O blog da AWS
AWS serverless data analytics – arquitetura de referência
Por Praful Kava, Sr. Specialist Solutions Architect na AWS e
Changbin Gong é Senior Solutions Architect na AWS
O onboarding de novos dados ou a construção de novos pipelines de analytics em arquiteturas de análise tradicionais normalmente requer uma coordenação extensiva entre as equipes de negócios, engenharia de dados e ciência de dados e analytics para primeiro negociar requisitos, schema, necessidades de capacidade de infraestrutura e gerenciamento de workloads.
Para um grande número de casos de uso hoje, no entanto, usuários de negócios, cientistas de dados e analytics estão exigindo opções fáceis, sem atrito e de autoatendimento para construir pipelines de dados de ponta a ponta, porque é difícil e ineficiente para predefinir schemas com mudanças constantes e gastar tempo negociando slots de capacidade em infraestrutura compartilhada. A natureza exploratória do aprendizado de máquina (ML) e muitas tarefas de análise significa que você precisa ingerir rapidamente novos conjuntos de dados e limpá-los, normalizá-los e engessá-los sem se preocupar com sobrecarga operacional quando você tem que pensar sobre a infraestrutura que executa os pipelines de dados.
Uma arquitetura de data lake serverless permite onboarding e análise de dados ágeis e de autoatendimento para todas as funções de consumidores de dados em uma empresa. Usando tecnologias serverless AWS como building blocks, você pode construir rapidamente e interativamente data lakes e pipelines de processamento de dados para ingerir, armazenar, transformar e analisar petabytes de dados estruturados e não estruturados de fontes lote e streaming, tudo sem precisar gerenciar qualquer infraestrutura de armazenamento ou computação.
Neste post, primeiro discutiremos uma arquitetura lógica em camadas e orientada a componentes de plataformas de análise modernas e, em seguida, apresentaremos uma arquitetura de referência para a construção de uma plataforma de dados serverless que inclui um data lake, pipelines de processamento de dados e uma camada de consumo que permite analisar vários data lakes sem movê-lo (incluindo o dashboarding de business intelligence (BI), SQL interativo exploratório, processamento de big data, análise preditiva e ML).
Arquitetura lógica de plataformas modernas de análise centrada em data lakes
O diagrama a seguir ilustra a arquitetura de uma plataforma de análise centrada em data lake.
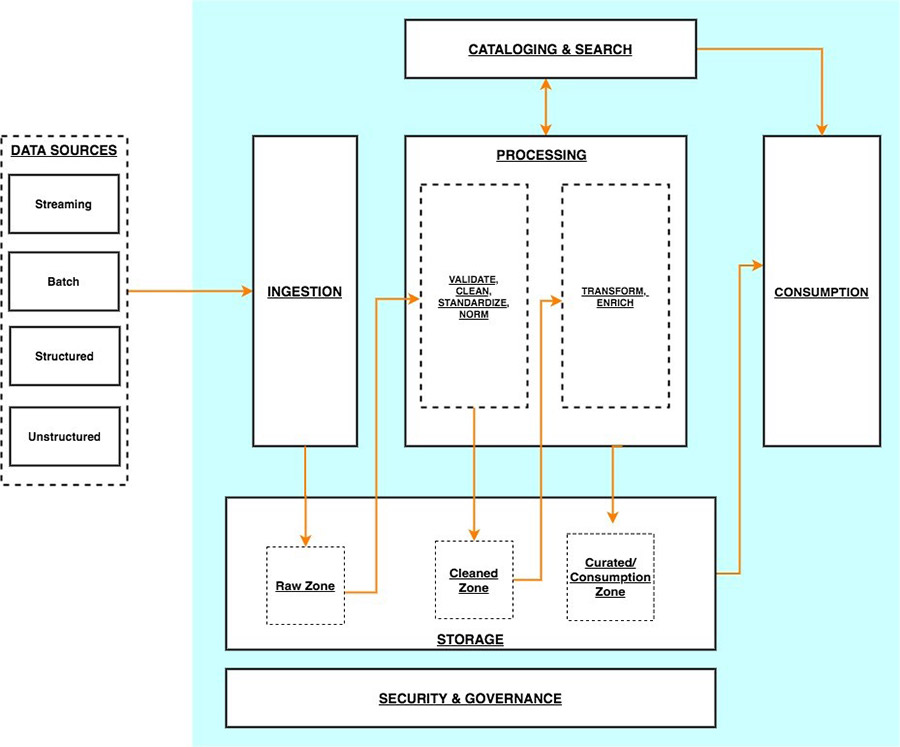
Você pode imaginar uma arquitetura de análise centrada em data lake como uma pilha de seis camadas lógicas, onde cada camada é composta de múltiplos componentes. Uma arquitetura em camadas e orientada a componentes promove a separação de domínios, a dissociação de tarefas e a flexibilidade. Estes, por sua vez, fornecem a agilidade necessária para integrar rapidamente novas fontes de dados, apoiar novos métodos de análise e adicionar ferramentas necessárias para acompanhar o ritmo acelerado de mudanças no cenário de análise. Nas seções a seguir, analisamos as principais responsabilidades, capacidades e integrações de cada camada lógica.
