AWS Partner Network (APN) Blog
Implementing a Multi-Tenant MLaaS Build Environment with Amazon SageMaker Pipelines
By Mehran Najafi, PhD, Sr. Solutions Architect – AWS
By Michael Pelts, Sr. Solutions Architect – AWS
A growing number of companies are building machine learning (ML) models using their own proprietary data, as well as external and third-party data. The trained models can be offered to external customers as a source of new revenue.
Partners hosting customer-specific ML models on Amazon Web Services (AWS) have unique isolation and performance requirements and require a solution that provides a scalable, high-performance, and feature-rich ML platform.
The platform should make it easy to build, test, and run multi-tenant machine learning as a service (MLaaS) applications. ML services can be then offered on AWS Marketplace as a software-as-a-service (SaaS) to AWS customers.
In this post, we will show you how Amazon SageMaker Pipelines can help you to pre-process data, build, train, tune, and register machine learning models in SaaS applications. We will focus on best practices for building tenant-specific ML models with particular focus on tenant isolation and cost attribution.
Representing ML Models in a Multi-Tenant Environment
In an MLaaS environment, a SaaS service is used to host, manage, and run ML models from individual customers (tenants). Tenants of this experience may offer a variety of services, including data cleanup and pre-processing, ML model training, inference endpoint for real-time predictions, batch processing job services for analyzing big data, data visualizations, and other ML services.
Some MLaaS vendors offer pre-trained ML models for a range of common use cases, such as face recognition, sentiment analysis, text-to-speech, or real-time translation. Typically, these models are trained in a “tenantless” environment, free of tenant isolation and cost attribution considerations.
On the other hand, use cases like sales prediction, churn detection, fraud scoring, and many others rely heavily on tenant-specific data. Training data coming from different tenants may have different structure and significantly different statistical nature.
In these cases, MLaaS vendors will need to provide a mechanism where tenant data and models are trained and managed separately. In this pattern, tenants bring in their own custom data, but leverage the same algorithm that is provided by the vendor.
Building Tenant-Specific ML Models
The diagram below depicts a high-level conceptual flow of a sample MLaaS build environment, including typical steps required for building tenant-specific ML models.
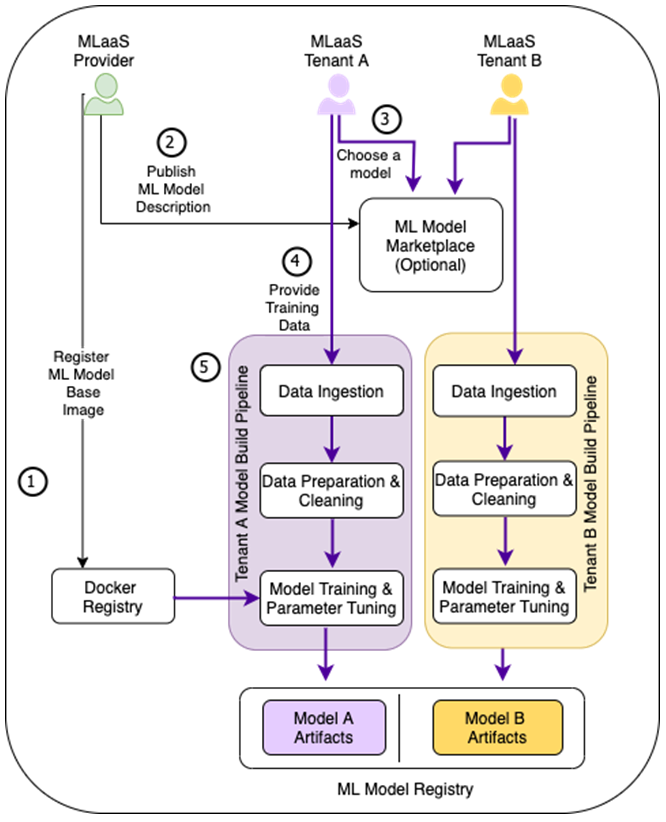
Figure 1 – Different instances of the same ML based model will be trained for different tenants based on the tenant-specific training data.
