Amazon Web Services ブログ
Amazon Forecastによる短期電力負荷予測
この記事は、Short-term Electric Load Forecasting with Amazon Forecastを翻訳したものです。現在、家庭用、商業用、工業用(RCI)のお客様の大半は、「フィーダー」と呼ばれる配電回路を介して電気を受け取っています。配電フィーダーは、下図のように、配電変電所内の回路ブレーカーを起点とし、多くのお客様にサービスを提供しています。送電網の信頼性を高めるために、フィーダーは複数の変電所から電気を受け取るように構成されていることが多いですが、これらの接続スイッチは常に1つしか作動しないようになっています。フィーダーの一方で断線が発生した場合、スイッチを所定の方法で開閉し(スイッチング)、もう一方の端からフィーダーに電力を供給します。
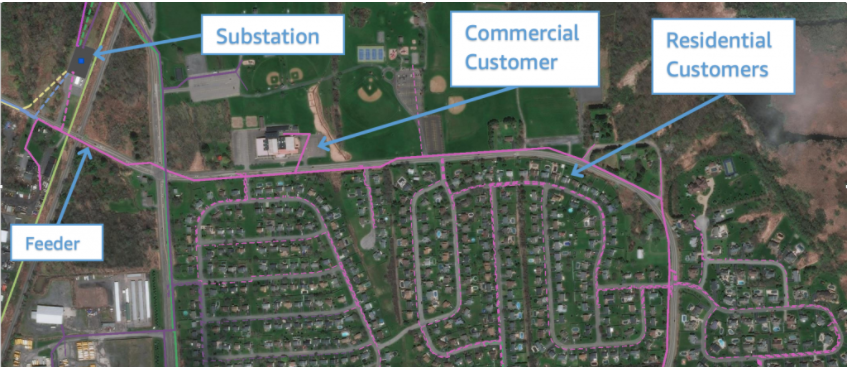
図1:変電所、フィーダー、お客さまの位置のイメージ
キロワット(kW)単位で測定されるフィーダーの電気負荷は、動的に変動し、時間、日、季節ごとに非線形なパターンを持っています。電圧低下やサービス停止などの悪影響を避けるためには、送電網の電力の需要と供給のバランスを常に保つ必要があるため、給電網と変電所の需要の正確な短期電力負荷予測(ST-ELF)は、電気事業者の運営と計画に不可欠な要素となっています。ST-ELFは、グリッドに接続されている断続的な分散型発電(RCIソーラー、エネルギー貯蔵、風力発電システムなど)の普及率が高いことなど、多くの要因によって複雑になっています。
ST-ELFの主な目的は、今後1〜14日間の近い将来のネットフィーダー負荷を予測することです。ネットフィーダー負荷とは、フィーダー回路ブレーカーで測定される負荷のことで、系統に接続されているすべての種類の顧客の電気消費量と発電量の合計に、電線や変圧器の電気損失を加えたものです。ST-ELFのエンドユーザーは、電力会社のコントロールセンターのオペレーターや系統運用計画のエンジニアが一般的です。ST-ELFを必要とするユースケースには、以下のようなものがあります。
- メンテナンスや復電を可能にするための回路切り替えや、負荷を動的に制御するなど、配電操作を効果的に行うための運用計画。これは、スイッチングによって構成された新しい配電回路の配置が、お客様の負荷を適切に処理できるようにするためです。
- 配電線や変圧器などの過負荷(またはわずかに過負荷)の配電システムコンポーネントの建設やアップグレードの必要性を延期または排除することを目的とした、NWA(Non-Wire Alternatives:非従来型送配電ソリューション)の促進。NWAを実現するために、電力会社は分散型エネルギー資源(DER)の所有者から電力を調達し、フィーダー/サブステーションの過負荷資産(電力変圧器やゲートウェイケーブルなど)の負荷を軽減しているケースもあります。正確なST-ELFを使用することで、電力会社は潜在的なNWAのニーズを特定し、実現することができます。NWAソリューションを実現することで、低コストで顧客や環境へのメリットが高いグリッドインフラのニーズに対応することができます。
※訳注:NWAとは、送配電グリッドの代わりとなる設備投資及び運用の総称。NWAの活用は設備投資の回避によるコスト削減や、 混雑回避を目的としています。 - 配電回路の過負荷を回避するために、需要のピーク時にエネルギー消費量の削減を要請すべき送配電回路、ひいては顧客を特定し、可能にすること。これらはデマンドレスポンスプログラムとして知られており、ST-ELFを主要なインプットとして使用しています。
- 電力会社が所有するエネルギー貯蔵装置(ES)の充放電パターンを最適化し、通常運転時や緊急時の負荷軽減のために、フィーダー上のエネルギー供給と需要を最適化しています。
従来、フィーダー/変電所の電力需要を予測するには、表計算ソフトやチャート、テーブルなどを用いて手作業で行っていましたが、これらの方法では正確で信頼性の高い予測を行うことができませんでした。人工知能と機械学習(AI/ML)技術の出現により、研究者たちは現在、ST-ELFのモデリングを改善しています。これらのアプローチには、ST-ELFモデルを構築・維持するためのAI/MLとデータサイエンスの専門知識が必要です。今日では、これらのスキルセットは多くの電力会社の専門分野から外れています。
AWSによる短期電力負荷予測
