Amazon Web Services ブログ
MLaaS (Machine Learning as a Service) のためのマルチテナント機械学習構築環境を Amazon SageMaker Pipelines で実装する
このブログは “Implementing a Multi-Tenant MLaaS Build Environment with Amazon SageMaker Pipelines” を翻訳したものです
本投稿は、AWS の Sr. Solutions Architect である Mehran Najafi, PhD と Michael Pelts により寄稿されました。
近年、自社で保有するデータだけでなく、外部や第三者のデータを使って機械学習 (ML) モデルを構築する企業が増えています。そしてトレーニングされたモデルを外部の顧客に提供することを収益源とするビジネスモデルを構築することができます。
アマゾン ウェブ サービス (AWS) 上で顧客固有の ML モデルをホストするパートナー企業は、固有のテナント分離とパフォーマンス要件を持っているため、スケーラブルで高性能かつ機能豊富な ML プラットフォームを提供するソリューションが必要です。
このプラットフォームは、マルチテナント型の Machine Learning as a Service (MLaaS) アプリケーションの構築、テスト、実行を容易にするものである必要があります。そうして構築された ML サービスは、AWS Marketplace で Software as a Service (SaaS) として AWS 利用者に提供することができます。
この記事では、Amazon SageMaker Pipelines が、SaaS アプリケーションにおけるデータの前処理、そして機械学習モデルの構築、トレーニング、チューニング、登録にどのように役立つかを紹介します。特にテナント分離とコスト配分に焦点を当て、テナント固有の ML モデルを構築するためのベストプラクティスを紹介します。
マルチテナント環境での ML モデル
MLaaS 環境では、SaaS サービスが個々の顧客(テナント)の ML モデルをホスト、管理、実行します。各テナントは,データのクリーンアップや前処理, ML モデルのトレーニング,リアルタイム予測のための推論エンドポイント,ビッグデータ解析のためのバッチ処理ジョブサービス,データの可視化,その他の ML サービスを提供する場合があります。
MLaaS ベンダーの中には、顔認識、感情分析、音声合成、リアルタイム翻訳などの一般的なユースケースのために事前にトレーニングされた ML モデルを提供するものもあります。通常、これらのモデルは、テナントの分離やコスト配分を考慮する必要のない「テナントレス」環境でトレーニングされます。
一方、売上予測、解約予測、不正検出やその他多くのユースケースは、テナント固有のデータに大きく依存しています。テナントが異なれば、トレーニングデータの構造も統計的性質も大きく異なる可能性があります。
このような場合、MLaaS ベンダーは、テナントデータとモデルを別々にトレーニング・管理する仕組みを提供する必要があります。この場合、テナントは独自のデータを持ち込みますが、ベンダーが提供する同じアルゴリズムを活用することになります。
テナント専用 ML モデルの構築
下図は、MLaaS 構築環境のサンプルとして、テナント別 ML モデル構築に必要な典型的なステップを含むワークフローのハイレベルなコンセプトを描いたものです。
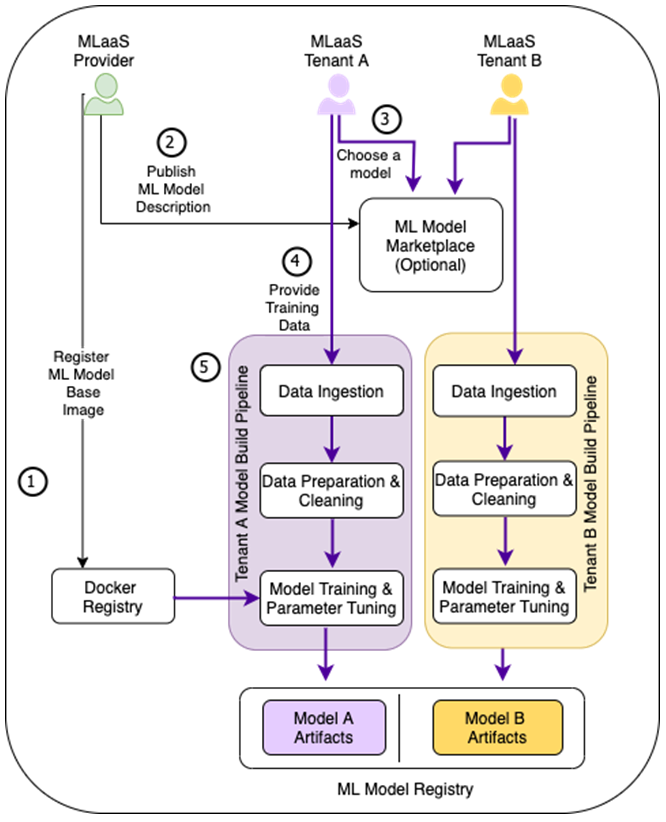
図1 – テナント別のトレーニングデータに基づいて、同じ ML ベースモデルの異なるインスタンスがテナント別にトレーニングされる。
