Amazon Web Services 한국 블로그
Amazon Managed Workflows for Apache Airflow(MWAA) 정식 출시
데이터 처리 파이프라인의 양과 복잡성이 증가함에 따라 전체 프로세스를 일련의 작은 태스크로 분해하여 간소화하고 워크플로의 일부로 이러한 태스크의 실행을 조정할 수 있습니다. 이를 위해 많은 개발자와 데이터 엔지니어가 커뮤니티에서 만든 플랫폼인 Apache Airflow를 사용하여 워크플로를 프로그래밍 방식으로 작성, 예약 및 모니터링합니다. Airflow를 사용하면 워크플로를 스크립트로 관리하고, 사용자 인터페이스(UI)를 통해 모니터링하며, 강력한 플러그인 세트를 사용해 기능을 확장할 수 있습니다. 그러나 Airflow를 수동으로 설치, 유지 관리 및 확장하는 동시에 사용자의 보안, 인증 및 권한 부여를 처리하려면 실제 비즈니스 문제 해결에 쏟는 시간보다 더 많은 시간이 할애됩니다.
이러한 이유로 AWS에서 오픈 소스 버전의 Apache Airflow를 쉽게 실행하고 추출-변환-로드(ETL) 작업 및 데이터 파이프라인을 실행할 워크플로를 구축할 수 있는 완전관리형 서비스, Amazon Managed Workflows for Apache Airflow(MWAA)의 출시 소식을 전하게 되어 정말 기쁩니다.
Airflow 워크플로는 Amazon Athena 쿼리를 사용하여 Amazon Simple Storage Service(S3)와 같은 소스에서 입력을 검색하고, Amazon EMR 클러스터에서 변환을 수행하며, 결과 데이터를 사용하여 Amazon SageMaker에서 기계 학습 모델을 훈련할 수 있습니다. Airflow에서 워크플로는 Python 프로그래밍 언어를 사용하여 Directed Acyclic Graph(DAG)로 작성됩니다.
Airflow의 주요 이점은 플러그인을 통한 개방된 확장성에 있습니다. 이를 통해 AWS Batch, Amazon CloudWatch, Amazon DynamoDB, AWS DataSync, Amazon ECS 및 AWS Fargate, Amazon Elastic Kubernetes Service(EKS), Amazon Kinesis Firehose, AWS Glue, AWS Lambda, Amazon Redshift, Amazon Simple Queue Service(SQS) 및 Amazon Simple Notification Service(SNS)를 포함하여 워크플로에 필요한 온프레미스 리소스 또는 AWS와 상호 작용하는 태스크를 생성할 수 있습니다.
관측 가능성을 개선하기 위해 Airflow 지표는 CloudWatch 지표로 게시할 수 있으며, 로그를 CloudWatch Logs에 보낼 수 있습니다. Amazon MWAA는 업그레이드가 수행되는 유지 관리 기간을 지정하는 옵션을 통해 기본적으로 자동 마이너 버전 업그레이드 및 패치를 제공합니다.
다음과 같은 3단계로 Amazon MWAA를 사용할 수 있습니다.
- 환경 생성 – 각 환경에는 스케줄러, 작업자 및 웹 서버를 포함한 Airflow 클러스터가 포함됩니다.
- DAG와 플러그인을 S3에 업로드 – Amazon MWAA는 코드를 Airflow에 자동으로 로드합니다.
- Airflow에서 DAG 실행 – Airflow UI 또는 명령줄 인터페이스(CLI)에서 DAG를 실행하고 CloudWatch에서 환경을 모니터링합니다.
실제로 어떻게 작동하는지 알아보겠습니다!
Amazon MWAA를 사용하여 Airflow 환경을 생성하는 방법
Amazon MWAA 콘솔에서 [환경 생성(Create environment)]을 클릭합니다. 환경에 이름을 지정하고 사용할 Airflow 버전을 선택합니다.
