AWS Database Blog
Category: Intermediate (200)

Migrating to Amazon ElastiCache for Valkey: Best practices and a customer success story
In this post, we provide a guide to migrating from Redis OSS to ElastiCache for Valkey, incorporating different migration strategies and AWS best practices. Additionally, we highlight a customer’s successful migration to Valkey, which maintained their robust performance standards while achieving a 20% reduction in ElastiCache cluster costs.

Augment DMS SC with Amazon Q Developer for code conversion and test case generation
You can use the AWS Database Migration Service Schema Conversion (AWS DMS SC) with generative AI feature to accelerate your database migration to AWS. This feature automatically handles the conversion of many database objects during migration by using traditional rule-based techniques and deterministic AI techniques. In this post, we demonstrate how Amazon Q Developer delivers generic solutions for complex AWS DMS SC issues, intelligently converts database stored procedure code from source to target database-compatible code, and automatically generates comprehensive test cases to validate your migrated database objects.

From bottlenecks to breakthroughs: Dutchie’s database migration journey
Dutchie, a leading technology platform serving the cannabis industry, manages critical operations for thousands of dispensaries across multiple states, processing millions of transactions annually. In this post, we explore how Dutchie successfully navigated the challenges of migrating mission-critical workloads to Amazon RDS for SQL Server in preparation for 4/20 week in 2025.

Upgrade legacy Amazon RDS file systems to increase storage capacity and improve performance with minimal downtime
Amazon RDS instances running on legacy file systems face several limitations. Storage is capped at 16 TiB, and some engines, including MySQL, MariaDB, and PostgreSQL, may encounter per-file size limits of approximately 2 TiB due to file system constraints, even though the database engines themselves support larger objects. In this post, I show you how to upgrade an RDS instance to the current file system with minimal downtime using Amazon RDS blue/green deployments.

Use default encryption at rest for new Amazon Aurora clusters
In this post, you learn how Amazon Aurora now provides encryption at rest by default for all new database clusters using AWS owned keys. You’ll see how to verify encryption status using the new StorageEncryptionType field, understand the impact on new and existing clusters, and explore migration options for unencrypted databases.

Accelerate your database migration journey with AI
When running database migration with AWS DMS, you may encounter opportunities to streamline your workflow: interpreting error messages, understanding configuration parameter relationships, and navigating between the console, documentation, and community forums during troubleshooting. What if you could have an AI-powered assistant that understands your migration context, diagnoses issues in real-time, and provides actionable guidance—all within your workflow? In this post, we show you have Amazon Q integration with AWS DMS can transform your database migration experience.

New in Terraform: Manage global secondary index drift in Amazon DynamoDB
The new aws_dynamodb_global_secondary_index resource treats each GSI as an independent resource with its own lifecycle management. You can use this feature to make capacity adjustments for GSI and tables outside of Terraform. In this post, I demonstrate how to use Terraform’s new aws_dynamodb_global_secondary_index resource to manage GSI drift selectively. I walk you through the limitations of current approaches and guide you through implementing the solution.
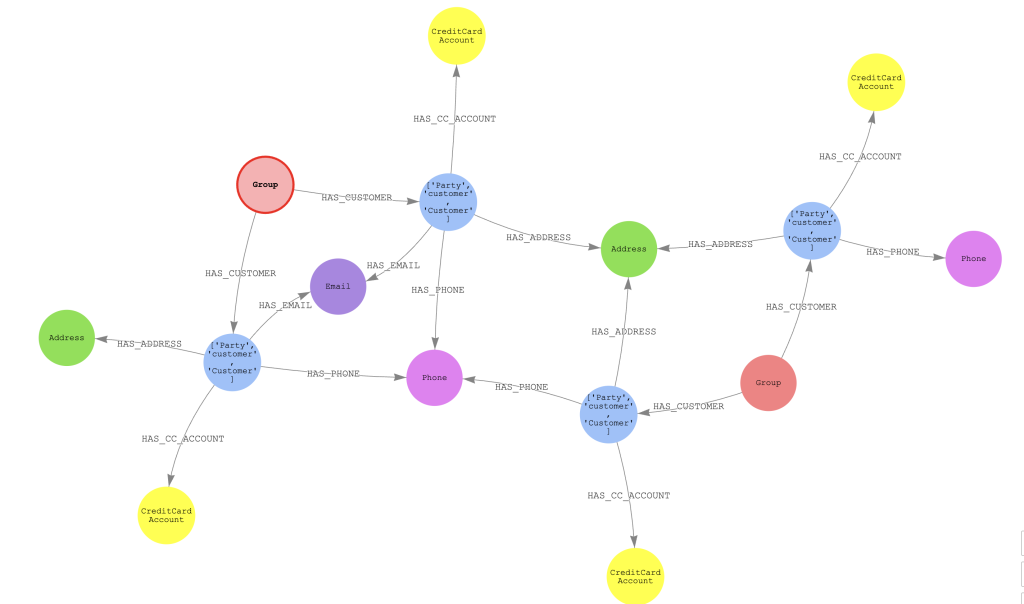
Build fraud detection systems using AWS Entity Resolution and Amazon Neptune Analytics
In this post, we show how you can use graph algorithms to analyze the results of AWS Entity Resolution and related transactions for the CNP use case. We use several AWS services, including Neptune Analytics, AWS Entity Resolution, Amazon SageMaker notebooks, and Amazon S3.
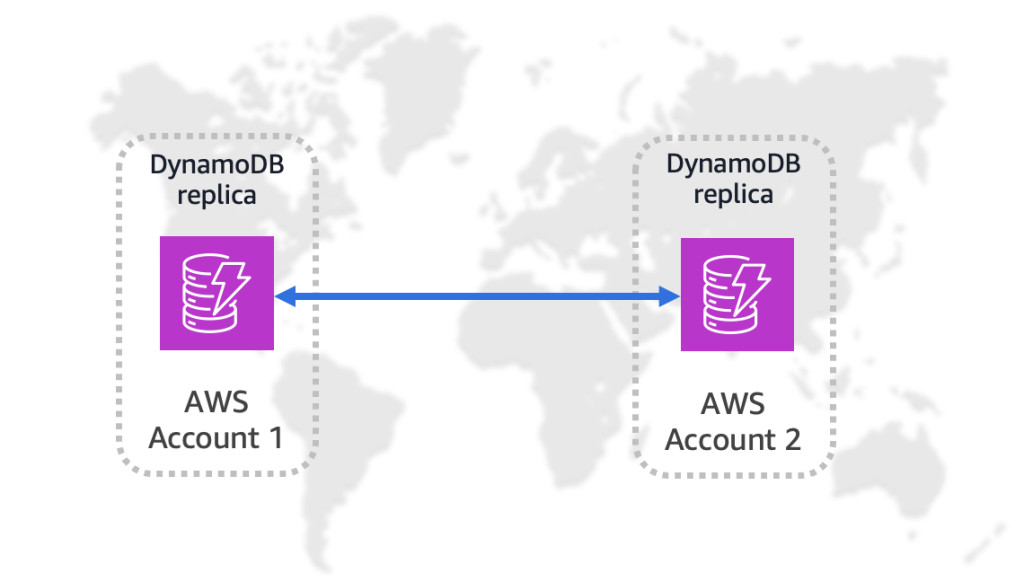
Amazon DynamoDB global tables now support replication across AWS accounts
Today, we’re announcing multi-account global tables for Amazon DynamoDB, which let you replicate DynamoDB table data across multiple AWS accounts and AWS Regions. This feature adds account-level isolation to global tables, so you can replicate DynamoDB table data across multiple AWS accounts and Regions for stronger isolation and resiliency. In this post, we show you how to create and configure a multi-account global table, and introduce use cases highlighting the value of using this feature.

Optimize LLM response costs and latency with effective caching
In this post, we talk about the benefits of caching in generative AI applications. We also elaborated on a few implementation strategies that can help you create and maintain an effective cache for your application.