Camada de ingestão
A camada de ingestão é responsável por trazer dados para o data lake. Ele fornece a capacidade de se conectar a fontes de dados internas e externas ao longo de uma variedade de protocolos. Ele pode ingerir dados em batch e streaming na camada de armazenamento. A camada de ingestão também é responsável por fornecer dados ingeridos a um conjunto diversificado de alvos na camada de armazenamento de dados (incluindo object store, bancos de dados e warehouses).
Camada de armazenamento
A camada de armazenamento é responsável por fornecer componentes duráveis, escaláveis, seguros e econômicos para armazenar grandes quantidades de dados. Ele suporta armazenar dados e conjuntos de dados não estruturados de uma variedade de estruturas e formatos. Ele suporta armazenar dados de origem sem antes precisar estruturá-los para se adequar a um schema ou formato de destino. Componentes de todas as outras camadas proporcionam uma integração fácil e nativa com a camada de armazenamento. Para armazenar dados com base em sua prontidão de consumo para diferentes pessoas em toda a organização, a camada de armazenamento é organizada nas seguintes zonas:
- Raw zone – Área de armazenamento onde os componentes da camada de ingestão entregam dados. Esta é uma área transitória onde os dados são ingeridos são ingeridos como estão a partir de fontes. Normalmente, pessoas de engenharia de dados interagem com os dados armazenados nesta região.
- Cleaned zone – Após as verificações preliminares de qualidade, os dados da zona bruta (raw zone são movidos para a cleaned zone para armazenamento permanente. Aqui, os dados são armazenados em seu formato original. Ter todos os dados de todas as fontes armazenadas permanentemente na cleaned zone fornece a capacidade de “reproduzir” o processamento de dados downstream em caso de erros ou perda de dados em zonas de armazenamento downstream. Normalmente, as pessoas de engenharia de dados e ciência de dados interagem com os dados armazenados nesta região.
- Curated zone – Esta região hospeda dados que estão quase prontos para consumo e estão em conformidade com padrões organizacionais e modelos de dados. Os conjuntos de dados na curated zone são tipicamente particionados, catalogados e armazenados em formatos que suportam acesso performático e econômico pela camada de consumo. A camada de processamento cria conjuntos de dados na curated zone após a limpeza, normalização, padronização e enriquecimento de dados da zona bruta. Todas as pessoas entre as organizações usam os dados armazenados nesta zona para impulsionar as decisões de negócios.
Camada de catalogação e pesquisa
A camada de catalogação e pesquisa é responsável por armazenar metadados comerciais e técnicos sobre conjuntos de dados hospedados na camada de armazenamento. Ele fornece a capacidade de rastrear o schema e a partição granular de informações de conjunto de dados no data lake. Ele também suporta mecanismos para rastrear versões para acompanhar as alterações nos metadados. À medida que o número de conjuntos de dados no data lake cresce, essa camada faz com que conjuntos de dados no data lake sejam detectáveis, fornecendo recursos de pesquisa.
Camada de processamento
A camada de processamento é responsável por transformar os dados em um estado consumível por meio da validação, limpeza, normalização, transformação e enriquecimento de dados. É responsável por avançar na prontidão de consumo dos conjuntos de dados ao longo das landing zones, raw e curated e registrar metadados para os dados brutos e transformados na camada de catalogação. A camada de processamento é composta por componentes de processamento de dados construídos com propósito para corresponder à característica de conjunto de dados e tarefa de processamento correta em mãos. A camada de processamento pode lidar com grandes volumes de dados e suportar dados particionados e formatos de dados diversos. A camada de processamento também fornece a capacidade de construir e orquestrar pipelines de processamento de dados em várias etapas que usam componentes construídos com propósito para cada etapa.
Camada de consumo
A camada de consumo é responsável por fornecer ferramentas escaláveis e performáticas para obter insights da vasta quantidade de dados no data lake. Ele democratiza as análises para todas as pessoas da organização através de várias ferramentas de análise criadas com propósito que suportam métodos de análise, incluindo SQL, análise em lote, painéis de BI, relatórios e ML. A camada de consumo se integra nativamente com as camadas de armazenamento, catalogação e segurança do data lake. Os componentes da camada de consumo suportam o schema de leitura, uma variedade de estruturas e formatos de dados e usam partição de dados para otimização de custos e desempenho.
Camada de segurança e governança
A camada de segurança e governança é responsável por proteger os dados na camada de armazenamento e recursos de processamento em todas as outras camadas. Ele fornece mecanismos para controle de acesso, criptografia, proteção de rede, monitoramento de uso e auditoria. A camada de segurança também monitora as atividades de todos os componentes em outras camadas e gera uma trilha de auditoria detalhada. Componentes de todas as outras camadas fornecem integração nativa com a camada de segurança e governança.
