AWS Storage Blog
Optimize costs and speed up replication with AWS Elastic Disaster Recovery
Maintaining application and data resilience can often be challenging. There is an ever-evolving risk landscape that includes ransomware attacks, natural disasters, user error, hardware faults, and more. Organizations understandably have a strong desire to ensure they can recover within appropriate timescales from an unforeseen disaster event that impacts their systems. In such cases, organizations seek dependable solutions to enable them to achieve their resilience goals within financial and time-related constraints.
AWS Elastic Disaster Recovery (AWS DRS) provides scalable, cost-effective recovery of applications to AWS. One of the benefits is that you only pay for what you use. However, customers need to ensure that workloads are configured to run in a cost-efficient manner, with cost optimizations made in line with the AWS Well-Architected Framework.
There are several configuration strategies possible with AWS DRS. In this post, I explore the strategic and technological considerations for reaching a cost-optimal disaster recovery (DR) solution within AWS. Understanding what makes up the associated costs of using AWS DRS is a key step in targeting efforts to reduce cost without sacrificing resilience. This includes things like using the most relevant resilience strategy and retention periods, driving redundancy, selecting the region, and right-sizing infrastructure.
Overview of Disaster Recovery Strategies on AWS
When considering DR solutions, it’s important to consider the target Recovery Point Objective (RPO) and Recovery Time Objective (RTO) for the workloads you want to protect. Not all workloads are created equal. There may be opportunities to lower the cost where there is a tolerance for time-gaps in availability and data loss.
In general, the terms RPO and RTO are central to backup and DR. They can be defined as follows:
- RPO: The amount of time that can be tolerated between the act of recovery and the last available data backup. (for example, “I can tolerate losing 5 minutes of data in this application.”)
- RTO: The time that can be tolerated for infrastructure and services to start serving traffic in a pre-disaster form. (for example, “I can afford to wait 15 minutes for the database server to failover and start performing transactions.”)
With AWS DRS, it’s possible to achieve an RPO of seconds and an RTO of minutes. You can learn about the factors that can impact these objectives by viewing our documentation.
Nature and Cost Impact of Disaster Recovery Strategies

To dive deep on the strategies for disaster recovery in the cloud, see this whitepaper.
For AWS and VMWare-based (VMWare Cloud on AWS and VMWare on-premises) workloads with a less strict RPO/RTO objective, AWS Backup can be a great choice if drill and failover functionality is also not required. You can learn how to get started with AWS Backup here.
General approach for optimizing for cost and time-efficient DR
The cost structure of using AWS DRS is summarized in the following table, as per East US (N. Virginia) Region with pricing as of 18th July 2022 with on-demand modelling:
|
Cost type |
Applies before or after Failover |
Cost drivers |
| AWS DRS service cost | Before (always ongoing) | $0.028 per hour for each source server (includes continuous data replication, test launches, recovery launches, and point-in-time recovery processes). |
| Staging disks | Before (always ongoing) | Appropriate Amazon Elastic Block Store (EBS) type selected according to whether the Amazon EBS volume is more or less than 500 GB in size. |
| Snapshot data | Before (always ongoing) | AWS DRS has the following point-in-time (PIT) state schedule:
You can increase or decrease the default 7-day snapshot retention rate from anywhere between 1 day and 365 days in the Replication Settings. |
| Replication server(s) | Before (always ongoing) | One t3.small Amazon Elastic Compute Cloud (EC2) instance ($0.0236 per hour) for every 15 source volumes. This drives the replication of source servers into AWS and talks to the replication agents at source. |
| Conversion server(s) | After (short-term) | Generally, less than $0.05 per launched recovery instance (due to a Conversion Server which packages the replicated data such that it can run inside of Amazon EC2 infrastructure). |
| Target failover EC2 instance(s) and mounted EBS volume | After (life of DR event) |
Each source server fails over to an Amazon EC2 instance as defined in the launch template on 1:1 basis. $0.1699 per hour per instance (for an exemplar t3a.xlarge Amazon EC2 type that has 4 vCPU, 16GB RAM and up to 5 Gigabit network). |
Based on the previous information, the method to reduce operational costs when using AWS DRS is to perform a combination of the following:
- Consider servers on a case-by-case basis. Do they require an ongoing replication-based DR approach to meet their RPO/RTO objectives?
- Evaluate the retention period required for point-in-time snapshots. How far into the past do you need to retain the ability to restore?
- For those servers being covered by AWS DRS, consider whether there are redundant drives mounted that are no longer in use and do not need to be replicated. These can either be unmounted or excluded when setting up the replication agent.
- Right-size the target failover infrastructure by selecting the appropriate Amazon EC2 instance type in the launch template. You use the instance right-sizing feature to map to an instance type that closely follows the source infrastructure. Alternatively, you can use operational data in the source environment to further trim resources. For example, consider trimming a server that you know is overprovisioned and never exceeds 25% CPU utilization.
The size of the underlying disks (i.e., the entire disk and not just partitions) directly dictates the amount of data that is replicated over into AWS during the initial sync process. As a result, right sizing and being selective of workloads, as per RPO/RTO objectives, gives the benefit of both monetary and time savings.