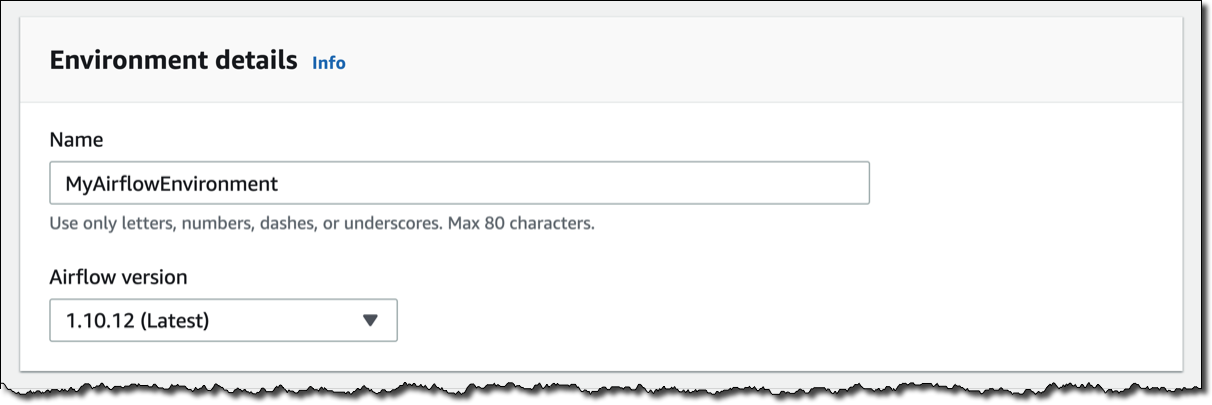
그런 다음, S3 버킷과 폴더를 선택하여 DAG 코드를 로드합니다. 버킷 이름은 airflow-로 시작해야 합니다.
선택적으로 플러그인 파일과 요구 사항 파일을 지정할 수 있습니다.
- 플러그인 파일은 DAG에서 사용하는 플러그인을 포함하는 ZIP 파일입니다.
- 요구 사항 파일은 DAG를 실행하기 위한 Python 종속성을 설명합니다.
플러그인 및 요구 사항의 경우 사용할 S3 객체 버전을 선택할 수 있습니다. 사용하는 플러그인이나 요구 사항으로 인해 환경에서 복구 불가능한 오류가 발생하는 경우 Amazon MWAA는 이전 작업 버전으로 자동 롤백됩니다.

[다음(Next)]을 클릭하여 고급 설정을 구성합니다. [네트워킹(Networking)]부터 시작합니다. 각 환경은 2개의 가용 영역에서 프라이빗 서브넷을 사용하여 Amazon Virtual Private Cloud에서 실행됩니다. Airflow UI에 대한 웹 서버 액세스는 항상 AWS Identity and Access Management(IAM)를 사용하여 보안 로그인으로 보호됩니다. 그러나 퍼블릭 네트워크에서 웹 서버 액세스를 허용하도록 선택하여 인터넷이나 VPC의 프라이빗 네트워크에서 로그인할 수도 있습니다. 간단하게 [퍼블릭 네트워크(Public network)]를 선택합니다. Amazon MWAA에서 올바른 인바운드 및 아웃바운드 규칙을 사용하는 새 보안 그룹을 생성합니다. 선택적으로 하나 이상의 기존 보안 그룹을 추가하여 환경에 대한 인바운드 및 아웃바운드 트래픽의 제어를 미세 조정할 수 있습니다.