Arquitetura de análise centrada no data lake serverless
Para compor as camadas descritas em nossa arquitetura lógica, introduzimos uma arquitetura de referência que usa serviços serverless e gerenciados pela AWS. Nesta abordagem, os serviços da AWS assumem o trabalho de:
- Fornecer e gerenciar componentes de infraestrutura escaláveis, resilientes, seguros e econômicos
- Garantir que os componentes de infraestrutura se integrem nativamente uns aos outros
Essa arquitetura de referência permite que você se concentre mais tempo na construção rápida de dados e pipelines de análise. Ele acelera significativamente o onboarding de novos dados impulsionando insights de seus dados. Os componentes serverless e gerenciados da AWS permitem o autoatendimento em todos os consumidores de dados, fornecendo os seguintes principais benefícios:
- Fácil uso orientado à configuração
- Liberdade da gestão de infraestrutura
- Modelo de preços pay-per-use (pague pelo uso)
O diagrama a seguir ilustra essa arquitetura.
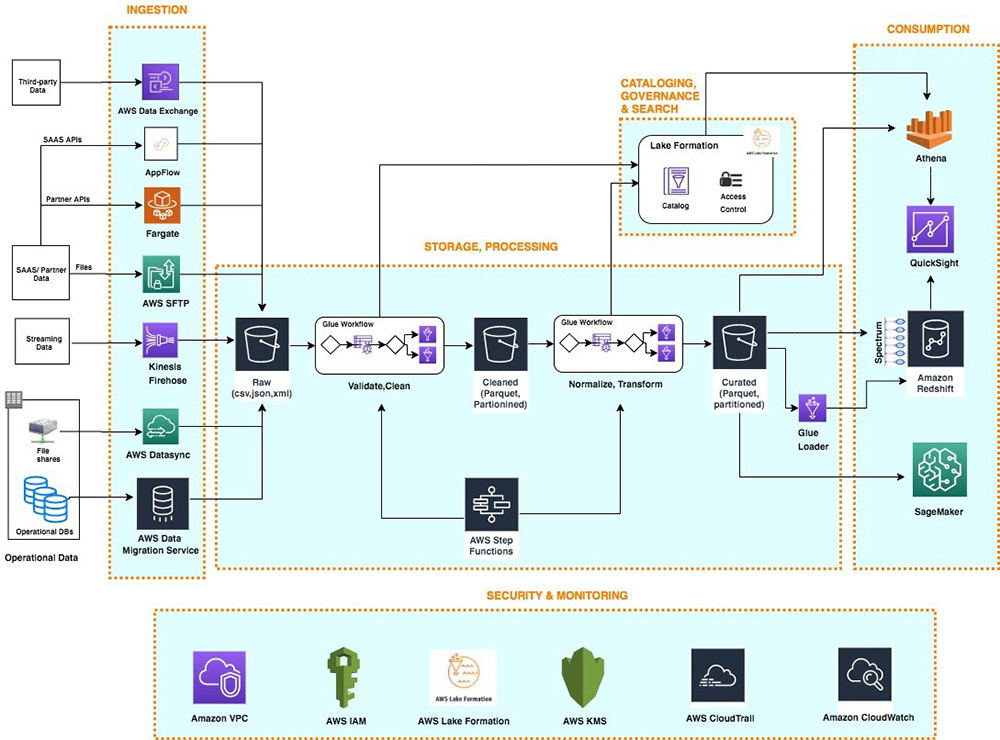
Camada de ingestão
A camada de ingestão em nossa arquitetura serverless é composta por um conjunto de serviços AWS construídos com propósito para permitir a ingestão de dados de uma variedade de fontes. Cada um desses serviços permite a simples ingestão de dados por autoatendimento na landing zone do data lake e fornece integração com outros serviços AWS nas camadas de armazenamento e segurança. Os serviços AWS construídos com propósito individual correspondem aos requisitos exclusivos de conectividade, formato de dados, estrutura de dados e velocidade de dados de fontes operacionais de banco de dados, fontes de dados de streaming e fontes de arquivo.
Fontes operacionais de banco de dados
Normalmente, as organizações armazenam seus dados operacionais em várias bases de dados relacionais e noSQL. (AWS DMS) pode se conectar a uma variedade de bancos de dados operacionais RDBMS e NoSQL e ingerir seus dados em buckets do Amazon Simple Storage Service (Amazon S3) na landing zone do data lake. Com o AWS DMS, você pode primeiro realizar uma importação única dos dados de origem para o data lake e replicar mudanças contínuas acontecendo no banco de dados de origem. O AWS DMS criptografa objetos S3 usando chaves AWS Key Management Service (AWS KMS) enquanto os armazena no data lake. O AWS DMS é um serviço totalmente gerenciado e resiliente e fornece uma ampla escolha de tamanhos de instância para hospedar tarefas de replicação de banco de dados.
O fornece uma alternativa escalável e serverless, chamada de blueprints, para ingerir dados de fontes de banco de dados nativas AWS ou on-premises na landing zone do data lake. Uma blueprint do Lake Formation é um modelo predefinido que gera um fluxo de trabalho do AWS Glue baseado em parâmetros de entrada, como banco de dados de origem, local do Amazon S3 de destino, formato do conjunto de dados de destino, colunas de partição do conjunto de dados de destino e cronograma. Um fluxo de trabalho no AWS Glue gerado por uma blueprint implementa um pipeline de ingestão de dados otimizado e paralelizado, composto por crawlers, vários trabalhos paralelos e gatilhos conectando-os com base em condições. Para obter mais informações, consulte o blog Integrating AWS Lake Formation with Amzon RDS for SQL Server.