このブログの目的は、Amazon ForecastなどのAWSサービスを使って、データの抽出、変換、正確なST-ELF予測パイプラインの構築をいかに楽に自動化できるか、その方法の一つを示すことです。Amazon Forecastは、高度な機械学習技術を用いて高精度な予測を実現するフルマネージドサービスです。この方法論は、公益事業者がAI/MLやデータサイエンティストに多額の投資をすることなく、正確なST-ELFモデルを生成することを可能とします。
Amazon Forecastは、機械学習の専門知識を必要とせず、Amazonの豊富な予測経験の力をすべての開発者の手にもたらします。従来の手法に比べて最大50%の精度を持つ高精度な予測を実現するフルマネージドサービスです。次の図に示すように、過去の電力需要データを「Amazon Forecast」に送ることができます。すると、このサービスは自動的にデータパイプラインを設定し、データを取り込み、過去のデータに基づいてモデルを学習し、精度指標を提供し、予測を生成します。また、特徴を識別し、データに最適なアルゴリズムを適用し、ハイパーパラメータを自動的に調整します。Amazon Forecastはモデルをホストし、必要に応じて簡単にクエリを実行できるようにします。このような作業がすべてバックグラウンドで行われるため、電力会社は、機械学習の専門家チームや自社モデルを維持するためのリソースを構築する必要がなく、時間と労力を節約することができます。さらに、「Amazon Forecast Weather Index」は、過去および予測される気象情報をモデルに組み込む機能です(米国、カナダ、ヨーロッパのロケーションを対象としており、今後も追加を予定しています(2021年5月14日時点では日本はサポートされていません。))。Weather Indexを有効にすると、「Amazon Forecast」は、予測器の学習中に精度の向上が見られた時系列にのみ、自動的に天候機能を適用します。これは、太陽光のような分散型発電システムを検討する際に特に役立ちます。

図2:ソリューションアプローチの概要
ソリューション構成
次の図は、電力会社のST-ELFユースケースのフィーダーレベル予測のソリューションのアーキテクチャを示しています。このソリューションは、2021年初頭に作成された自動化されたソリューションで、米国北東部に位置する公益事業者の、少なくとも2年間の時間ごとの履歴データを持つ約10本のフィーダーの公開データで検証されました。(注:このアプローチは、AWS Glue Data BrewやSageMaker Data WranglerなどのAWSの最新のデータ準備ツールを使って、さらに一般化できる可能性があります)。予測結果の精度は、MAPE(Mean Absolute Percentage Error)指標を用いて計算され、平均で5~7%でした。本ソリューションは、AWSのマネージドサービスを活用しているため、AI/MLの専門知識は一切必要ありません。

図3.アーキテクチャの概要
ソリューション・アプローチには、以下の大まかなステップが含まれており、それらについてさらに説明します。
①Gold Module – オンプレミスのOSIsoft PI (PI)システムからのデータの取り込みと変換
②Blue Module – 予測。Amazon Forecastへの一連のAPIの呼び出し
③Green Module – モニタリングと通知
④Red Module – 評価と視覚化
前述の図の左側のボックス(「オンプレミス」と表示)は、一般的な電力会社がオンプレミスで確立しているフィールドデータインジェストの例です。このケースでは、フィールドセンサー(フィーダーヘッドメーター)からのデータ取り込みは、PIシステムを通じてすでに行われています。したがって、出発点はエクセル形式で抽出された生のフィーダー回路の需要データであり、オンプレミスで保存されています。Amazon Forecastがこのデータを使用するためには、まずAmazon Simple Storage Service(Amazon S3)にアップロードする必要がありますが、これはスケジュールされたスクリプトによって定期的に実行できます。
次に(①Gold Moduleで)、生データがユーティリティーのカスタムビルド形式でAWS S3に用意されているので、データを編集する必要があります。これには、対象となるデータ(kW単位の実電力)の抽出、データのクリーニング、再フォーマットが含まれます。そのために、「ETL & Data Lake」と書かれたボックスにあるサービスを以下のように利用しています。
- 生データとフォーマットされたデータの保存には、Amazon S3を使用します。耐久性と可用性に優れたこのオブジェクトストレージは、ST-ELFの入力データセットがAmazon Forecastによって利用される場所です。