- The MLaaS provider creates and registers a customer training container for the target ML framework in Docker registry. This step is only required if pre-built training Docker images require customization. Providers may need to register multiple training containers in environments where different algorithms may be required by different tenants.
- An MLaaS provider exposes service endpoints and methods for tenants to ingest training data and build models on-demand. Providers can describe service characteristics, including input and output parameters, model accuracy, service tiering, and pricing info in AWS Marketplace.
- Tenants can then search and find the service in AWS Marketplace and subscribe.
- Next, tenants can initiate building dedicated ML models by providing training data to a machine learning build pipeline. If a service provider exposes services that use multiple algorithms, tenants must specify which algorithm should be used.
- This triggers an ML model build pipeline for the tenant, which typically includes data preparation and cleanup, model training using the Docker image in (1), and parameter tuning. At the end of the training process, the tenant-specific model artifacts are exported to a dedicated storage location.
Tenant-specific models can then be deployed in a test environment and propagated to higher environments using the tenant-preferred ML model delivery flow.
The Pipeline Architecture
Now that you have a view of how models are built and trained in an MLaaS environment, let’s look more closely at the underlying architecture.
Figure 2 below presents a build architecture with Amazon SageMaker Pipelines as a core component. Amazon SageMaker Pipelines is a purpose-built CI/CD service for building machine learning pipelines. It provides highly configurable mechanism for exploring and preparing training data, experimenting with different algorithms and parameters, training and tuning models, and deploying models to production.
The Amazon SageMaker Pipeline definition is shared among tenants and provisioned at the application deployment time. Other components, such as tenant-specific Amazon Simple Storage Service (Amazon S3) buckets and Amazon EventBridge rules that trigger Amazon SageMaker Pipeline executions, are provisioned during tenant onboarding.
Furthermore, tenant-specific AWS Identity and Access Management (IAM) policies are created during tenant onboarding and used by Amazon SageMaker Pipeline execution roles to prevent cross-tenant data access.

Figure 2 – MLaaS build architecture for tenant-specific models.
Below is a breakdown of the steps represented in this architecture:
- A file with a tenant training data is uploaded into a tenant-dedicated Amazon S3 bucket. Note that if your application requires scaling beyond the Amazon S3 bucket limits, a prefix-per-tenant approach would be preferable.
- Upon receiving Amazon S3 PUT event for a tenant-specific S3 bucket, EventBridge triggers a rule which is also specific to the same tenant.
- The tenant-specific rule initiates an execution instance of the Amazon SageMaker Pipeline by passing the tenant-specific pipeline parameters, such as:
- Amazon S3 URIs for the training data and resulting model artifact.
- Training instance types and sizes that may depend on tenant tier and amount of training data.
- IAM role to protect tenants’ data from cross-tenant access.
- Resource tags to attach to Amazon Elastic Compute Cloud (Amazon EC2) instances.
- Target group name in the Amazon SageMaker Model Registry.
- Training image URI in the container registry.
- Once an execution instance of the Amazon SageMaker Pipeline is created for each tenant, it pre-processes and cleans up the training data, retrieves a training image from Amazon Elastic Container Registry (Amazon ECR), trains the model with the training data from the tenant’s Amazon S3 input bucket, uploads the model to destination S3 bucket, and publishes the model into the tenant’s model group in Amazon SageMaker Model Registry.
Tenant Isolation
Let’s examine the proposed pipeline architecture with respect to SaaS isolation approaches. There are different types of SaaS isolation, known as silo, pool, and bridge.
The silo approach refers to an architecture where tenants are provided dedicated resources. Even though pipeline definition is shared between multiple tenants, at build time Amazon SageMaker Pipelines runtime spins up dedicated compute resources for processing and training jobs.
You can control instance type and size used for different tenants. Fully-dedicated compute resources provide consistent performance with predictable build duration and remove any noisy neighbor concerns.
A tenant-specific IAM role is also created during the tenant onboarding and used in processing and training jobs to restrict the access to Amazon S3 buckets. This role ensures that tenants can’t access another tenant’s data.