- MLaaS プロバイダは、Docker レジストリに対象の ML フレームワークを含んだ顧客用のトレーニングコンテナを作成し登録します。このステップは、事前に作成されたトレーニング用 Docker イメージのカスタマイズが必要な場合にのみ必要です。テナントによって異なるアルゴリズムが要求される環境では、プロバイダは複数のトレーニングコンテナを登録する必要があるかもしれません。
- MLaaS プロバイダは、テナントがオンデマンドでトレーニングデータを取り込み、モデルを構築するためのサービスエンドポイントとメソッドを公開します。プロバイダは、AWS Marketplace で入出力パラメータ、モデル精度、利用プラン、価格情報などのサービス情報を公開することができます。
- テナントは、AWS Marketplace でサービスを検索して見つけ、サブスクライブします。
- 次に、テナントは機械学習構築パイプラインにトレーニングデータを提供することで、専用の ML モデルの構築を開始することができます。サービスプロバイダが複数のアルゴリズムを使用するサービスを公開している場合、テナントはどのアルゴリズムを使用するかを指定する必要があります。
- これにより、テナントの ML モデル構築パイプラインが起動し、データの準備とクリーンアップ、(1) の Docker イメージによるモデルのトレーニング、パラメータチューニングなどが行われるのが一般的です。トレーニングプロセスの最後には、テナント固有のモデルアーティファクトが専用のストレージにエクスポートされます。
その後、テナント固有のモデルをテスト環境にデプロイし、テナントが希望する ML モデル配信フローを使用して上位環境にデプロイさせることができます。
パイプラインのアーキテクチャ
MLaaS 環境においてモデルがどのように構築され、トレーニングされるかを理解したところで、基盤となるアーキテクチャをより詳細に見ていきましょう。
図2は、Amazon SageMaker Pipelines をコアコンポーネントとするビルドアーキテクチャを示したものです。Amazon SageMaker Pipelines は、機械学習パイプラインを構築するための専用 CI/CD サービスです。トレーニングデータの探索と準備、様々なアルゴリズムとパラメータの実験、モデルのトレーニングとチューニング、そしてモデルのデプロイなどの高度なカスタマイズが可能です。
Amazon SageMaker Pipeline の定義は、テナント間で共有され、アプリケーションのデプロイ時にプロビジョニングされます。Amazon SageMaker Pipeline の実行をトリガーするテナント固有の Amazon Simple Storage Service (Amazon S3) バケットや Amazon EventBridge ルールなどの他のコンポーネントは、テナントのオンボーディング時にプロビジョニングされます。
さらに、テナント固有の AWS Identity and Access Management (IAM) ポリシーは、テナントのオンボーディング時に作成され、Amazon SageMaker Pipeline 実行ロールを利用して、クロステナントのデータアクセスを防止します。

図2 – テナント専用モデルの MLaaS 構築アーキテクチャ。
以下は、このアーキテクチャで表されるステップの内訳です。
- テナント専用の Amazon S3 バケットに、テナントのトレーニングデータが入ったファイルがアップロードされます。もし、アプリケーションが Amazon S3 バケットの制限 を超えてスケーリングする必要がある場合は、プレフィックスでテナントを分離するアプローチが望ましいことに注意してください。