- 生データの編集と変換には、AWS Lambdaを使用しています。このサーバーレスコンピュートサービスは、イベント(ここでは新しい生ファイルのアップロード)に応じてコードを実行し、コードが必要とするコンピューティングリソースを自動的に管理します。
- フルマネージドなメッセージキューイングサービスであるAmazon Simple Queue Service(Amazon SQS)は、複数のデータ変換のLambda関数を分断します。キューはバッファとして機能し、多くのフィールドセンサーからの多数のイベントを消費する際に、システムのトラフィックをスムーズにすることができます。
- データカタログの作成には、AWS Glueを使用します。このサービスは、Glueデータカタログのテーブルを更新するためにクローラーを実行することができ、ここでの設定では、毎日のスケジュールで実行されます。
データの整理が完了し、ST-ELFモデルの学習の準備が整いました。モデルの学習には、Amazon Forecast(②Blue Module)を使用します。Amazon Forecastを使用するには、トレーニングデータのインポート、予測モデル(ここではST-ELFモデル)の作成、モデルを使用した予測の作成が必要で、最後に予測とモデルの精度メトリクスをAmazon S3にエクスポートします。
複数のST-ELFモデルの取り込み、モデリング、予測のプロセスを効率化するために、Improving Forecast Accuracy with Machine Learningソリューションを活用しています。このベストプラクティスのAWSソリューションは、AWS CloudFormationテンプレートとAmazon Forecastサービスのワークフローを提供することで、Amazon Forecastを使用したインジェスト、モデリング、予測のプロセスを効率的に構築します。
予測が完了するまでに時間がかかる可能性があるため、このソリューションではAmazon Simple Notification Service(Amazon SNS)を使用して、予測の準備ができたときにメールを送信しています。また、すべてのAWS Lambda関数のログは、Amazon CloudWatchに取り込まれます(③Green Module)。
予測の準備が整うと、このソリューションは予測データを指定し、Amazon S3に保存します。これにより、14日先の予測のニーズを満たすことができます。また、このソリューションは、Amazon Athena(④Red Module)を使用して、予測の入力および出力データをSQLでクエリするメカニズムを提供します。さらに、このソリューションでは、AWSのビジネス・インテリジェンス(BI)サービスであるAmazon QuickSightで可視化ダッシュボードを自動的に作成することができ、ダッシュボードでデータをインタラクティブに可視化することができます。

図4.Amazon QuickSightのフィーダー予測ダッシュボードの例
予測結果の精度を評価するために、Amazon SageMaker Jupyterノートブックを使って、生成された予測に対する実際のテストデータのMAPE指数(予測手法の予測精度の標準的な指標)を計算することができます。これにより、予測性能を評価する仕組みを提供します。以下のノートブックのスクリーンショットでは、フィーダーのMAPE結果が約6%であることがわかります(これは、従来の非ML手法で行われた場合、一般的に20%から50%であるため、動的なフィーダーの電力プロファイルの予測誤差が驚くほど低いことを示しています)。
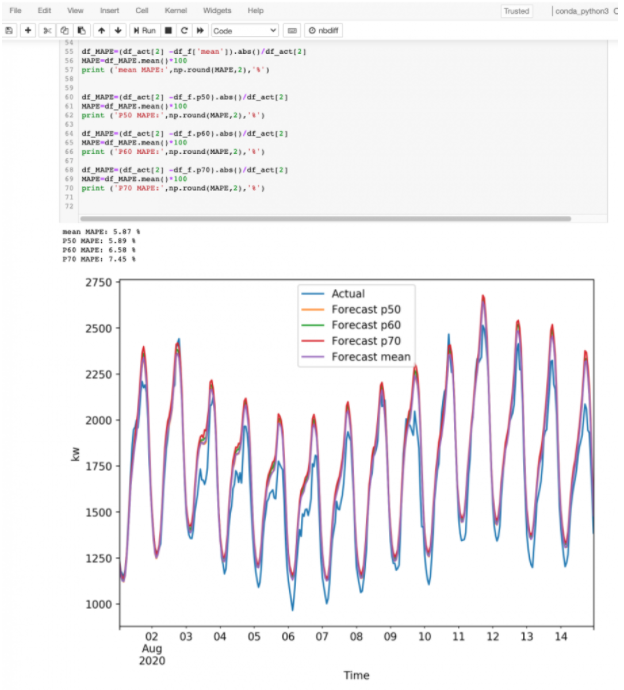
図5.MAPEの計算結果を示すJupyter notebookのスクリーンショット
まとめ
この投稿では、電力会社にとっての短期電力負荷予測(ST-ELF)の重要性とユースケースを説明した後、AWSマネージドAI/MLサービス「Amazon Forecast」を活用して、AI/MLの専門知識を必要とせずに正確な予測を生成するソリューション・アーキテクチャを提案しました。このソリューションは完全に自動化されており、実際に複数のフィーダーでテスト・検証を行いました。予測性能はMAPEで測定され、ランダムにテストされたフィーダーの中で平均5~7%となっています。
AWSが公益事業を支援する最新の方法については、ブログまたはAWS for Power and Utilitiesをご覧ください。
翻訳はデジタル・トランスフォーメーション・アーキテクトの殿山が担当しました。原文はこちらです。