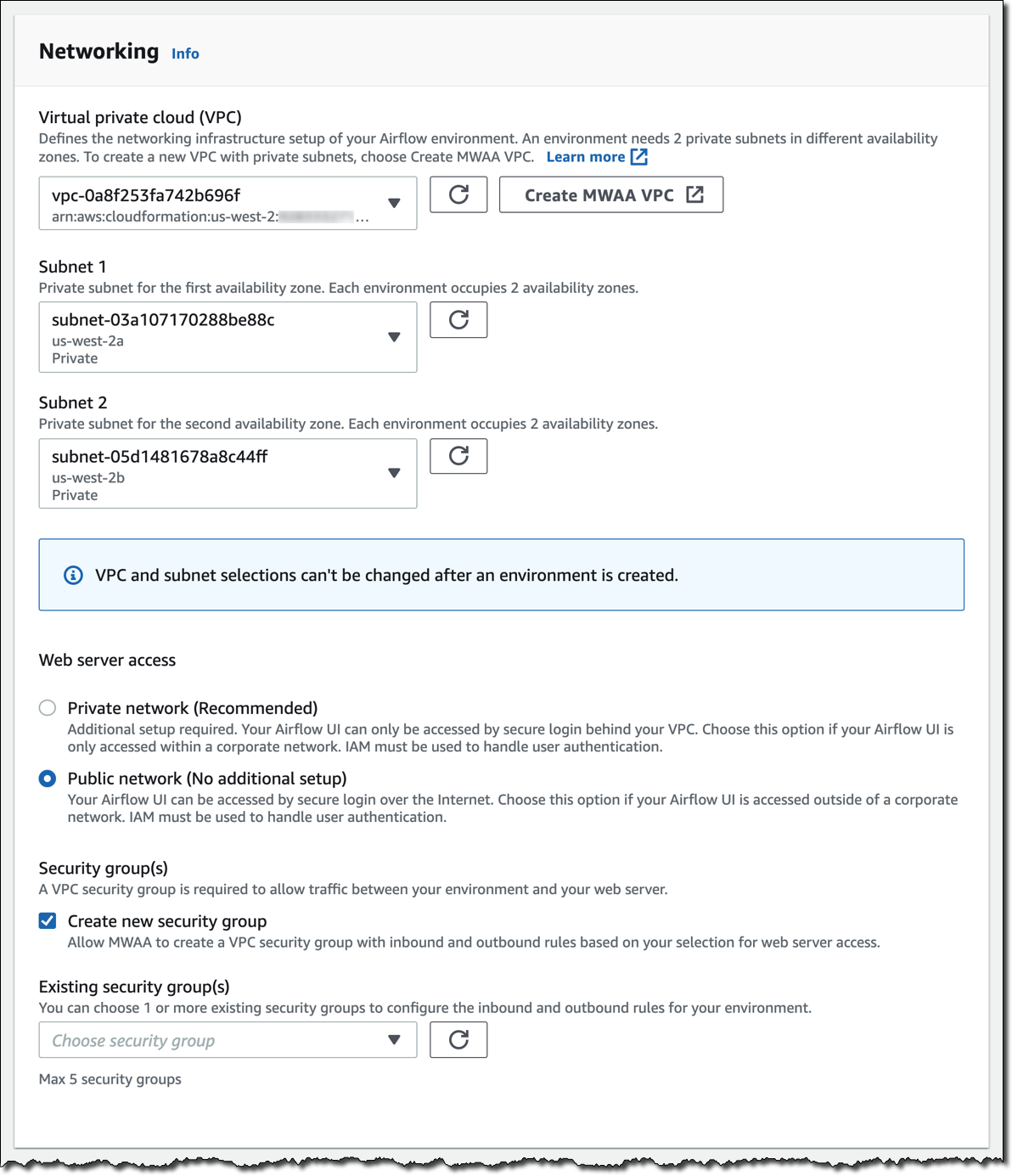
이제 [환경 클래스(Environment class)]를 구성합니다. 각 환경에는 스케줄러, 웹 서버 및 작업자가 포함됩니다. 작업자는 워크로드에 따라 자동으로 확장 및 축소됩니다. DAG의 수에 따라 사용할 클래스에 대한 제안 사항을 제공하지만 언제든지 사용자 환경의 로드를 모니터링하고 클래스를 수정할 수 있습니다.

