AWS Partner Network (APN) Blog
Implementing SaaS Tenant Isolation Using Amazon SageMaker Endpoints and IAM
By Michael Pelts, Sr. Solutions Architect, ISV – AWS
By Joshua Fox, Sr. Cloud Architect – DoiT International
 |
As multi-tenant software-as-a-service (SaaS) providers look to leverage machine learning services, they must consider how they’ll protect the data that flows in and out of these services from different tenants.
SaaS providers must introduce isolation constructs that, for each request to a machine learning (ML) service, ensure each tenant’s data is protected from any cross-tenant access.
We’re both cloud architects advising leading technology companies—Michael is from AWS, and Joshua is an architect at DoiT International, an AWS Advanced Consulting Partner and Managed Service Provider (MSP) that provides intelligent technology and unlimited advisory, technical, and cloud engineering support for digital-native companies.
In our experience, we have seen some ML service providers choose to separate their tenant resources, while others have chosen to share resources across all of their tenants.
Regardless of whether the tenants’ underlying resources are shared or dedicated, every SaaS provider must apply isolation policies to ensure these tenant resources are secured.
In this post, we’ll focus on how tenant isolation of machine learning services can be achieved using AWS Identity and Access Management (IAM). We’ll look at how the integration between IAM, Amazon SageMaker, and many other AWS services provide developers with a rich set of mechanisms that can be applied to realize tenant isolation goals.
Inference Architecture and Tenant Isolation
Let’s start by looking at the inferencing components that are typically part of a machine learning architecture.
First, it’s important to note we’ll be using Amazon SageMaker endpoints as part of our isolation solution. This is a core concept that represents a group of one or more Amazon Elastic Compute Cloud (Amazon EC2) instances that offer REST APIs for inference, based on trained ML models, with one or more models per endpoint.
The diagram in Figure 1 provides a view of how we’ll be managing access to these endpoints and using them to isolate tenant data. Clients, rather than accessing the endpoints’ APIs directly, will invoke an Amazon API Gateway which triggers an AWS Lambda function and invokes an Amazon SageMaker endpoint. Learn more about the architecture in this post on the AWS Machine Learning Blog.
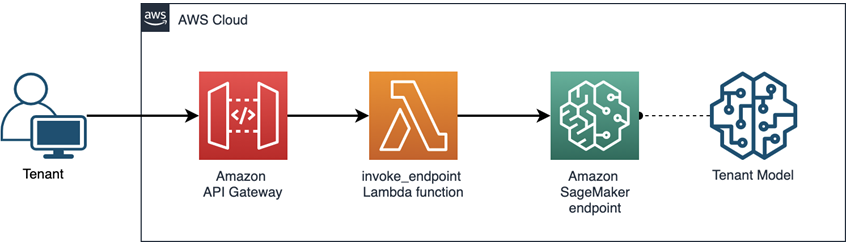
Figure 1 – Invocation flow for inferencing in Amazon SageMaker.
In this invocation architecture, we’ll introduce IAM policies that will be used to ensure tenants are only allowed to access their own resources. Any attempt to cross a tenant boundary will be denied. The key here will be to define an approach that leverages tenant context to control access to each Amazon SageMaker endpoint so tenants can only access their own ML models, and not ML models belonging to other tenants.
Tenant Isolation Models
Let’s examine the common deployment models that are typically used when isolating multi-tenant workload. We refer to these three different types of SaaS isolation models as silo, pool, and bridge.
Below, we’ll describe how service providers choose between these different models, and drill down to show how IAM can be used to implement each of these isolation strategies.
Silo Model
In the silo model, the focus is on completely separating each tenant’s resources.
For our inferencing architecture, the silo model is achieved by deploying a separate stack for each tenant. This stack is provisioned automatically during tenant onboarding. In our example, this would mean we’d need to provision the following resources for each tenant:
- Amazon API Gateway for each tenant. Note that in a less siloed approach, tenants share an API Gateway that routes to a tenant-specific function based on the tenant context.
- AWS Lambda function. Note that all Lambda functions will have the same code, and the Amazon SageMaker endpoint that each invokes is defined in an environment variable.
- Amazon SageMaker endpoint.
- Machine learning model, in the endpoint.