Unoptimized environments versus optimized environments
Let’s consider a fleet of virtual machines on-premises that have a total provisioned capacity of 75 TB, but only 30 TB is in use. There are 20 source servers, 50 disks, an average change rate of 3% per day, 20% of disks are larger than 500 GB, and the snapshot retention period is 7 days.
The customer judges that the current storage space in use today, plus some headroom of 20%, means that systems continue to operate for the future without issue. This means that 36 TB in total is replicated into AWS after shrinking the underlying disks.
The customer has a 5 Gbps line available to use, but they can only use up to 1 Gbps due to needing to reserve capacity for other operations.
The following table covers the approximate costs and time to perform initial sync with AWS DRS. It excludes post-failover Amazon EC2 costs, which are on-demand but can vary by workload. The Region estimate provided is for US East (N. Virginia) and uses data correct as of 18th July 2022.
Please note that all figures below are for modelling only, and real-world conditions in some environments may dictate a different result. The purpose is to illustrate the power of right-sizing ahead of commencing replication for heavily overprovisioned source environments.
| Total drive size | Initial sync time (w/ 1 Gbps) | Cost per month | |||
| without Optimization | with Optimization | without Optimization | with Optimization | without Optimization | with Optimization |
| 75 TB | 36 TB | 6.944 days | 3.333 days | $9,356.00 | $4,703.45 |
Mapping Amazon EBS to workload constraints
When setting your default replication settings within AWS DRS, you have the option to select the Amazon EBS volume type applied to source disks over 500 GB. By default, disks smaller than this use the Magnetic HDD option. Costs optimized here should fit your workloads with regard to the constraints of slower and lower cost disks. The exception to this is if auto volume type is selected (i.e., the automatic selection of disk types occurs for any disks above 125 GB). Options include:
- Auto volume type selection: Dynamically switch between performance and cost-optimized volume type according to the replicated disk write throughput.
- Faster, general purpose SSD (gp3): A newer generation version of gp2 with 20% lower costs than the predecessor, with decoupled storage performance and capacity.
- Faster, general purpose SSD (gp2): Disks that better support source servers with high write rates or have a requirement for higher general performance. The initial sync process occurs faster than with st1 drives.
- Lower cost, throughput optimized HDD (st1): Slower and less expensive disks are used to minimize cost when disks do not change frequently, but have the possibility of slower initial sync process completion.

Regional placement and costs
Choosing the Region to operate AWS DRS factors into the operating cost. If your regulatory and compliance requirements allow, you may opt to use an AWS Region outside of your country of operation to reduce costs.
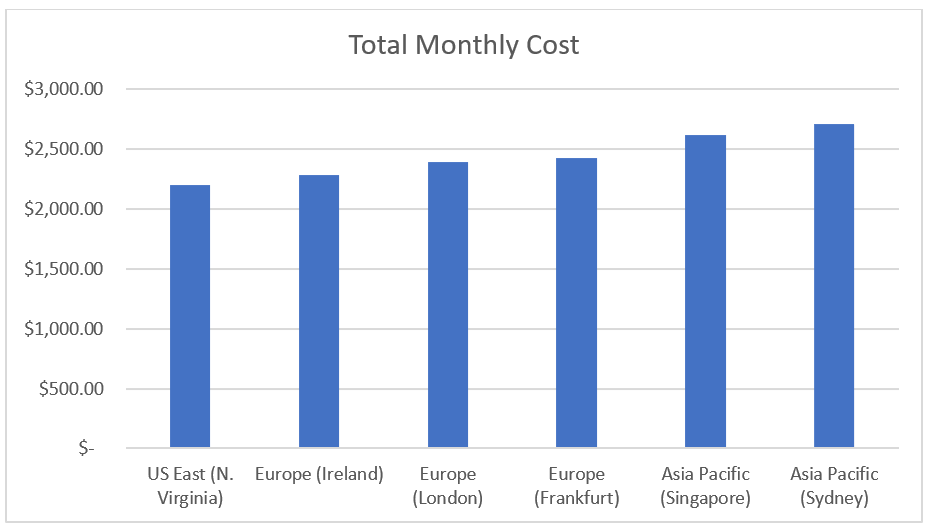
We consider the following scenario for AWS Region selection:
- Number of source servers replicated per month: 20 servers
- Number of disks: 50 disks
- Average change rate on disks per day: 3%
- Storage on all disks and all servers: 15 TB
- Percentage of source disks larger than 500 GB: 20%
- Number of days selected for Amazon EBS snapshot retention period: 7 days
Based on the AWS Pricing Calculator estimate of AWS DRS replication (not including the Amazon EC2 post-failover resources), the following graph illustrates the pricing difference in several Regions for our solution. The data presented in this graph was taken on 18th July 2022. Please note that AWS DRS is available in several more Regions.