Fontes de dados de streaming
A camada de ingestão usa o Amazon Kinesis Data Firehose para receber dados de streaming de fontes internas e externas. Com alguns cliques, você pode configurar um ponto final da API do Kinesis Data Firehose, onde as fontes podem enviar dados de streaming, como clickstreams, registros de aplicativos e infraestrutura e métricas de monitoramento, e dados de IoT, como telemetria de dispositivos e leituras de sensores. O Kinesis Data Firehose faz o seguinte:
- Buffers de entrada de fluxos
- Loteia, comprime, transforma e criptografa os fluxos
- Armazena os streams como objetos S3 na landing zone do data lake
O Kinesis Data Firehose se integra nativamente com as camadas de segurança e armazenamento e pode fornecer dados para o Amazon S3, Amazon OpenSearch Service (sucessor do Amazon Elasticsearch Service) para casos de uso de análise em tempo real. O Kinesis Data Firehose é serverless, não requer administração e tem um modelo de custo onde você paga apenas pelo volume de dados que transmite e processa através do serviço. O Kinesis Data Firehose escala automaticamente para ajustar ao volume e throughput de dados recebidos.
Fontes de arquivo
Muitos aplicativos armazenam dados estruturados e não estruturados em arquivos que estão hospedados nos arrays NAS (Network Attached Storage – armazenamento conectado à rede). As organizações também recebem arquivos de dados de parceiros e fornecedores de terceiros. Analisar dados dessas fontes de arquivo pode fornecer informações valiosas sobre os negócios.
Compartilhamento de arquivos internos
O AWS DataSync pode ingerir centenas de terabytes e milhões de arquivos de dispositivos NFS e SMB com NAS habilitado para a landing zone do data lake. O DataSync lida automaticamente com a criação do script de trabalho de cópia, agendamento e monitoramento de transferências, validando a integridade dos dados e otimizando a utilização da rede. O DataSync pode realizar transferências de arquivos únicas e monitorar e sincronizar arquivos alterados no data lake. O DataSync é totalmente gerenciado e pode ser configurado em minutos.
Arquivos de dados de parceiros
FTP é o método mais comum para trocar arquivos de dados com parceiros. O AWS Transfer Family é um serviço serverless, altamente disponível e escalável que suporta endpoints FTP seguros e se integra nativamente com o Amazon S3. Parceiros e fornecedores transmitem arquivos usando o protocolo SFTP, e o AWS Transfer Family os armazena como objetos S3 na landing zone no data lake. O AWS Transfer Family suporta criptografia usando AWS KMS e métodos comuns de autenticação, incluindo da AWS e o Active Directory.
APIs de dados
As organizações hoje usam SaaS e aplicativos parceiros, como Salesforce, Marketo e Google Analytics, para apoiar suas operações de negócios. Analisar dados de SaaS e parceiros em conjunto com dados internos de aplicativos operacionais é fundamental para obter insights de negócios de 360 graus. Os aplicativos de parceiros e SaaS geralmente fornecem endpoints de API para compartilhar dados.
APIs de SAAS
A camada de ingestão usa o AWS AppFlow para ingerir facilmente dados de aplicativos SaaS no data lake. Com alguns cliques, você pode configurar fluxos de ingestão de dados serverless no AppFlow. Seus fluxos podem se conectar a aplicativos SaaS (como SalesForce, Marketo e Google Analytics), ingerir dados e armazená-los no data lake. Você pode agendar fluxos de ingestão de dados do AppFlow ou acioná-los por eventos no aplicativo SaaS. Os dados ingeridos podem ser validados, filtrados, mapeados e mascarados antes de armazenar no data lake. O AppFlow integra-se nativamente com serviços de autenticação, autorização e criptografia na camada de segurança e governança.
APIs de parceiros
Para ingerir dados de APIs de parceiros e terceiros, as organizações constroem ou compram aplicações personalizadas que se conectam a APIs, buscam dados e criam objetos S3 na landing zone usando SDKs AWS. Essas aplicações e suas dependências podem ser empacotadas em contêineres Docker e hospedados no AWS Fargate. Fargate é um mecanismo de computação serverless para hospedar contêineres Docker sem a necessidade de provisionar, gerenciar e escalar servidores. O Fargate integra-se nativamente com os serviços de segurança e monitoramento da AWS para fornecer criptografia, autorização, isolamento de rede, logs e monitoramento dos contêineres das aplicações.
Os trabalhos de shell do Python no AWS Glue também fornecem alternativas serverless para construir e agendar trabalhos de ingestão de dados que podem interagir com APIs parceiras usando bibliotecas Python nativas, de código aberto ou fornecidas por parceiros. O AWS Glue fornece recursos fora da caixa para agendar trabalhos únicos de shell Python ou incluí-los como parte de um fluxo de trabalho de ingestão de dados mais complexo construído nos fluxos de trabalho do AWS Glue.