- Role for each Lambda function to run under, permitting it to access that endpoint.
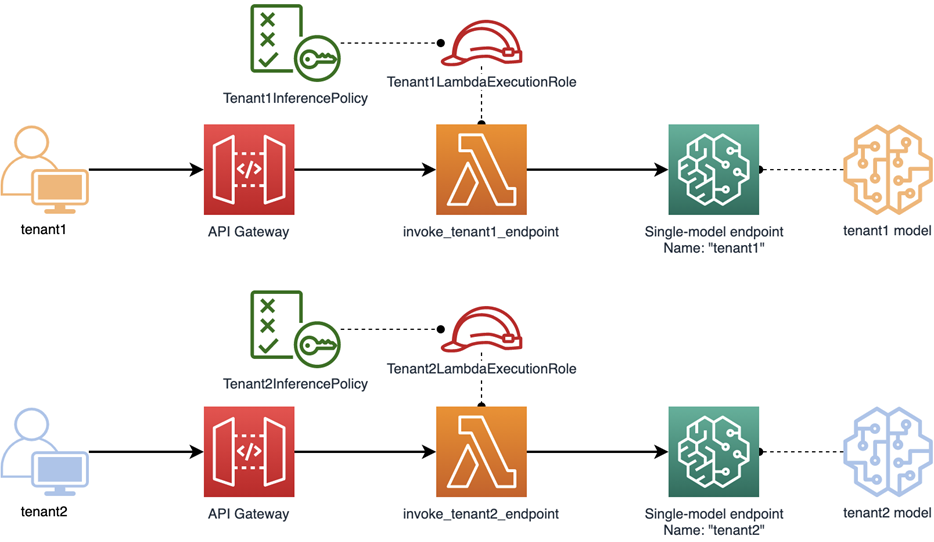
Figure 2 – Silo isolation model with separate resources.
In the diagram above, you can see how we’ve implemented the silo model. Here, we have a separate gateway and Lambda function for each tenant. Having a separate function for each tenant allows us to give each Lambda its own execution role.
Each execution role has an attached IAM policy that grants sagemaker:InvokeEndpoint permission only on this tenant’s endpoint. Any cross-tenant InvokeEndpoint call would be denied by IAM, for lack of a match to the endpoint resource name specified in the policy.
The key takeaway for the silo model is that Lambda functions, endpoints, and roles each map one-to-one to individual tenants.
Policy 1 – Tenant2InferencePolicy attached to Tenant2LambdaExecutionRole.
The policy above provides an example of how you’d configure the isolation policies in this model. The Tenant2InferencePolicy is for Tenant2. Meanwhile, Tenant1’s Tenant1InferencePolicy would differ in the Resource element, where the final part of the Amazon Resource Name (ARN) would be tenant1.
Silo offers many advantages with its strict architectural division between tenants:
- By using the execution role, it provides a less invasive model for applying IAM roles.
- Avoids noisy neighbor problems that can increase latency, since tenant models are always ready to serve requests.
- Reduces scope of impact; failures will only affect individual tenants.
- Security is made easier for developers, as they don’t have to worry about incorrect use of shared resources such as temporary folders or global variables, which might expose data across requests from different tenants.
- Tenant-level cost metering can be enabled by tagging the resources. For example, if we attach a tag with key name
CostCenterand value equal to the tenant name, we can use cost analysis tools to determine how much of the Amazon SageMaker endpoint expense is associated with each tenant.
Still, the Silo carries with it some disadvantages:
- As the number of tenants grows, so does the expense, since each endpoint has one or more allocated EC2 instances. These dedicated resources make it difficult to align tenant activity with actual resource consumption.
- You may exceed AWS service quotas for Amazon SageMaker endpoints and other resources.
- Provisioning the entire stack per tenant means potentially longer onboarding time.
- Complexity of management and operations grow linearly with the number of tenants.
Pool Model
In the pool model, tenants share resources. This is where isolation becomes more difficult, because we must apply the same values of tenant isolation in an environment where tenants are using shared infrastructure.
