Amazon Web Services ブログ
Category: Compute
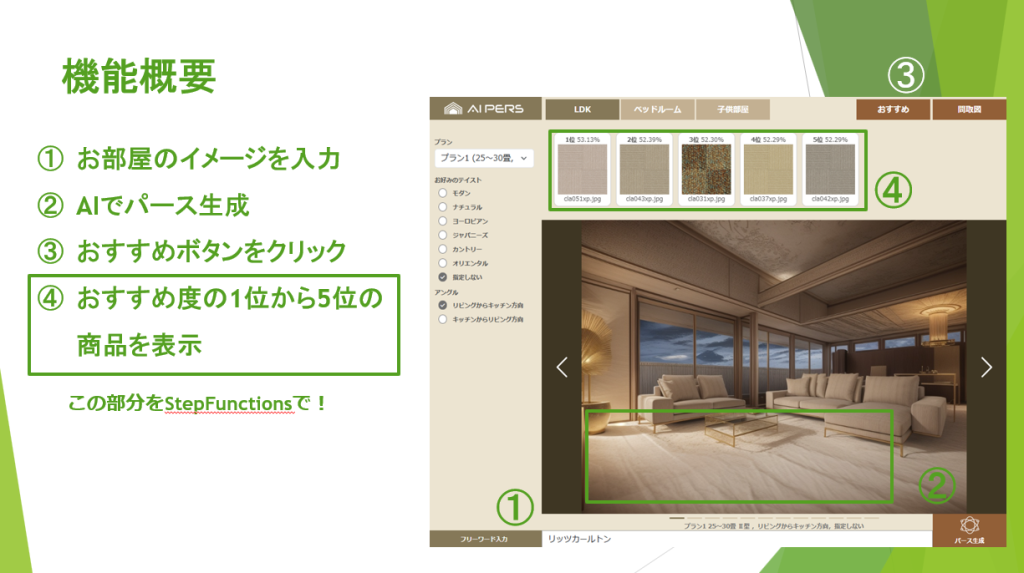
株式会社ファイン様のAWS 生成AI活用事例:建築AIパース生成サービスにレコメンドAI機能を実装。担当者の商品検索時間を75%削減し、顧客満足度も向上。
本ブログは株式会社ファイン様と Amazon Web Services Japan 合同会社が共同で執筆いたし […]
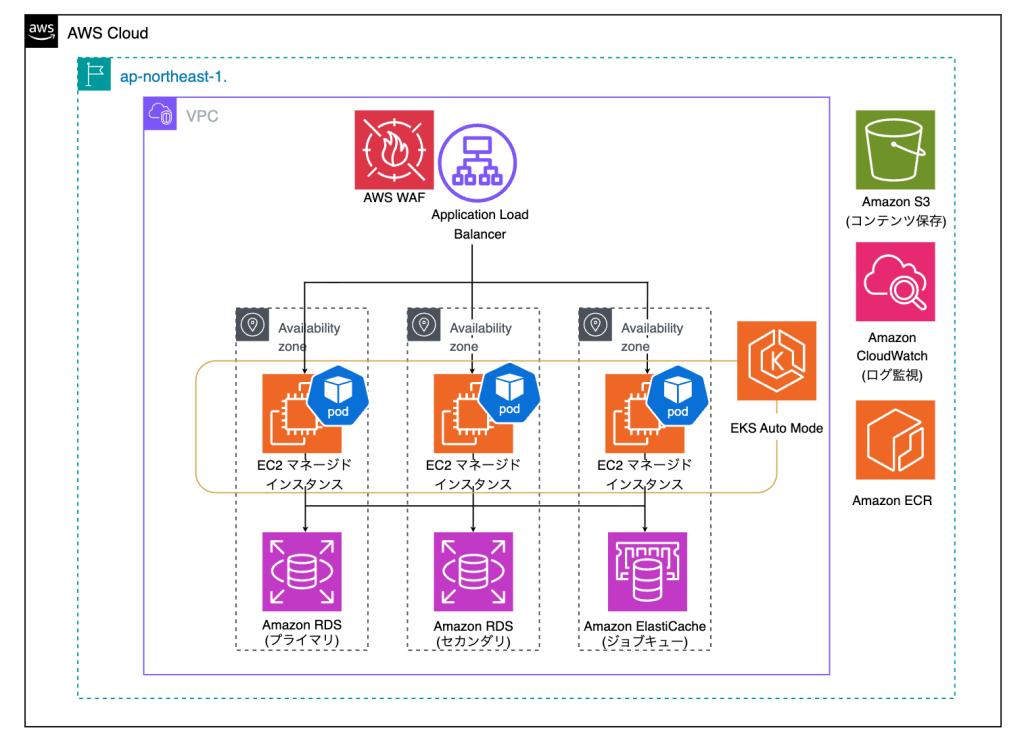
株式会社ギフティ様「giftee Reward Suite」における Amazon EKS Auto Mode の導入事例のご紹介
株式会社ギフティは「giftee Reward Suite」というキャンペーン基盤サービスを提供しており、本稿ではそのインフラ構築事例を紹介しました。同社は Amazon EKS Auto Mode を採用することで、Kubernetes クラスタ管理の簡素化、ノード管理の効率化、セキュリティの向上などの効果が挙げられ、導入当時の検討と課題も併せてご紹介します。
Amazon EC2 Capacity Manager を使用して単一のインターフェイスからキャパシティ使用量を監視、分析、管理
10 月 16 日、Amazon EC2 Capacity Manager を発表いたしました。Amazon […]