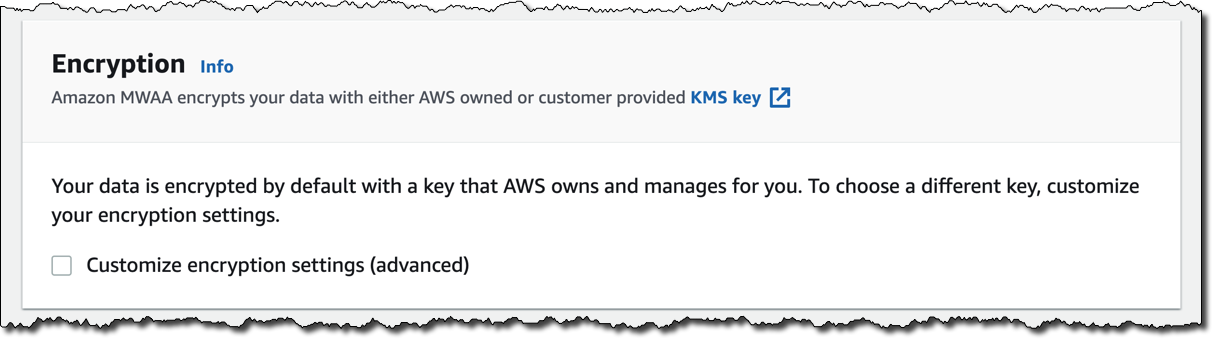
[암호화(Encryption)]는 항상 유휴 데이터에 대해 활성화됩니다. AWS Key Management Service(KMS)에서 관리하는 사용자 지정된 키를 선택할 수 있지만, AWS에서 소유하고 사용자 대신 관리하는 기본 키를 대신 유지하려고 합니다.
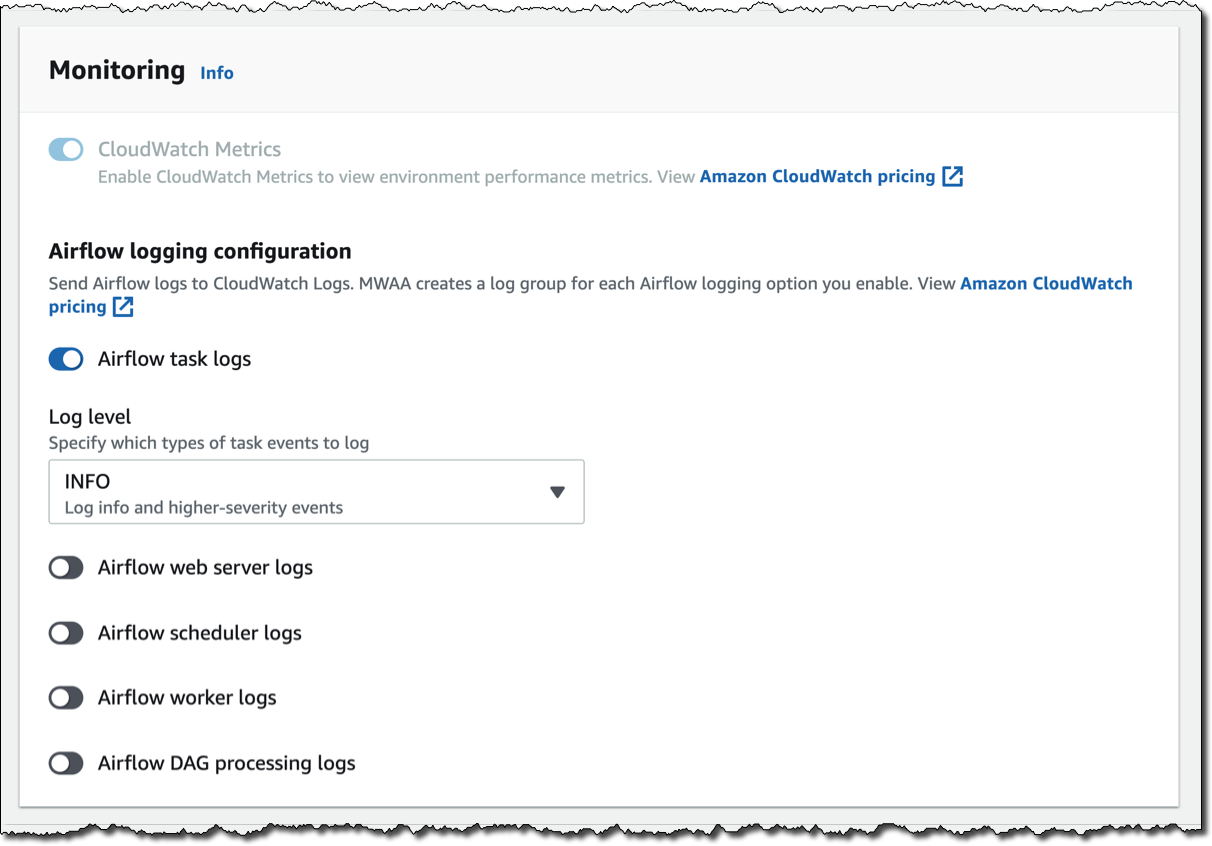
[모니터링(Monitoring)]에서는 CloudWatch 지표로 환경 성능을 게시합니다. 이 기능은 기본적으로 활성화되어 있지만 실행 후 CloudWatch 지표를 비활성화할 수 있습니다. 로그에서는 로그 수준과 CloudWatch Logs에 로그를 전송해야 하는 Airflow 구성 요소를 지정할 수 있습니다. 태스크 로그만 보내는 기본값을 유지하고 로그 수준 INFO를 사용합니다.
default_task_retries 또는 worker_concurrency와 같은 Airflow [구성 옵션(configuration options)]의 기본 설정을 수정할 수 있습니다. 지금은 이러한 값을 변경하지 않습니다.

마지막으로, 가장 중요한 작업은 환경에서 DAG에 액세스하고, 로그를 작성하며, 다른 AWS 리소스에 액세스하는 DAG를 실행하는 데 사용할 권한을 구성하는 것입니다. [새 역할 생성(Create a new role)]을 선택하고 [환경 생성(Create environment)]을 클릭합니다. 몇 분 후 새로운 Airflow 환경을 사용할 준비가 됩니다.

Airflow UI 사용
Amazon MWAA 콘솔에서 방금 생성한 새 환경을 찾아 [Airflow UI 열기(Open Airflow UI)]를 클릭합니다. 새 브라우저 창이 생성되고 AWS IAM을 통한 보안 로그인으로 인증됩니다.
여기에서 movie_list_dag.py 파일에서 S3에 넣은 DAG를 찾습니다. DAG는 MovieLens 데이터 세트를 다운로드하고 Amazon Athena를 사용하여 S3에서 파일을 처리하며 결과를 Redshift 클러스터에 로드하고 누락된 경우 테이블을 생성합니다.