- テナント専用の S3 バケットに対する Amazon S3 の PUT イベントを受信すると、そのテナント固有の EventBridge ルールがトリガーされます。
- テナント固有のルールは、以下のようなテナント固有のパイプラインパラメータを渡すことで、Amazon SageMaker Pipeline の実行インスタンスを開始します。
- トレーニングデータおよび結果として出力されるモデルアーティファクトの Amazon S3 URI。
- トレーニングインスタンスの種類とサイズ(テナントの利用プランとトレーニングデータの量に依存する場合があります)。
- テナント間のアクセスからテナントのデータを保護するための IAM ロール。
- Amazon Elastic Compute Cloud (Amazon EC2) インスタンスにアタッチするリソースタグ。
- Amazon SageMaker モデルレジストリにおけるターゲットグループ名。
- コンテナレジストリのトレーニングイメージの URI。
- Amazon SageMaker Pipeline の実行インスタンスがテナントごとに作成されると、トレーニングデータの前処理とクリーンアップ、Amazon Elastic Container Registry (Amazon ECR) からのトレーニングイメージの取得、テナントの Amazon S3 入力バケットから取得したトレーニングデータによるモデルのトレーニング、出力先の S3 バケットへのモデルのアップロード、Amazon SageMaker Model Registry 内のテナントのモデルグループにモデルのパブリッシュが実行されます。
テナントの分離
このパイプラインアーキテクチャを、SaaS の分離アプローチに照らして確認してみましょう。SaaS の分離には、サイロ、プール、ブリッジと呼ばれる異なるタイプがあります。
サイロアプローチとは、テナントに専用のリソースを提供するアーキテクチャを指します。パイプラインの定義は複数のテナントで共有されますが、ビルド時に Amazon SageMaker Pipelines ランタイムはジョブの処理とトレーニング用に専用のコンピュートリソースを起動させます。
そしてテナントごとに使用するインスタンスの種類とサイズを制御することができます。完全に専用化されたコンピュートリソースは、予測可能なビルド期間と一貫したパフォーマンスを提供し、ノイジーネイバーの懸念を払拭します。
また、テナントのオンボーディング時にテナント固有の IAM ロールが作成され、Amazon S3 バケットへのアクセス制限およびトレーニングジョブで使用されます。このロールは、テナントが他のテナントのデータにアクセスできないようにします。
スケールのためのアーキテクチャー
MLaaS アプリケーションの中には、ML モデルの再トレーニングを相当数同時に行う必要があるものもあり、MLaaS 環境におけるスケーリングの課題が生じます。
- MLaaS 環境では、ML トレーニングや処理ジョブに利用できるインスタンスの数や種類に制限がある可能性があります。
- MLaaS アプリケーションは、異なる利用プランを設定することができます。より上位のプランは、通常、ベーシックなプランと比較してより速いトレーニング時間を保証します。このため、各プランに専用の処理キューを定義する必要があります。
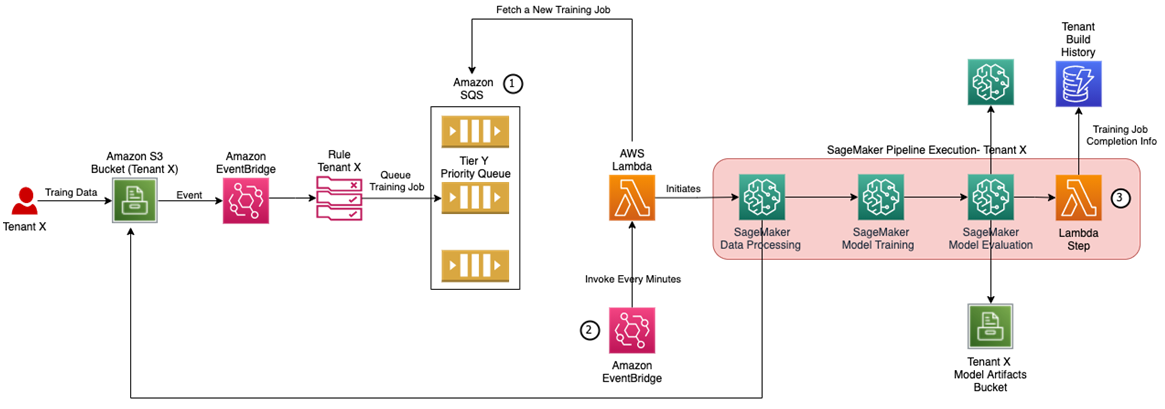
図3 – スケールするトレーニングアーキテクチャ
SaaS / MLaaS アーキテクチャでスケーラブルなトレーニングをサポートするために、図2の推奨アーキテクチャは、図3に示すように、以下のコンポーネントで拡張することが可能です。
