Amazon Web Services ブログ
Category: Compute

AWS Weekly Roundup: Amazon Bedrock、AWS Outposts、Amazon ECS マネージドインスタンス、AWS ビルダー ID など (2025 年 10 月 6 日)
9 月 29 日週、SWE-Bench によって世界最高のコーディングモデルと評価されている Anthropi […]

コンテナ化されたアプリケーション用の Amazon ECS マネージドインスタンスの発表
9 月 30 日、Amazon ECS マネージドインスタンスを発表しました。これは Amazon Elast […]

【自動車業界】SDV時代の車載ソフトウエア開発を支えるAWSソリューション(Vector SDV Symposium Japan 2025で発表)
はじめに みなさんこんにちは、ソリューションアーキテクトの眞壽田(ますた)です。2025年9月18日に開催され […]

Dell および HPE との AWS Outposts サードパーティーストレージ統合の発表
画期的なパフォーマンスとスケーラビリティを備えた第 2 世代 AWS Outposts ラックを 4 月に発表 […]
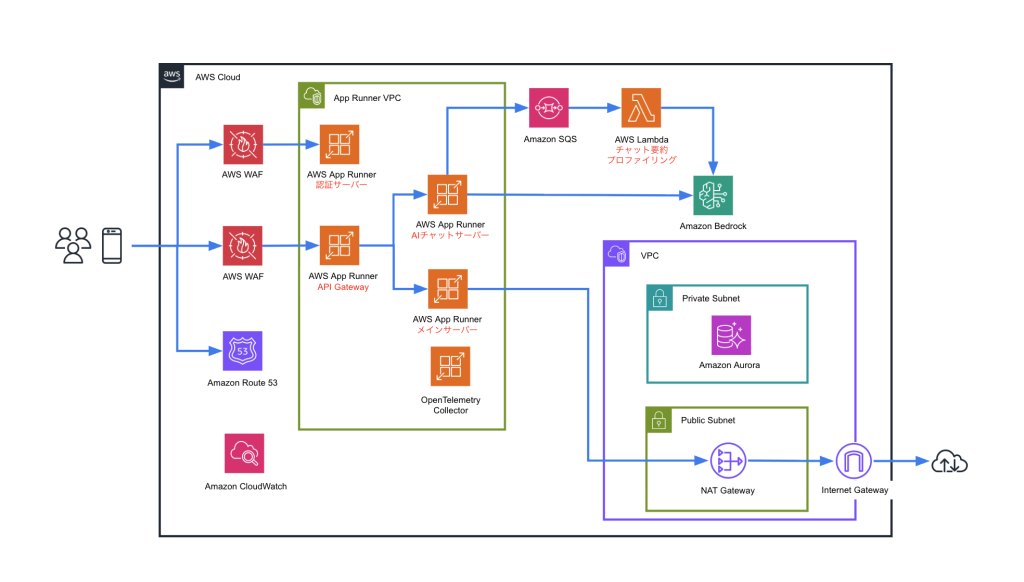
AWS Summit Japan 2025 AI健康アプリ「HugWay」を支えるAWSアーキテクチャ:テオリア・テクノロジーズの認知症プラットフォーム戦略
このブログは、テオリア・テクノロジーズ株式会社と、アマゾン ウェブ サービス ジャパン合同会社 ソリューション […]
AWS Parallel Computing Service (PCS)を利用したスケーラブルなクライオ電子顕微鏡データ解析環境
クライオ電子顕微鏡(Cryo-EM)は、創薬研究者が創薬に不可欠な生体分子の三次元構造を決定することを可能にし […]
成田空港におけるドーリー動態管理システム「DOLYS」をAWSに構築
はじめに 本稿は、日本航空株式会社デジタルEX企画部 空港オペレーショングループの橋本様よりご寄稿いただいた、 […]

AWS Weekly Roundup: Amazon Q Developer、AWS Step Functions、AWS Cloud Club Captain の締め切りなど (2025 年 9 月 22 日)
3 週間前、ニュージーランドの新しい AWS リージョン (ap-southeast-6) に関する記事を公開 […]

Amazon ECR の利用状況とセキュリティレポートを実装する
コンテナワークロードを管理する際、コンテナレジストリの一元的なオブザーバビリティを維持することはセキュリティと効率的なリソース利用のために不可欠です。Amazon Elastic Container Registry (ECR) は、イメージレベルとリポジトリレベルの両方でメトリクスを提供し、統合されたオブザーバビリティを構築する上で重要な役割を果たします。本記事では、これらのメトリクスをコスト内訳、利用状況メトリクス、セキュリティスキャン結果、および全リポジトリにわたるコンプライアンスステータスを含む、基本的で包括的なレポートに一元化する手順をご案内します。統合されたオブザーバビリティにより、利用パターンをより深く理解し、セキュリティリスクを特定し、セキュリティ要件と最適化のベストプラクティスに準拠させる必要があるリソースに優先順位を付けることが出来ます。
AWS は 2025 年 Gartner Magic Quadrant のクラウドネイティブアプリケーションプラットフォームとコンテナ管理の部門でリーダーに選出されました。
8 月、Amazon Web Services (AWS) は 2025年 Gartner Magic Qua […]