Fontes de dados de terceiros
Sua organização pode ganhar uma vantagem nos negócios combinando seus dados internos com conjuntos de dados de terceiros, como dados históricos, dados meteorológicos e dados de comportamento do consumidor. O AWS Data Exchange fornece uma maneira serverless de encontrar, increver-se e ingerir dados de terceiros diretamente em buckets S3 na landing zone do data lake. Você pode ingerir um conjunto de dados completo de terceiros e, em seguida, automatizar a detecção e ingestão de revisões para esse conjunto de dados. O AWS Data Exchange é serverless e permite encontrar e ingerir conjuntos de dados de terceiros com alguns cliques.
Camada de armazenamento
O Amazon S3 fornece a base para a camada de armazenamento em nossa arquitetura. O Amazon S3 fornece escalabilidade praticamente ilimitada a baixo custo para o nosso data lake serverless. Os dados são armazenados como objetos S3 organizados em buckets das landing, raw e curated zones, e prefixos. O Amazon S3 criptografa dados usando chaves gerenciadas no AWS KMS. As políticas do IAM controlam o acesso granular no nível de zona e dataset para vários usuários e funções. O Amazon S3 oferece 99,99 % de disponibilidade e 99,99999999999 % de durabilidade, e cobra apenas pelos dados que armazena. Para reduzir significativamente os custos, o Amazon S3 oferece opções de armazenamento de nível mais frio chamadas Amazon S3 Glacier e S3 Glacier Deep Archive. Para automatizar otimizações de custos, o Amazon S3 oferece políticas de ciclo de vida configuráveis e opções inteligentes de hierarquização para automatizar a movimentação de dados mais antigos para níveis mais frios. Os serviços AWS em nossas camadas de ingestão, catalogação, processamento e consumo podem ler e escrever objetos S3 nativamente. Além disso, centenas de fornecedores e serviços de código aberto fornecem a capacidade de ler e escrever objetos no S3.
Dados de qualquer estrutura (incluindo dados não estruturados) e qualquer formato podem ser armazenados como objetos no S3 sem a necessidade de predefinir qualquer schema. Isso permite que os serviços na camada de ingestão entreguem rapidamente uma variedade de dados de origem no data lake em seu formato de origem original. Depois que os dados são ingeridos no data lake, os componentes na camada de processamento podem definir o schema em cima dos conjuntos de dados S3 e registrá-los na camada de catalogação. Os serviços nas camadas de processamento e consumo podem então usar o schema na leitura para aplicar a estrutura necessária aos dados lidos a partir de objetos no S3. Os conjuntos de dados armazenados no Amazon S3 são frequentemente particionados para permitir filtragem eficiente por serviços nas camadas de processamento e consumo.
Camada de catalogação e pesquisa
Um data lake normalmente hospeda um grande número de conjuntos de dados, e muitos desses conjuntos de dados têm schemas em evolução e novas partições de dados. Um catálogo de dados central que gerencia metadados para todos os conjuntos de dados no data lake é crucial para permitir a descoberta de dados por autoatendimento no data lake. Além disso, a separação de metadados de dados em um schema central permite a utilização de schema somente na leitura para os componentes da camada de processamento e consumo.
Em nossa arquitetura, o Lake Formation fornece o catálogo central para armazenar e gerenciar metadados para todos os conjuntos de dados hospedados no data lake. As organizações gerenciam tanto metadados técnicos (como schemas de tabelas versionados, informações de particionamento, localização de dados físicos e datates de atualização) quanto atributos de negócios (como proprietário de dados, administrador de dados, definição de negócios de colunas e sensibilidade à informação da coluna) de todos os seus conjuntos de dados no Lake Formation. Serviços como AWS Glue, Amazon EMRe Amazon Athena integram-se nativamente ao Lake Formation e automatizam a descoberta e o registro de metadados de conjunto de dados no catálogo do Lake Formation. Além disso, o Lake Formation fornece APIs para permitir o registro e o gerenciamento de metadados usando scripts personalizados e produtos de terceiros. Os crawlers do AWS Glue na camada de processamento podem rastrear schemas em evolução e partições recém-adicionadas de conjuntos de dados no data lake, e adicionar novas versões de metadados correspondentes no catálogo do Lake Formation.
O Lake Formation fornece ao administrador do data lake um local central para configurar permissões granulares em nível de tabela e coluna para bancos de dados e tabelas hospedadas no data lake. Após a configuração das permissões do Lake Formation, os usuários e grupos podem acessar apenas tabelas e colunas autorizadas usando vários serviços da camada de processamento e consumo, como o Athena, Amazon EMR, AWS Glue e Amazon Redshift Spectrum.
Camada de processamento
A camada de processamento em nossa arquitetura é composta por dois tipos de componentes:
- Componentes usados para criar pipelines de processamento de dados em várias etapas
- Componentes para orquestrar pipelines de processamento de dados no cronograma ou em resposta aos gatilhos de eventos (como a ingestão de novos dados na landing zone)
As funções do AWS Glue e AWS Step Functions fornecem componentes serverless para construir, orquestrar e executar pipelines que podem facilmente dimensionar para processar grandes volumes de dados. Os fluxos de trabalho de várias etapas construídos usando o AWS Glue e Step Functions podem catalogar, validar, limpar, transformar e enriquecer conjuntos de dados individuais e avançar de landing zones para raw zones e de raw para curated zones na camada de armazenamento.