- 同時ビルド実行数を制御するために、Amazon Simple Queue Service (Amazon SQS) のキューを活用するとよいでしょう。このキューはトレーニングジョブの設定を受信して保存します。各利用プランに対して個別のキューを用意することも可能です。
- テナントに割り当てられた利用プランの指定された同時実行レベルを超えていない場合にのみ、AWS Lambda 関数が新しい Amazon SageMaker Pipelines 実行インスタンスを開始します。Lambda 関数は、タイマーイベント(EventBridge ルール経由)に基づいてトリガーされ、実行中の Amazon SageMaker Pipelines のステータスを API を使用してチェックすることができます。
- Amazon SageMaker ML ビルドパイプラインは AWS Lambda ステップで拡張され、ML ビルドパイプラインの実行に関連する情報を Amazon DynamoDB データベースに格納し、他の SaaS サービスでテナント管理やレポート作成のために使用することができます。
利用プランごとの段階的な価格設定モデルとテナントごとのコスト計算
各テナントで発生するコストを正確に計算することで、SaaS プロバイダーは魅力的な従量課金モデルを提供することができます。MLaaS 環境では、トレーニングプロセスが大量のコンピュートリソースを消費し、テナントの支出のかなりの部分を占める可能性があります。
トレーニングコストを個々のテナントに配分するには、パイプラインのパラメータとしてテナント固有の値を渡します。そして、パイプラインのステップで、このタグを前処理、トレーニング、およびモデルチューニングの各ジョブに渡します。これらのジョブが使用するコンピュートリソースには、自動的にタグが付けられます。コストエクスプローラーやコスト配分レポートでタグを確認するには、コスト配分タグを有効にする必要があります。
まとめ
この記事では、Amazon SageMaker Pipelines を使用してテナント固有の機械学習モデルを構築するプロセスについて説明しました。各ビルドが、一貫したビルド期間とコスト配分でテナントのデータに制限されたセキュリティコンテキストで実行されるようにするために必要なカスタマイズステップを確認しました。
ML モデルを作成した後、次のステップとして、推論目的で使用するためにモデルをデプロイする必要があります。SaaS アプリケーションにおけるさまざまな推論アーキテクチャについては、この投稿記事を確認してください。
さらに学ぶには、これらの追加リソースを確認することをお勧めします。
- Amazon SageMaker Pipelines を使用した ML ワークフローの構築、自動化、管理、およびスケーリング
- SageMaker ワークショップ(SageMaker Pipelines ラボを含む)
- ホワイトペーパー:SaaS テナントアイソレーション戦略
AWS SaaS Factory について
AWS SaaS Factory は、SaaS のあらゆるステージで組織を支援します。新製品の開発、既存アプリケーションの移行、AWS 上での SaaS ソリューションの最適化など、どのようなニーズにもお応えします。AWS SaaS Factory Insights Hub で、より多くの技術的、ビジネス的なコンテンツやベストプラクティスをご覧ください。
SaaS ビルダーは、AWS SaaS Factory チームとのエンゲージメントモデルについて、アカウント担当者に問い合わせることをお勧めします。
サインアップすると、最新の SaaS on AWS ニュース、リソース、イベントに関する情報を入手することができます。
翻訳はソリューションアーキテクト 前川 泰毅 が担当しました。原文はこちらです。