Amazon GameLift Servers でローンチを成功させるためのステップ:開発フェーズ
私たちはグローバルなゲームサーバーホスティングのためのフルマネージド型サービスである Amazon GameLift Servers をお勧めしています。このサービスは、オーケストレーション、グローバルなセッション配置、ゲームセッションライフサイクル管理を担うため、マルチプレイヤーゲームのローンチにおける運用作業とストレスを軽減するのに役立ちます。
このブログシリーズでは、ゲームローンチを成功させるための準備の重要な考慮事項について説明します。この最初のブログはプリプロダクションで実行すべきアクションに焦点を当て、第 2 部はプリローンチ準備 ( ローンチの 2〜3 ヶ月前 ) に焦点を当てます。これらの推奨事項は、開発初期のインテグレーションからゲームローンチまで数百のゲームスタジオをサポートした経験に基づいています。

キャパシティの分割、移動、変更による Amazon EC2 オンデマンドキャパシティ予約の効率的な管理
Amazon EC2 オンデマンドキャパシティ予約(ODCR)は、任意の期間で特定のアベイラビリティーゾーンに Amazon EC2 インスタンスのコンピューティングキャパシティを予約できる機能です。
本ブログでは、キャパシティ予約の管理機能(分割、移動、変更)を使い、複数のチームやアカウントにまたがるキャパシティ予約の管理をより効率的にする方法を、シナリオを用いて解説します。

AWS Transform for VMware を使用して VMware ワークロードを移行およびモダナイズする
AWS Transform for VMware を発表しました。この革新的なサービスは、クラウド移行における長年の課題に正面から取り組み、AWS クラウドへの簡素化され効率的な移行の新たな時代を切り開きます。手作業を大幅に削減し、重要な VMware ワークロードの移行を加速することで、AWS Transform for VMware は、組織がクラウドへのアプローチを革新することを目指しています。

2025 年 9 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2025 年 9 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。

新しい汎用 Amazon EC2 M8a インスタンスが利用可能になりました
10 月 8 日は、汎用 M インスタンスファミリーに最近追加された Amazon Elastic Compu […]

新しいコンピューティング最適化 Amazon EC2 C8i および C8i-flex インスタンスのご紹介
Amazon Elastic Compute Cloud (Amazon EC2) メモリ最適化 R8i およ […]
Amazon Bedrockを活用したAWS サポート問い合わせ内容の自動集約ソリューションの実装
本稿は、JALデジタル株式会社システムマネジメント本部ハイブリッドクラウド基盤部クラウド基盤運営グループの梅本 […]