O AWS Glue é um serviço ETL serverless e pago por uso para construir e executar trabalhos Python ou Spark (escritos em Scala ou Python) sem exigir que você implante ou gerencie clusters. O AWS Glue gera automaticamente o código para acelerar suas transformações de dados e processos de carregamento. O AWS Glue ETL é construído em cima do Apache Spark e fornece conectores de origem de dados, dados e transformações de ETL comumente usados para validar, limpar, transformar e achatar dados armazenados em muitos formatos de código aberto, como CSV, JSON, Parquet e Avro. O AWS Glue ETL também fornece recursos para processar
Além disso, você pode usar o AWS Glue para definir e executar crawlers que podem rastrear pastas no data lake, descobrir conjuntos de dados e suas partições, inferir schema e definir tabelas no catálogo do Lake Formation. O AWS Glue fornece mais de uma dúzia de classificadores incorporados que podem analisar uma variedade de estruturas de dados armazenadas em formatos de código aberto. O AWS Glue também fornece gatilhos e recursos de fluxo de trabalho que você pode usar para construir pipelines de processamento de dados de várias etapas que incluem dependências de trabalho e execução paralela de etapas. Você pode agendar trabalhos e fluxos de trabalho do AWS Glue ou executá-los sob demanda. O AWS Glue integra-se nativamente com os serviços AWS em camadas de armazenamento, catálogo e segurança.
Step Functions é um mecanismo serverless que você pode usar para construir e orquestrar fluxos de trabalho de processamento de dados programados ou orientados a eventos. Você usa Step Functions para construir pipelines complexos de processamento de dados que envolvem medidas orquestradoras implementadas usando vários serviços AWS, como AWS Glue, AWS Lambda, Amazon Elastic Container Service (Amazon ECS) e muito mais. As Step Functions fornecem representações visuais de fluxos de trabalho complexos e seu estado de execução para torná-los fáceis de entender. Ele gerencia o estado, os pontos de verificação e a reinicialização do fluxo de trabalho para que você se certifique de que as etapas do seu pipeline de dados sejam executadas em ordem e como esperado. Os recursos de try/catch, retry e rollback incorporados lidam automaticamente com erros e exceções.
Camada de consumo
A camada de consumo em nossa arquitetura é composta usando serviços de análise totalmente gerenciados, construídos com propósito, que permitem SQL interativo, dashboards de BI, processamento em batch e ML.
SQL interativo
Athena é um serviço de consulta interativo que permite executar ANSI SQL complexas contra terabytes de dados armazenados no Amazon S3 sem precisar primeiro carregá-los em um banco de dados. As consultas do Athena podem analisar dados estruturados, semiestruturados e colunares armazenados em formatos de código aberto, como CSV, JSON, XML Avro, Parquet e ORC. O Athena usa definições de tabela do Lake Formation para aplicar a utilização de schema somente na leitura aos dados lidos do Amazon S3.
O Athena é serverless, então não há infraestrutura para configurar ou gerenciar, e você paga apenas pela quantidade de dados inspecionados pelas consultas que você executa. O Athena fornece resultados mais rápidos e custos mais baixos, através da redução da quantidade de dados que inspeciona usando armazenadas no catálogo do Lake Formation. Você pode executar consultas diretamente no console do Athena e enviá-las usando endpoints Athena JDBC ou ODBC.
O Athena integra-se nativamente com os serviços AWS na camada de segurança e monitoramento para apoiar a autenticação, autorização, criptografia, registro e monitoramento. Suporta controles de acesso em nível de tabela e coluna definidos no catálogo do Lake Formation.
Armazenagem de dados e análises em lote
Amazon Redshift é um serviço de data warehouse totalmente gerenciado que pode hospedar e processar petabytes de dados e executar milhares de consultas altamente performáticas em paralelo. O Amazon Redshift usa um conjunto de nós de computação para executar consultas de baixa latência para alimentar painéis interativos e análises em lote de alto throughput para impulsionar decisões de negócios. Você pode executar consultas no Amazon Redshift diretamente no console do Amazon Redshift ou enviá-las usando os endpoints JDBC/ODBC fornecidos pelo Amazon Redshift.
O Amazon Redshift fornece um recurso, chamado Amazon Redshift Spectrum, para realizar consultas locais em sem a necessidade de carregá-lo no cluster. O Amazon Redshift Spectrum pode escalar milhares de nós temporários específicos da consulta para inspecionar exabytes de dados para fornecer resultados rápidos. As organizações normalmente carregam dados de dimensões e fatos acessados com maior frequência em um cluster do Amazon Redshift e mantêm-se até exabytes de dados históricos estruturados, semiestruturados e não estruturados no Amazon S3. O Amazon Redshift Spectrum permite executar consultas complexas que combinam dados em um cluster com dados no Amazon S3 na mesma consulta.
O Amazon Redshift fornece integração nativa com o Amazon S3 na camada de armazenamento, catálogo do Lake Formation e serviços AWS na camada de segurança e monitoramento.
