase Neuron Logits: ', paraphrase_neuron_logits.detach().numpy())
print('Not-Paraphrase Neuron Logits: ', not_paraphrase_neuron_logits.detach().numpy())出力は次のようになります。
Paraphrase Neuron Logits: [[-0.34915772 1.8981738 ]]
Not-Paraphrase Neuron Logits: [[ 0.5374032 -2.2180378]]これで完了です。わずか数行のコード変更で、Amazon EC2 Inf2 インスタンスで PyTorch モデルをコンパイルして実行しました。どの DL モデルアーキテクチャが AWS Inferentia2 に適しているか、および現在のモデルサポートマトリックスについて詳しくは、AWS Neuron ドキュメントをご覧ください。
今すぐ利用可能
Inf2 インスタンスは、AWS 米国東部 (オハイオ)、米国東部 (バージニア北部) リージョンで、オンデマンド、リザーブド、スポットインスタンス、または Savings Plan の一部として、今すぐ起動できます。Amazon EC2 でいつも支払うのと同じように、使用した分の料金のみをお支払いいただきます。詳細については、「Amazon EC2 の料金」を参照してください。
Inf2 インスタンスは AWS 深層学習 AMI を使用してデプロイでき、コンテナイメージは Amazon SageMaker、Amazon Elastic Kubernetes Service (Amazon EKS)、Amazon Elastic Container Service (Amazon ECS)、AWS ParallelCluster などのマネージドサービスを介して利用できます。
詳細については、Amazon EC2 Inf2 インスタンスページにアクセスしてください。また、EC2 の AWS re:Post、または通常の AWS サポートの担当者までフィードバックをぜひお寄せください。
– Antje
原文はこちらです。