Replication connectivity options and the impact on time and cost
You have three main options for replicating into AWS from on-premises and one exclusive to AWS-based sources. These options vary in cost and potential time to complete initial replication:
- Public Internet: Data is encrypted in transit and uses existing networking infrastructure at source to route replication traffic into AWS. Bandwidth ceiling is dictated by the bandwidth available on the connection at source. This is the lowest-cost option as no changes are needed to infrastructure, but there may be a need to throttle replication activity to avoid overstretching capacity and potentially interfering with other services using the connection.
- Site-to-Site VPN: will often use the same source connection as using the public internet directly, but traffic will route via a customer-managed VPC first and will have an additional layer of encryption. By no means does this indicate that the public internet approach is insecure. Each VPN connection is capped at 1.25 Gbps (or less if the bandwidth available on the source connection is lower). There are some costs associated with VPNs.
- AWS Direct Connect: In most cases, this provide the fastest possible initial replication and strongest ongoing replication reliability. However, there is an initial investment involved in establishing a Direct Connect connection.
-
- This can be a great choice if you have sufficient time available to have this deployed. It has the power to significantly expedite DR setup and it can be used for ongoing hybrid cloud operations well beyond disaster recovery use cases alone. Speeds in various increments between 50 Mbps to 100 Gbps are available.
- Transit Gateway and VPC Peering: If replicating into AWS DRS from an AWS source, there is the option of VPC peering with or without the use of a Transit Gateway between the source VPC and the VPC used by AWS DRS to avoid routing traffic via the internet. In general, Transit Gateway vastly simplifies the management of networks with multiple spokes, such as VPN connections, multiple VPCs, and Direct Connect, etc. You can learn how to set one up here.
Target failover instance sizing with AWS DRS
When considering the costs incurred post-failover or during drills, you can right-size the compute on a per-host basis. Each host is spun up in AWS following a launch template defined on per-host granularity.
There is the option to follow the basic capacity matching behaviour of instance type right-sizing built in to AWS DRS. To more closely map to the true needs of the source workloads, AWS Migration Evaluator can provide the insight to launch your templates. Alternatively, you may also have data available from current monitoring tools and activities to guide this decision.
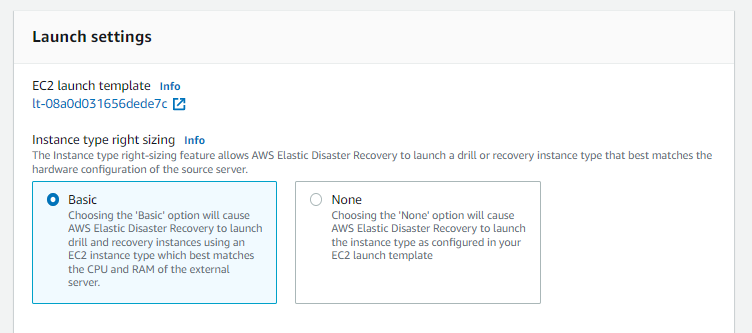
You may have a source server that is overprovisioned and can safely be reduced down to a smaller size (e.g., 4 vCPU, 16 GB RAM instead of 4x this amount) and still operate without issue. In that case, the launch setting shown in the following diagram may be a beneficial step to save operational costs.
Using the AWS pricing calculator
When using the AWS Pricing Calculator to estimate the cost of AWS DRS to protect your workloads, you must create two types of estimates:
- AWS DRS: This covers the ongoing service cost, staging Amazon EBS volumes, point-in-time snapshots, and replication servers.
- Amazon EC2: This covers the post-failover (and/or post-drill) costs of operating Amazon EC2 instances to take on the work of the source servers, and their underlying mounted Amazon EBS volumes.
After creating these two estimate types, refer to the resulting My Estimate screen to see the running total.
Resources to aid right-sizing and optimization in your environment
Because AWS DRS runs at the operating system level, it’s compatible across a vast set of environments, ranging from virtualized to physical. (See the full list of supported operating systems.)
Links for some common on-premises virtualisation environments are listed below:
- VMWare ESXi
- Microsoft HyperV
Please consult your vendor documentation and resources for additional guidance on how to shrink underlying disks and measure system resource utilization.
Options for shrinking physical source hosts may be more limited due to drives being set at fixed capacities, but this does not prevent physical hosts from being used with the services that are still fully supported. One approach is to migrate the host into a virtualized environment with a smaller virtual hard disk backing it.
Conclusion
In this post, I explored practical methods of reducing costs and replication times for AWS DRS. I covered the cost structure of AWS DRS, the power of optimizing the source environment, the distinction between EBS volume types, how costs can vary between regions, the significance of the replication connection medium, and right-sizing the failover state.
AWS DRS is a sound choice when implementing a Pilot Light disaster recovery strategy. It can provide an RTO of minutes and an RPO of seconds, allowing you to failover your services into AWS with a great impact reduction to cost ratio. You can benefit from the OS-level replication agent and cover a wide range of source servers so that they can recover from a disaster event.
Learn how to get started with the service and understand this extensive service user guide to aid you in your journey to protect your resources and quickly react to disasters impacting your infrastructure. Please ask your questions or provide comments using the button below.