Inteligência empresarial
O Amazon QuickSight fornece um recurso de BI serverless para criar e publicar facilmente painéis ricos e interativos. O QuickSight enriquece painéis e visuais com insights ML gerados automaticamente, como previsão, detecção de anomalias e destaques narrativos. O QuickSight integra-se nativamente ao Amazon SageMaker para permitir insights adicionais baseados em modelos ML personalizados em seus painéis de BI. Você pode acessar os dashboards do QuickSight a partir de qualquer dispositivo usando um aplicativo QuickSight, ou pode incorporar o painel em aplicativos, portais e sites da Web.
O QuickSight permite que você se conecte diretamente e importe dados de uma grande variedade de fontes de dados na nuvem e on-premises. Estes incluem aplicativos SaaS como Salesforce, Square, ServiceNow, Twitter, GitHub e JIRA; bancos de dados de terceiros como Teradata, MySQL, Postgres e SQL Server; serviços nativos da AWS como Amazon Redshift, Athena, Amazon S3, Amazon Relational Database Service (Amazon RDS) e Amazon Aurora; e sub-redes privadas de VPC. Você também pode carregar uma variedade de tipos de arquivos, incluindo XLS, CSV, JSON e Presto.
Para obter um desempenho rápido para painéis, o QuickSight fornece um mecanismo de cálculo de cache em memória chamado SPICE (Super-fast, Parallel, In-memory Calculation Engine – Engine de Cálculo Super rápido, Paralelo, Em memória)”. O SPICE replica automaticamente os dados para alta disponibilidade e permite que milhares de usuários realizem simultaneamente análises rápidas e interativas, protegendo sua infraestrutura de dados principal. O QuickSight escala automaticamente para dezenas de milhares de usuários e fornece um modelo de preços econômico e pay-per-session (pagar por sessão).
O QuickSight permite gerenciar seus usuários e conteúdo com segurança através de um conjunto abrangente de recursos de segurança, incluindo controle de acesso baseado em função, integração via Active Directory, auditoria AWS CloudTrail, Single-sign on (IAM ou terceiros), sub-redes privadas de VPC e backup de dados.
Análise preditiva e ML
O Amazon SageMaker é um serviço totalmente gerenciado que fornece componentes para construir, treinar e implantar modelos de ML usando um ambiente de desenvolvimento interativo (IDE – Interactive Development Environment) chamado Amazon SageMaker Studio. No Amazon SageMaker Studio, você pode carregar dados, criar novos notebooks, treinar e aprimorar modelos, mover-se para frente e para trás entre etapas para ajustar experimentos, comparar resultados e implantar modelos para produção, tudo em um só lugar usando uma interface visual unificada. Amazon SageMaker também fornece Jupyter notebooks gerenciadosde criar com apenas alguns cliques. Os notebooks Amazon SageMaker fornecem recursos de computação elástico, integração com Git, fácil compartilhamento, algoritmos de ML pré-configurados, dezenas de exemplos de ML fora da caixa e integração com o AWS Marketplace, que permite a fácil implantação de centenas de algoritmos pré-treinados. Os notebooks do Amazon SageMaker são pré-configurados com todas as principais estruturas de deep learning, incluindo TensorFlow, PyTorch, Apache MXNet, Chainer, Keras, Gluon, Horovod, Scikit-learn e Deep Graph Library.
Os modelos ML são treinados em instâncias de computação gerenciadas pelo Amazon SageMaker, incluindo instâncias Spot de alto custo-benefício do Amazon Elastic Compute Cloud (Amazon EC2). Você pode organizar vários trabalhos de treinamento usando o Amazon SageMaker Experiments. Você pode construir trabalhos de treinamento usando algoritmos incorporados do Amazon SageMaker, seus algoritmos personalizados ou centenas de algoritmos que você pode implantar a partir do AWS Marketplace. O Amazon SageMaker Debugger fornece total visibilidade em trabalhos de treinamento de modelos. O Amazon SageMaker também fornece ajuste automático de hiperparametros para trabalhos de treinamento de ML.
Você pode implantar modelos treinados pelo Amazon SageMaker em produção com alguns cliques e dimensioná-los facilmente em uma frota de instâncias EC2 totalmente gerenciadas. Você pode escolher entre vários tipos de instâncias EC2 e anexar a aceleração de inferência alimentada por GPU econômica. Depois que os modelos são implantados, o Amazon SageMaker pode monitorar as principais métricas do modelo para precisão de inferência e detectar qualquer deriva de conceito.
O Amazon SageMaker fornece integrações nativas com serviços AWS nas camadas de armazenamento e segurança.
Camada de segurança e governança
Componentes em todas as camadas de nossa arquitetura protegem dados, identidades e recursos de processamento usando nativamente os seguintes recursos fornecidos pela camada de segurança e governança.
Autenticação e autorização
O IAM fornece identidade a nível de usuário, grupo e função para os usuários e a capacidade de configurar controle de acesso granular para recursos gerenciados pelos serviços AWS em todas as camadas de nossa arquitetura. O IAM suporta autenticação de multifator e SSO por meio de integrações com diretórios corporativos e provedores de identidade abertos, como Google, Facebook e Amazon.