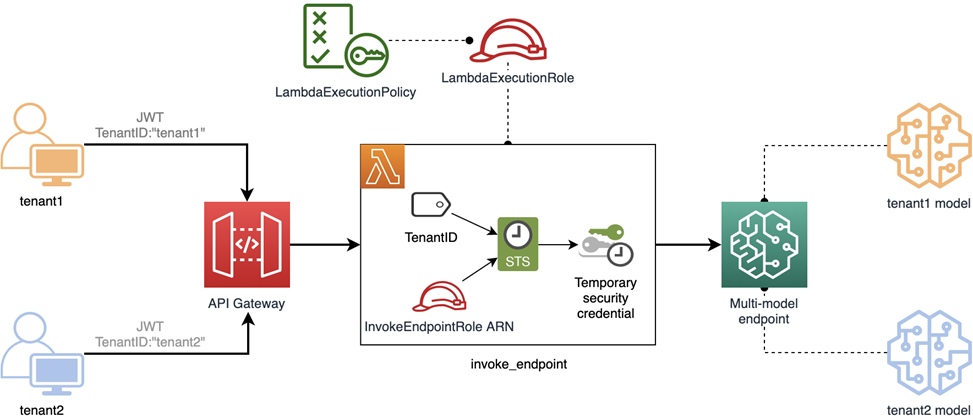
Figure 3 – Pool isolation model with shared resources.
The diagram above provides an illustration of how you might implement the pooled model. You’ll notice it uses a shared API Gateway and Lambda function for multiple tenants. It also employs a multi-model Amazon SageMaker endpoint that is shared between tenants, exposing multiple ML models.
These models are stored in Amazon Simple Storage Service (Amazon S3) and only loaded into the endpoint’s memory as needed. Learn how to create and use multi-model endpoints in this post on the AWS Machine Learning Blog.
Because the endpoint is now shared by multiple tenants, we must use a finer-grained IAM policy to protect tenant resources.
In this example, we have a Lambda execution role as before. However, unlike our silo example, the execution role cannot be constrained to a specific tenant. Instead, it must be able to process requests from all tenants.
Now, as each request comes into the Lambda function, it will need to dynamically apply a policy based on the incoming tenant context. This context gets applied using Attribute Based Access Control (ABAC). This is more flexible than the basic Role Based Access Control (RBAC), as it allows you to use a parameterized policy attached to a role, to precisely define the requests that are allowed access.
(An alternative approach uses dynamically generated IAM policies, which you can read about in this post by the AWS SaaS Factory team.)
For each request, the Lambda function dynamically creates a temporary IAM role session and attaches a TenantID tag to it. This session defines a security context in which the endpoint is accessed. The access is then granted if, and only if, the session tag matches the resource name, narrowing model access to just those models that are valid for the current tenant.
Note that instead of creating a temporary session in the Lambda itself, you can use API Gateway Lambda Authorizer for that. If you do so, pass temporary credentials returned by sts:AssumeRole in the response context. Then, in the downstream Lambda you can use these credentials to access the Amazon SageMaker endpoint.
Since our machine learning models are stored in files, our IAM policies must define conditions that would control access to the model file. In looking at the InvokeEndpointPolicy below, you’ll see that it verifies that the PrincipalTag/TenantID tag in the request context matches the filename of the model that’s being invoked inside the endpoint.
Policy 2 – InvokeEndpointPolicy attached to InvokeEndpointRole.
The process of dynamic session creation and tagging is described in this SaaS Factory post. That post also presents the trust policy required for Lambda to assume InvokeEndpointRole, and a Boto3 function that creates and tags a temporary session which can be used in our Lambda.
Note that in the policy above we assume the tenant identifier doesn’t match the model filename in full, but rather the part without the .tar.gz suffix: for example, tenant2 and tenant2.tar.gz.
In choosing the tenant identifier, note that it must follow the S3 object-key name guidelines because we are matching an S3 filename to a tag value.
With this ABAC check, different invocations of the same Lambda function run in a specific security context which denies cross-tenant inference calls.
Advantages of the pool model include:
- Better economies of scale, including on endpoint costs. The savings are particularly valuable if some tenants rarely invoke inferencing.
- Reduces risk of hitting AWS quotas and limits.
- More manageable, since there are fewer AWS resources to track.
- Shorter provisioning time, since you don’t need to provision a large number of resources using infrastructure as code (IaC).
