Amazon Web Services ブログ
Category: Advanced (300)

AWS Security Agent 徹底解説: 自動ペネトレーションテストのためのマルチエージェントアーキテクチャ
AWS Security Agent に組み込まれた自動ペネトレーションテストのマルチエージェントアーキテクチャについて解説します。従来は数週間を要していたペネトレーションテストを、専門化された AI エージェント群の連携により自動化し、認証処理、ベースラインスキャン、多段階探索、アサーションベースの検証までを一貫して実行します。単一の脆弱性検出にとどまらず、複数の脆弱性を組み合わせた複雑な連鎖攻撃の検出・検証まで実現する仕組みを紹介します。
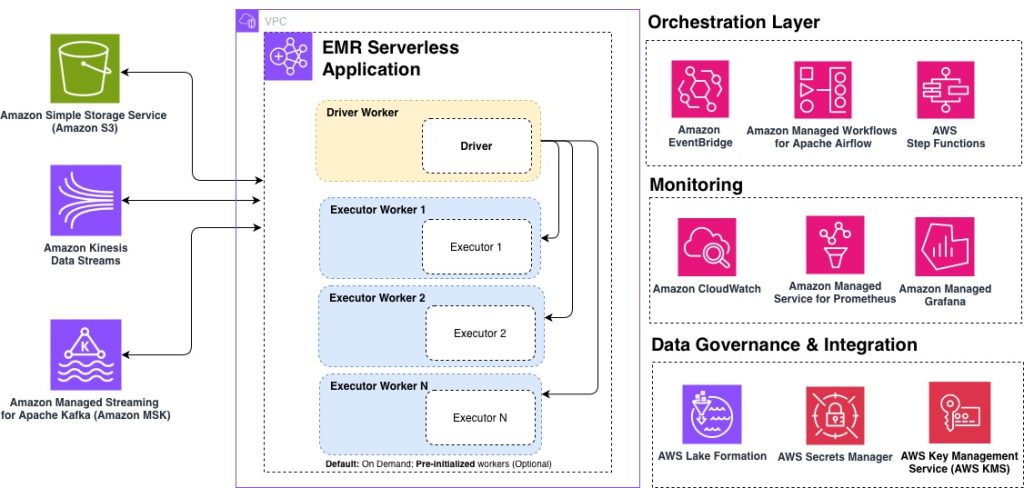
Amazon EMR Serverless のベストプラクティス 10 選
Amazon EMR Serverless のパフォーマンス、コスト、スケーラビリティを最適化するためのベストプラクティス 10 選を紹介します。アプリケーション設計、ワーカーの適正化、Graviton プロセッサの活用、ストレージ選択、マルチ AZ 構成など、効率的なデータ処理パイプラインの構築に役立つ実践的な推奨事項をまとめています。
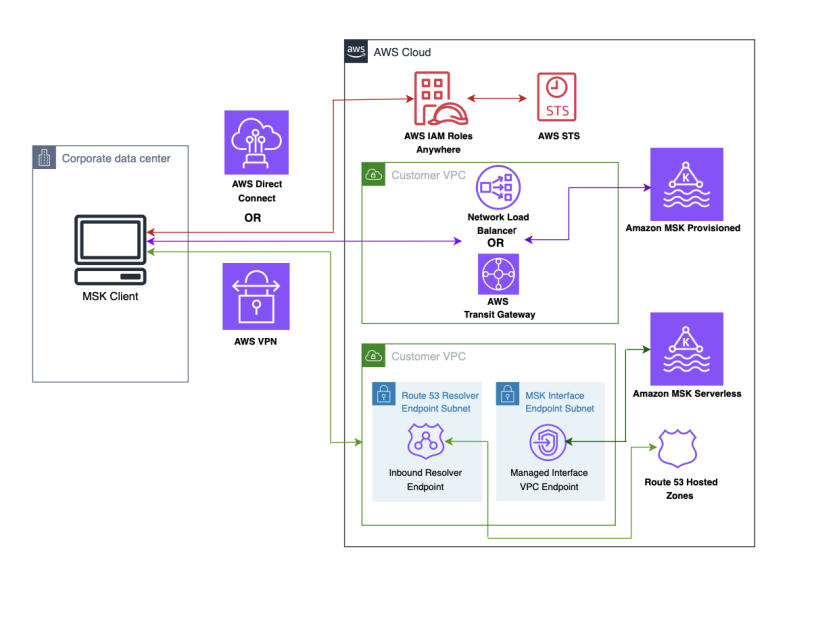
IAM Roles Anywhere を使用して AWS 外の Kafka クライアントから Amazon MSK にセキュアに接続する
本記事では、AWS IAM Roles Anywhere を使用して、AWS 外で動作する Kafka クライアントから Amazon MSK クラスターにセキュアに接続する方法を紹介します。X.509 証明書による一時的なセキュリティ認証情報の取得により、長期認証情報の管理が不要になり、セキュリティ体制を強化できます。

ブロックレベルレプリケーションを使用した Amazon RDS for SQL Server Web Edition の高可用性実装
この投稿では、SQL Server Web Edition の マルチ AZ RDS インスタンスをセットアップし、フェイルオーバーテストを通じてその高可用性機能を検証する方法を紹介します。

セルフマネージド Db2 on Linux データベースを Amazon RDS for Db2 にリストアする
本投稿は、 2025 年 10 月 21 日に公開された記事 「Restore self-managed Db […]

Amazon SageMaker でセルフサービス分析ソリューションを構築するリファレンスガイド
本記事では、Amazon SageMaker Catalog を使用して Amazon S3、Amazon Redshift、Snowflake など複数のデータソースからセルフサービス分析ソリューションを構築する方法を紹介します。小売ユースケースを例に、データの統合カタログ化、クロスソース分析、ビジネス用語集の作成、きめ細かなアクセス制御の設定手順を解説します。

Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析を実現した方法
Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析機能 Ask Amplitude を構築した過程を紹介します。PostgreSQL での総当たりコサイン類似度から pgvector による ANN 検索を経て、OpenSearch Service でのハイブリッド検索へと進化させ、アーキテクチャの簡素化、レイテンシーの削減、マルチテナント環境でのスケーラビリティ向上を実現しました。

CloudWatch アラームを使用した Amazon MSK の本番環境向けモニタリングの設定
本記事では、Amazon CloudWatch を使用した Amazon MSK クラスターの本番環境向けモニタリングの設定方法を解説します。ブローカーの健全性、リソース使用率、コンシューマーラグなどの主要メトリクスのカテゴリ分類と、推奨される CloudWatch アラームのしきい値を紹介し、ストリーミングワークロードの問題を早期に検知するためのプラクティスを説明します。

S3 Tables の Intelligent-Tiering でデータ管理を最適化する
Amazon S3 Tables の Intelligent-Tiering ストレージクラスを、コンパクションやスナップショット管理などのメンテナンス機能と組み合わせて、データレイクの長期的な総所有コスト (TCO) を削減する方法を解説します。

アプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する
Amazon SageMaker Catalog を使用してデータメッシュパターンを実装する方法を説明します。既存のアプリケーションやデータリポジトリを変更せずに、Amazon SageMaker Unified Studio でデータをオンボード、公開、サブスクライブする手順を紹介します。