O Lake Formation fornece um modelo de autorização simples e centralizado para tabelas hospedadas no data lake. Após implementadas no Lake Formation, as políticas de autorização para bancos de dados e tabelas são aplicadas por outros serviços da AWS, como Athena, Amazon EMR, QuickSight e Amazon Redshift Spectrum. No Lake Formation, você pode conceder ou revogar o acesso em nível de banco de dados, tabela ou coluna para usuários, grupos ou funções do IAM definidos na mesma conta hospedando o catálogo do Lake Formation ou outra conta AWS. O modelo de autorização simples baseado em concessão/revogação do Lake Formation simplifica consideravelmente o modelo de autorização anterior baseado no IAM que dependia de proteger separadamente objetos de dados do S3 e objetos metadados no Catálogo de Dados do AWS Glue.
Encriptação
O AWS KMS fornece o recurso para criar e gerenciar chaves de criptografia simétricas e assimétricas gerenciadas pelo cliente. Os serviços da AWS em todas as camadas de nossa arquitetura integram-se nativamente com o AWS KMS para criptografar dados no data lake. Ele suporta tanto a criação de novas chaves quanto a importação de chaves de cliente existentes. O acesso às chaves de criptografia é controlado usando o IAM e é monitorado através de trilhas de auditoria detalhadas no CloudTrail.
Proteção de rede
Nossa arquitetura usa o Amazon Virtual Private Cloud (Amazon VPC) para prover uma seção logicamente isolada da Nuvem AWS (chamada VPC) que está isolada da internet e de outros clientes da AWS. O AWS VPC oferece a capacidade de escolher sua própria gama de endereços IP, criar sub-redes e configurar tabelas de roteamento e gateways de rede. Serviços AWS de outras camadas em nossa arquitetura lançam recursos neste VPC privado para proteger todo o tráfego de e para esses recursos.
Monitoramento e logs
Serviços AWS em todas as camadas de nossa arquitetura armazenam logs detalhados e métricas de monitoramento no AWS CloudWatch. O CloudWatch fornece a capacidade de analisar logs, visualizar métricas monitoradas, definir limites de monitoramento e enviar alertas quando os limites são ultrapassados.
Todos os serviços da AWS em nossa arquitetura também armazenam extensas trilhas de auditoria das ações de usuários e serviços no CloudTrail. O CloudTrail fornece histórico de eventos das atividades na sua conta AWS, incluindo ações tomadas através do AWS, ferramentas de linha de comando e outros serviços AWS. Esse histórico de eventos simplifica a análise de segurança, o rastreamento de alterações de recursos e a solução de problemas. Além disso, você pode usar o CloudTrail para detectar atividades incomuns em suas contas AWS. Esses recursos ajudam a simplificar a análise operacional e a solução de problemas.
Considerações adicionais
Neste post, falamos sobre ingerir dados de diversas fontes e armazená-los como objetos do S3 no data lake e, em seguida, usar o AWS Glue para processar conjuntos de dados ingeridos até que eles estejam em um estado de consumo. Essa arquitetura permite casos de uso que precisam de latência da origem ao consumo de alguns minutos a horas. Em um post futuro, evoluiremos nossa arquitetura de análise serverless para adicionar uma camada de velocidade para permitir casos de uso que requerem latência da origem ao consumo em segundos, tudo isso enquanto estamos alinhados com a arquitetura lógica em camadas que introduzimos.
Conclusão
Com serviços gerenciados e serverless da AWS, você pode construir uma arquitetura de análise moderna e centrada no data lake de baixo custo em dias. Uma arquitetura dissociada e baseada em componentes permite que você inicie pequeno e rapidamente adicione novos componentes construídos com propósito a uma das seis camadas de arquitetura para atender a novos requisitos e fontes de dados.
Convidamos você a ler as seguintes postagens que contêm passo a passos detalhados e código de amostra para a construção dos componentes da arquitetura de análise serverless centrada no data lake:
- Carregue mudanças contínuas do data lake com AWS DMS e AWS Glue
- Descubra metadados com AWS Lake Formation: Parte 1 e Parte 2
- Processar dados com frequências de ingestão de dados variadas usando marcadores no Jobs do AWS Glue
- Orquestre fluxos de trabalho ETL baseados em redshift da Amazon com funções de passo AWS e AWS Glue
- Analise seus gastos do Amazon S3 usando AWS Glue e Amazon Redshift
- Extrair, transformar e carregar dados em data lake no S3 usando expressões CTAS e INSERT INTO no Amazon Athena
- Obtenha insights de IoT em minutos usando AWS IoT, Amazon Kinesis Firehose, Amazon Athena e Amazon QuickSight
- Prevendo o risco de reinternação de todos os pacientes usando o data lake AWS e aprendizado de máquina
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre os autores
 Praful Kava é Sr. Specialist Solutions Architect na AWS.
Praful Kava é Sr. Specialist Solutions Architect na AWS.
 Changbin Gong é Senior Solutions Architect na Amazon Web Services (AWS).
Changbin Gong é Senior Solutions Architect na Amazon Web Services (AWS).