Architecting for Scale
Some MLaaS applications require significant number of concurrent ML model re-training jobs which introduce challenges of scaling in an MLaaS environment:
- There could be some limitations on the number and type of computational instances available for ML training and processing jobs.
- MLaaS applications can come into different subscription tiers. A more advanced tier usually guarantees a quicker training time comparing to basic tiers. This requires defining dedicated processing queues for each tier.
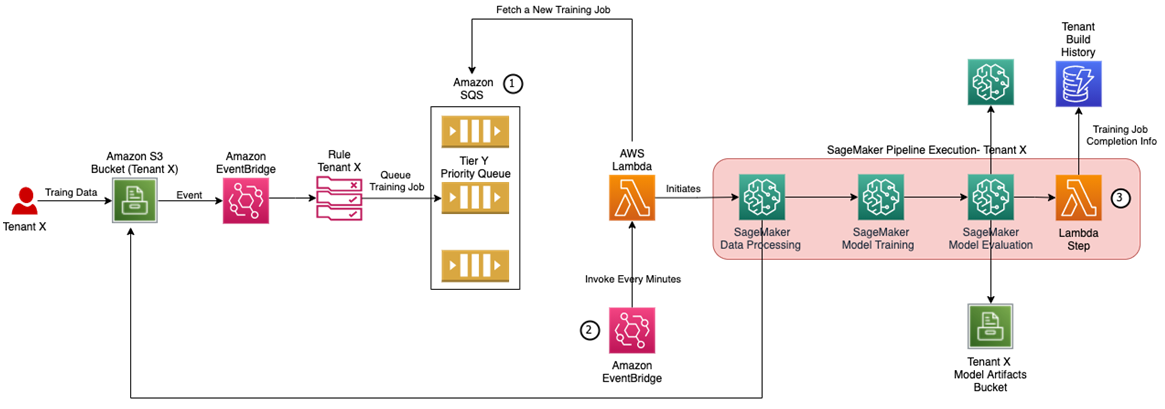
Figure 3 – Scaling training architecture.
In order to support training at scale in a SaaS MLaaS architecture, the recommended architecture in Figure 2 can be extended with the following components shown in Figure 3.
- To control the number of concurrent build executions, you may want to leverage an Amazon Simple Queue Service (Amazon SQS) queue which receives and stores the training job description. There could be a separate queue for each subscription tier.
- The AWS Lambda function only initiates a new Amazon SageMaker Pipelines execution instance if it doesn’t exceed designated concurrency level for the subscription tier assigned to the tenant. The Lambda function can be triggered based on a timer event (via EventBridge rule) and check the status of the running Amazon SageMaker Pipelines using its APIs.
- The Amazon SageMaker ML build pipeline is extended with an AWS Lambda step to store information related to the ML build pipeline execution into an Amazon DynamoDB database to be used by other SaaS services for the tenant management and reporting purposes.
Tiered Pricing Model and Cost per Tenant Calculations
The ability to calculate the exact cost incurred by each tenant enables SaaS providers to offer attractive pay-as-you-go pricing models. In MLaaS environments, training processes may consume significant amount of compute resources and can account for a substantial portion of tenant’s spend.
To attribute training cost to individual tenants, pass a tenant-specific value as a pipeline parameter. Then, in the pipeline steps pass this tag to pre-processing, training, and model-tuning jobs. Any compute resources span up by these jobs will be tagged automatically. Make sure to activate Cost Allocation Tags to see them in Cost Explorer and cost allocation report.
Conclusion
In this post, we covered the process of building tenant-specific machine learning models with Amazon SageMaker Pipelines. We reviewed the customizations steps needed to ensure each build is executed in scoped security context that allows access to tenant’s data with consistent build duration and cost attribution.
After you create ML models and as the next step, you need to deploy the model to be used for inference purposes. Check out this AWS blog post to learn about different inference architectures in SaaS applications. Refer to the multi-tenant ML-as-a-service workshop which showcases how to implement the concepts described in this post.
To learn more, we recommend you review these additional resources:
- Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines.
- SageMaker workshop including SageMaker Pipelines lab.
- Whitepaper: SaaS Tenant Isolation Strategy.
About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.