다음은 DAG의 전체 소스 코드입니다.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators import HttpSensor, S3KeySensor
from airflow.contrib.operators.aws_athena_operator import AWSAthenaOperator
from airflow.utils.dates import days_ago
from datetime import datetime, timedelta
from io import StringIO
from io import BytesIO
from time import sleep
import csv
import requests
import json
import boto3
import zipfile
import io
s3_bucket_name = 'my-bucket'
s3_key='files/'
redshift_cluster='my-redshift-cluster'
redshift_db='dev'
redshift_dbuser='awsuser'
redshift_table_name='movie_demo'
test_http='https://grouplens.org/datasets/movielens/latest/'
download_http='http://files.grouplens.org/datasets/movielens/ml-latest-small.zip'
athena_db='demo_athena_db'
athena_results='athena-results/'
create_athena_movie_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS Demo_Athena_DB.ML_Latest_Small_Movies (
`movieId` int,
`title` string,
`genres` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://my-bucket/files/ml-latest-small/movies.csv/ml-latest-small/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
"""
create_athena_ratings_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS Demo_Athena_DB.ML_Latest_Small_Ratings (
`userId` int,
`movieId` int,
`rating` int,
`timestamp` bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://my-bucket/files/ml-latest-small/ratings.csv/ml-latest-small/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
"""
create_athena_tags_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS Demo_Athena_DB.ML_Latest_Small_Tags (
`userId` int,
`movieId` int,
`tag` int,
`timestamp` bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://my-bucket/files/ml-latest-small/tags.csv/ml-latest-small/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
"""
join_tables_athena_query="""
SELECT REPLACE ( m.title , '"' , '' ) as title, r.rating
FROM demo_athena_db.ML_Latest_Small_Movies m
INNER JOIN (SELECT rating, movieId FROM demo_athena_db.ML_Latest_Small_Ratings WHERE rating > 4) r on m.movieId = r.movieId
"""
def download_zip():
s3c = boto3.client('s3')
indata = requests.get(download_http)
n=0
with zipfile.ZipFile(io.BytesIO(indata.content)) as z:
zList=z.namelist()
print(zList)
for i in zList:
print(i)
zfiledata = BytesIO(z.read(i))
n += 1
s3c.put_object(Bucket=s3_bucket_name, Key=s3_key+i+'/'+i, Body=zfiledata)
def clean_up_csv_fn(**kwargs):
ti = kwargs['task_instance']
queryId = ti.xcom_pull(key='return_value', task_ids='join_athena_tables' )
print(queryId)
athenaKey=athena_results+"join_athena_tables/"+queryId+".csv"
print(athenaKey)
cleanKey=athena_results+"join_athena_tables/"+queryId+"_clean.csv"
s3c = boto3.client('s3')
obj = s3c.get_object(Bucket=s3_bucket_name, Key=athenaKey)
infileStr=obj['Body'].read().decode('utf-8')
outfileStr=infileStr.replace('"e"', '')
outfile = StringIO(outfileStr)
s3c.put_object(Bucket=s3_bucket_name, Key=cleanKey, Body=outfile.getvalue())
def s3_to_redshift(**kwargs):
ti = kwargs['task_instance']
queryId = ti.xcom_pull(key='return_value', task_ids='join_athena_tables' )
print(queryId)
athenaKey='s3://'+s3_bucket_name+"/"+athena_results+"join_athena_tables/"+queryId+"_clean.csv"
print(athenaKey)
sqlQuery="copy "+redshift_table_name+" from '"+athenaKey+"' iam_role 'arn:aws:iam::163919838948:role/myRedshiftRole' CSV IGNOREHEADER 1;"
print(sqlQuery)
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
DbUser=redshift_dbuser,
Sql=sqlQuery
)
print(resp)
return "OK"
def create_redshift_table():
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