- Less complex management and deployment model.
Pool model disadvantages:
- Occasional cold start-related latency penalties occur when invoking infrequently used models.
- Shared components may not satisfy your compliance needs, especially in highly regulated industries.
- Wider scope of impact; in case of failure in one EC2 instance or other cloud resource, multiple tenants will be impacted.
Bridge Model
The bridge model represents a combination of the silo and pool models. Here, some layers of the infrastructure are shared, while others are dedicated to specific tenants. In this way, the advantages of silo and pool can be applied based on your specific needs.
In our bridge approach to Amazon SageMaker inference, the API Gateway and Lambda function are shared, but the Amazon SageMaker endpoints are siloed, with separate models for each tenant.
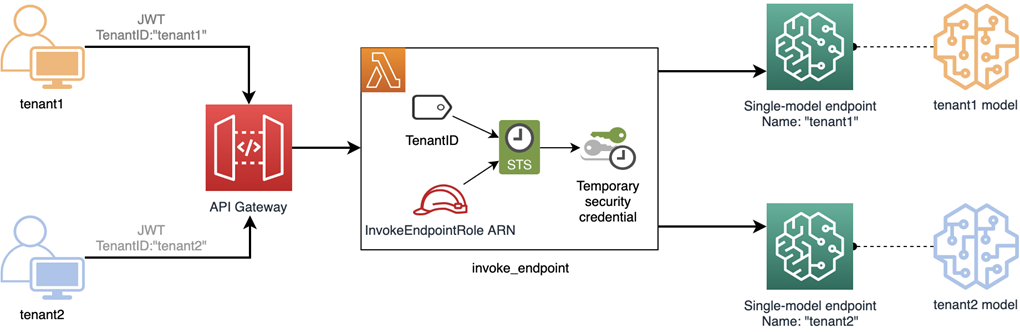
Figure 4 – Bridge invocation model with shared and separate resources.
In the diagram above, you’ll see that the entry point to your solution looks very much like the pool model. It uses ABAC and the fine-grained flexibility of dynamic policies to control tenant access. This approach also requires that all invocations from the Lambda be under a shared Lambda execution role.
In this design, we use the tenant identifier as an endpoint name to allow us to compare them. The Lambda function takes the endpoint name from the context, usually passed as a custom claim in JWT (in contrast to the silo, where the endpoint name comes from an environment variable).
As in the pool model, the InvokeEndpointRole is allowed to call InvokeEndpoint. But in the bridge model, we reference the endpoint name (rather than the model filename as earlier). This value must match the value of PrincipalTag/TenantID exactly.
Policy 3 – InvokeEndpointPolicy attached to InvokeEndpointRole for single-model endpoints.
This approach shares some advantages with the silo and pool models. It strikes a balance between the two that may represent a good fit for some organizations.
Advantages include:
- As with silo, bridge has the advantage of consistent low latency and more clearly managed security boundaries provided by single-model inference endpoints.
- Sharing a Lambda function provides a degree of simplicity, since generating many copies of a function increases the number of resources under management.
- As with pool, there is no need to generate new static roles per tenant and risk hitting limits on the number of roles. Instead, the model for any new tenant is automatically protected by ABAC.
This approach, likewise, shares some disadvantages with the silo and pool models:
- As with silo, costs for the endpoint go up quickly as tenants are added.
- As with pool, developers must take care to keep sensitive data isolated across invocations.
Quick Comparison Table
| Benefits | Disadvantages | When to use | |
| Silo |
|
|
|
| Pool |
|
|
|
| Bridge |
|
|
|
Summary
In supporting multiple tenants for Amazon SageMaker inference, SaaS providers need to find a deployment model that best aligns with the needs of their offering, balancing multiple requirements such as low cost, low latency, efficient management, and security.
Depending on their business and legal requirements, the silo, pool, or bridge model allows SaaS providers to serve inference endpoints to many tenants. The silo model fully isolates tenants for security and performance, while pool reduces costs with shared resources and bridge balances between the two.
Compute resources may be shared or separate. Where shared resources are used, IAM with ABAC allows the service providers to support multiple tenants securely and conveniently.
To learn more, we recommend you review these additional resources: