Artificial Intelligence
Leveraging Low Precision and Quantization for Deep Learning Using the Amazon EC2 C5 Instance and BigDL
Recently AWS released the new compute-intensive Amazon EC2 C5 instances, based on the latest generation Intel Xeon Scalable Platinum processors. These instances are designed for compute-heavy applications, and offer a large performance improvement over the C4 instances. They also have additional memory per vCPU, and twice the performance for vector and floating-point workloads.
In this blog, we will demonstrate how BigDL, an open source distributed deep learning framework for Apache Spark, can take advantage of the new capabilities offered in the AWS C5 instances that can significantly improve large scale deep learning workloads. In particular, we will show how BigDL can leverage low precision and quantization using C5 instances to achieve up-to a 4x reduction in model size and nearly a 2x improvement in inference speeds.
Why deep learning on C5 instances?
The new AWS C5 instances take advantage of Intel Xeon Scalable processor features such as larger core counts at higher processor frequencies, fast system memory, a large per-core mid-level cache (MLC or L2 cache), and new wide SIMD instructions (AVX-512). These features are designed to boost math operations involved in deep learning, which make the new C5 instances an excellent platform for large-scale deep learning.
BigDL is a distributed deep learning framework for Apache Spark that was developed and open sourced by Intel, and it allows users to build and run deep learning applications on existing Hadoop/Spark clusters. Since its initial open source in December 2016, BigDL has received wide adoption in the industry and developer community (e.g., Amazon, Microsoft, Cray, Alibaba, JD, MLSlistings, and Gigaspaces, etc.).
BigDL is optimized to run within large-scale big data platforms, which are typically built on top of distributed Xeon-based Hadoop/Spark clusters. It leverages Intel Math Kernel Library (MKL) and multi-thread computing for high performance, and uses the underlying Spark framework for efficient scale-out. Consequently, it can efficiently take advantage of the capabilities available in the new C5 instances from AWS, and we have observed significant speedups compared to previous generations of instance families.
Leveraging low precision and quantization
In addition to the raw performance improvements gained from using C5 instances, the BigDL 0.3.0 release also introduced model quantization support, which allows for inference using lower precision computations. Running on C5 instances from AWS, we’ve seen up-to a 4x reduction in model size and nearly a 2x improvement in inference speeds.
What is model quantization?
Quantization is a general term that refers to using technologies that store numbers and perform calculations on them in more compact and lower precision form than their original format (e.g., 32-bit floating point). BigDL takes advantage of this type of low precision computing to quantize pre-trained models for inference: it can take existing models trained in various frameworks (e.g., BigDL, Caffe, Torch, or TensorFlow), quantize the model parameters and input data using a much more compact 8-bit integer format, and then apply the AVX-512 vector instructions for fast 8-bit calculations.
How does quantization work in BigDL?
BigDL allows users to directly load existing models trained using BigDL, Caffe, Torch, or TensorFlow. After the model is loaded, BigDL can first quantize the parameters of some selected layers into 8-bit integer (using the following equation) to produce a quantized model:
During model inference, each quantized layer dynamically quantizes the input data into 8-bit integer, applies the 8-bit calculations (such as GEMM) using the quantized parameters and data, and dequantizes the results to 32-bit floating point. Many of these operations can be fused in the implementation, and consequently the quantization and dequantization overheads are very low at inference time.
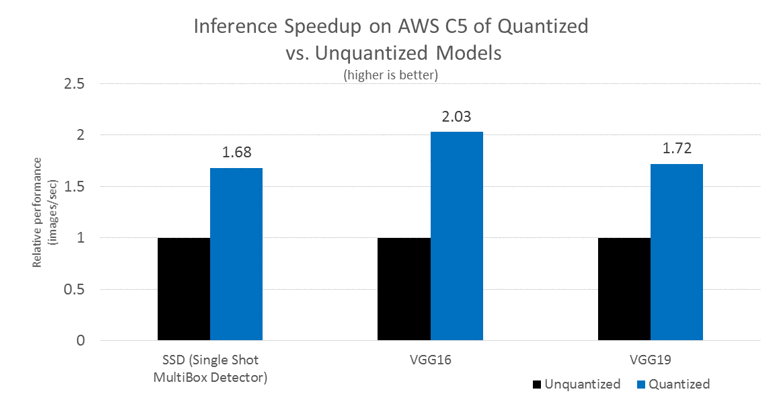
Unlike many existing implementations, BigDL uses a new local quantization scheme for model quantization. That is, it performs the quantization and dequantization operations (as described earlier) in each small local quantization window, a small sub-block (such as a patch or kernel) of the parameters or input data. As a result, BigDL can use very low bit integers, such as 8-bit, in model quantization with extremely low model accuracy drop (less than 0.1%), and can achieve some impressive efficiencies, as shown in the following charts with details of the actual benchmark configuration listed at the end of the blog.
Inference Speedup on C5: Relative Performance (Quantized vs. Unquantized Models) – 1.69~2.04x inference speedup using quantization in BigDL
Inference Accuracy on C5: (Quantized vs. Unquantized Models) – less than 0.1% accuracy drop using quantization in BigDL

Model Size (Quantized vs. Unquantized Models) – ~3.9x model size reduction using quantization in BigDL

How to use quantization in BigDL?
To quantize a model in BigDL, you first load an existing model as follows (refer to the BigDL document for more details on Caffe support and TensorFlow support):
After that, you can simply quantize the model and use it for inference as follows:
In addition, BigDL also provides command line tools (ConvertModel) for converting the pre-trained model to a quantized model. Refer to the BigDL document for more details on model quantization support.
Try it out for yourself!
- Try BigDL on AWS today through the AWS Marketplace.
- You can learn more about BigDL and model quantization in here.
- To run BigDL on Amazon EMR you can follow the instructions in our previous blog post, Running BigDL, Deep Learning for Apache Spark, on AWS.
Benchmark Configuration details:
| Benchmark type | Inference |
| Benchmark metric | Images/Sec |
| Framework | BigDL |
| Topology | SSD, VGG16, VGG19 |
| # of Nodes | 1 |
| Amazon EC2 instances | C5.18xlarge |
| Sockets | 2S |
| Processor | “Skylake” generation |
| Enabled cores | 36c (c5.18xlarge) |
| Total memory | 144 GB (c5.18xlarge) |
| Storage | EBS-optimized GP2 |
| OS | RHEL 7.4 3.10.0-693.el7.x86_64 |
| HT | ON |
| Turbo | ON |
| Computer type | Server |
| Framework version | https://github.com/intel-analytics/BigDL |
| Dataset, version | COCO, Pascal VOC, Imagenet-2012 |
| Performance command | Inference throughput measured in images/sec |
| Data setup | Data was stored on local storage and cached in memory before training |
| Oracle Java | 1.8.0_111 |
| Apache Hadoop | 2.7.3 |
| Apache Spark | 2.1.1 |
| BigDL | 0.3.0 |
| Apache Maven | 3.3.9 |
| Protobuf | 2.5 |
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Intel, the Intel logo, Xeon, are trademarks of Intel Corporation in the U.S. and/or other countries.
About the Authors
 Jason Dai is a Senior Principal Engineer and CTO of Big Data Technologies at Intel, leading the global engineering teams on the development of advanced big data analytics (including distributed machine learning and deep learning). He is a founding committer and PMC member of Apache Spark, the program co-chair of O’Reilly AI Conference in Beijing, and the chief architect of BigDL (https://github.com/intel-analytics/BigDL/), a distributed deep learning framework on Apache Spark.
Jason Dai is a Senior Principal Engineer and CTO of Big Data Technologies at Intel, leading the global engineering teams on the development of advanced big data analytics (including distributed machine learning and deep learning). He is a founding committer and PMC member of Apache Spark, the program co-chair of O’Reilly AI Conference in Beijing, and the chief architect of BigDL (https://github.com/intel-analytics/BigDL/), a distributed deep learning framework on Apache Spark.
 Joseph Spisak leads AWS’ partner ecosystem focused on Artificial Intelligence and Machine Learning. He has more than 17 years in deep tech working for companies such as Amazon, Intel and Motorola focused mainly on Video, Machine Learning and AI. In his spare time, he plays ice hockey and reads sci-fi.
Joseph Spisak leads AWS’ partner ecosystem focused on Artificial Intelligence and Machine Learning. He has more than 17 years in deep tech working for companies such as Amazon, Intel and Motorola focused mainly on Video, Machine Learning and AI. In his spare time, he plays ice hockey and reads sci-fi.