DbUser=redshift_dbuser,
Sql="CREATE TABLE IF NOT EXISTS "+redshift_table_name+" (title character varying, rating int);"
)
print(resp)
return "OK"
DEFAULT_ARGS = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False
}
with DAG(
dag_id='movie-list-dag',
default_args=DEFAULT_ARGS,
dagrun_timeout=timedelta(hours=2),
start_date=days_ago(2),
schedule_interval='*/10 * * * *',
tags=['athena','redshift'],
) as dag:
check_s3_for_key = S3KeySensor(
task_id='check_s3_for_key',
bucket_key=s3_key,
wildcard_match=True,
bucket_name=s3_bucket_name,
s3_conn_id='aws_default',
timeout=20,
poke_interval=5,
dag=dag
)
files_to_s3 = PythonOperator(
task_id="files_to_s3",
python_callable=download_zip
)
create_athena_movie_table = AWSAthenaOperator(task_id="create_athena_movie_table",query=create_athena_movie_table_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'create_athena_movie_table')
create_athena_ratings_table = AWSAthenaOperator(task_id="create_athena_ratings_table",query=create_athena_ratings_table_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'create_athena_ratings_table')
create_athena_tags_table = AWSAthenaOperator(task_id="create_athena_tags_table",query=create_athena_tags_table_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'create_athena_tags_table')
join_athena_tables = AWSAthenaOperator(task_id="join_athena_tables",query=join_tables_athena_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'join_athena_tables')
create_redshift_table_if_not_exists = PythonOperator(
task_id="create_redshift_table_if_not_exists",
python_callable=create_redshift_table
)
clean_up_csv = PythonOperator(
task_id="clean_up_csv",
python_callable=clean_up_csv_fn,
provide_context=True
)
transfer_to_redshift = PythonOperator(
task_id="transfer_to_redshift",
python_callable=s3_to_redshift,
provide_context=True
)
check_s3_for_key >> files_to_s3 >> create_athena_movie_table >> join_athena_tables >> clean_up_csv >> transfer_to_redshift
files_to_s3 >> create_athena_ratings_table >> join_athena_tables
files_to_s3 >> create_athena_tags_table >> join_athena_tables
files_to_s3 >> create_redshift_table_if_not_exists >> transfer_to_redshift코드에서는 일반 Python 코드를 위한 PythonOperator 또는 Amazon Athena와의 통합을 사용하기 위한 AWSAthenaOperator와 같은 연산자를 사용하여 다른 태스크가 생성됩니다. 이러한 태스크가 워크플로에서 연결된 방식을 보려면 최근 몇 개 줄을 보면 됩니다. 간단하게 여기에 들여쓰지 않고 반복합니다.
check_s3_for_key >> files_to_s3 >> create_athena_movie_table >> join_athena_tables >> clean_up_csv >> transfer_to_redshift
files_to_s3 >> create_athena_ratings_table >> join_athena_tables
files_to_s3 >> create_athena_tags_table >> join_athena_tables
files_to_s3 >> create_redshift_table_if_not_exists >> transfer_to_redshiftAirflow 코드는 Python에서 오른쪽 시프트 >> 연산자를 오버로드하여 종속성을 생성합니다. 즉, 왼쪽의 태스크가 먼저 실행되고 출력이 오른쪽의 태스크로 전달되어야 합니다. 코드를 살펴보면 꽤 쉽게 파악할 수 있습니다. 위의 각 4개 줄에서는 종속성을 추가하고 있으며, 올바른 순서로 태스크를 실행하기 위해 모두 함께 평가됩니다.
Airflow 콘솔에서 DAG의 그래프 보기를 보고 태스크 실행 방식을 명확하게 표현할 수 있습니다.

정식 출시
Amazon Managed Workflows for Apache Airflow(MWAA)는 오늘 미국 동부(버지니아 북부), 미국 서부(오레곤), 미국 동부(오하이오), 아시아 태평양(싱가포르), 아시아 태평양(도쿄), 아시아 태평양(시드니), EU(아일랜드), EU(프랑크푸르트), EU(스톡홀름)에서 정식 출시되었습니다. 콘솔, AWS 명령줄 인터페이스(CLI) 또는 AWS SDK에서 새 Amazon MWAA 환경을 시작할 수 있습니다. 그런 다음, Airflow의 통합 에코시스템을 사용하여 Python에서 워크플로를 개발할 수 있습니다.
Amazon MWAA에서는 사용자가 사용하는 환경 클래스 및 작업자에 기반하여 비용을 지불합니다. 자세한 내용은 요금 페이지를 참조하세요.
업스트림 호환성은 Amazon MWAA의 주요 원칙입니다. AirFlow 플랫폼에 대한 코드가 변경되는 경우 오픈 소스로 다시 출시됩니다.
Amazon MWAA를 통해 엔지니어링 및 데이터 과학 태스크를 위한 워크플로를 구축하는 데 더 많은 시간을 할애할 수 있고, Airflow 플랫폼의 인프라를 관리하고 확장하는 시간을 줄일 수 있습니다.
Update – 2021년 8월 31일 아시아태평양 (서울) 리전에서도 정식 출시하였습니다.
— Danilo