Amazon Web Services ブログ
Amazon S3 Glacier ストレージクラスへのログの圧縮とアーカイブ
このブログは 2022 年 3 月 7 日に Ilir Iljazi (senior cloud solutions architect) によって執筆された内容を日本語化した物です。原文はこちらを参照して下さい。
分散アーキテクチャでは、アプリケーションログを保存する必要がある場合が多く、AWS のお客様では、Amazon S3 バケットを介して保存されることがよくあります。ログには、ランタイムトランザクション、error / failure のステータス、またはアプリケーションのメトリクスや統計に関する情報が含まれている場合があります。これらのログは、後にビジネスインテリジェンスで使用され、有用な洞察を提供し、ダッシュボード、分析、およびレポートを生成するために使用されます。アプリケーションによっては、ログファイルは信頼できる唯一の情報源として機能し、ガバナンスや監査目的には不可欠です。そのため、高い可用性と耐久性を保証して、ログを永続的に保存する必要があります。多くのお客様は、ログを様々な形式で Amazon S3 に直接書き込むことを選択しますが、Amazon Kinesis などの AWS サービスを介してログをストリームすることを好むお客様もいます。
このブログ記事では、Amazon S3 Glacier ストレージクラスに何百万ものログファイルをアーカイブする際の、コストに関する考慮事項を説明します。Amazon S3 Glacier ストレージクラス(Amazon S3 Glacier Instant Retrieval、Amazon S3 Glacier Flexible Retrieval、Amazon S3 Glacier Deep Archive)は、データアーカイブと長期バックアップ用の、セキュアで耐久性があり、非常に低コストの Amazon S3 クラウドストレージクラスです。Amazon S3 Glacier ストレージクラスにオブジェクトを移行するために、Amazon S3 は Amazon S3 Intelligent-Tiering ストレージクラスを提供します。これは、パフォーマンスへの影響や運用上のオーバーヘッドなしに、データアクセスのパターンが変化したときにストレージコストを自動的に節約する唯一のクラウドストレージクラスです。さらに、Amazon S3 はバケット/オブジェクトのライフサイクルポリシーを提供し、自動的に移行アクションや失効アクションを実行することができます。効果的なアーカイブ戦略は、データの高可用性と耐久性の保証を維持しながら、ストレージコストを削減することに貢献します。
この記事で紹介するデータアーカイブのユースケースは、AWS のお客様である Primex Inc. から直接お聞きしたものです。Primex はワクチンとヘルスケアアセットを監視する洗練されたプラットフォームで、オブジェクトアーカイブに関する AWS のリソースをフルに活用してソリューションを開発し、最終的に Amazon S3 Glacier ストレージクラスへのオブジェクト移行コストを2桁以上削減することに成功しました。
Primex Inc. のアーカイブユースケース
IoT デバイスフリートで動作するアプリケーションは、3 年間で 4 億 5 千万ものログファイルを生成しました。このログファイルは、Amazon S3 Standard ストレージクラスで 40 TB 強のストレージに相当し、平均オブジェクトサイズは約 88 KB でした。この稀にしかアクセスされないデータの保管コストを削減するため、Primex Inc. は Amazon S3 Glacier Flexible Retrieval(旧 Amazon S3 Glacier)にデータをアーカイブすることを検討しました。ライフサイクルの移行コストは、移行するオブジェクト数に比例します。Premix Inc. では、Amazon S3 Glacier Flexible Retrieval に移行する小さな容量のファイルが大量にあり(4 億 5000 万)、効果的なライフサイクルポリシーでアーカイブするためのコストが割高になっていました。したがって、このソリューションの主な目的は、データをアーカイブするために必要なライフサイクル移行の総数を最小限に抑えることでした。これは、ログの集約と圧縮を活用することで達成されました。
Amazon S3 Glacier ストレージコストに対するログサイズの影響
Amazon S3 Glacier ストレージクラスに移行したオブジェクトは、インデックス情報および関連するオブジェクトのメタデータを含む 32 KB のデータが追加で保存されます。さらに、Amazon S3 はオブジェクトの名前と他のメタデータに 8 KB のストレージを使用し、Amazon S3 Standard ストレージの料金レートで課金されます。これらのメタデータオブジェクトを組み合わせることで、どのストレージクラスにあるかに関わらず、Amazon S3 からオブジェクトを識別、一覧表示、取得することができます。どのようなサイズのオブジェクトでも Amazon S3 Glacier ストレージクラスにアーカイブすることができますが、このストレージ管理のオーバーヘッドにより、128 KB より小さいオブジェクトをアーカイブすることは非効率です。ただし、より小さなオブジェクトをアーカイブする前に集約することが望ましく、推奨します。これにより、ライフサイクルの移行コストと Amazon S3 Glacier ストレージのオーバーヘッドコストを最小限に抑えることができます。Amazon S3 コンソールのライフサイクルポリシー設定画面では、この問題について具体的に警告し、回避する方法についての提案を提供しています。

図 1: ライフサイクル ポリシーのコストに関する注意メッセージ
さらに、bzip2 や gzip などの効果的なファイル圧縮プロトコルを使用すると、ストレージの必要量を最大で 1 桁減らすことができます。ストレージ関連のコスト観点で言えば、同じコストで 10 倍のデータを格納することを意味します。ただし、圧縮してもライフサイクル移行によって Amazon S3 Glacier ストレージクラスにアーカイブする必要があるログの数は減りません。したがって、オブジェクトの圧縮はライフサイクルの移行コストに影響を与えません。
Amazon S3 Glacier ストレージクラスは、クラウドで最も低コストのアーカイブストレージを提供します。Amazon S3 Glacier ストレージクラスと関連するコストの詳細については、Amazon S3ストレージクラスの FAQ を参照してください。
ライフサイクル移行コストに対するログ数の影響
ストレージコストを削減しながらログファイルを永続的に保存するビジネスニーズがある場合、Amazon S3 Glacier ストレージクラスへのアーカイブは優れた選択肢となります。ライフサイクルの移行に伴うコストを削減するためには、生成されるログの数を最小限に抑えることが重要です。生成されるログの数は、フリート内のデバイスの数と、これらのデバイスがログを生成する頻度(ログローテーションポリシー)に依存します。一般的に時間間隔でログをローテーションするアプリケーションもあれば、サイズによってログをローテーションするアプリケーションもあります。アプリケーションのロギング動作とログを生成するデバイスの数を理解することで、一定期間内に生成されるログの総数を推定することができます。生成されたログファイルの数を把握することで、AWS Pricing Calculator を利用してライフサイクルの移行に関連するアーカイブコストを見積もることができます。
ライフサイクル遷移に伴うコストを最適化するためには、Amazon S3 Glacier ストレージクラスに移行するオブジェクト数を削減する必要があります。移行するオブジェクト数を削減するために効果的な方法は、オブジェクト集約を利用することです。例えば、3 億 6500 万個のログオブジェクトを Amazon S3 Standard から Amazon S3 Glacier ストレージクラスの 1 つに移行させたいと仮定します。ライフサイクルの移行コストの目安は、以下のグラフで強調されています。
![]()
図 2: オブジェクト集約前のライフサイクル移行コスト
365 個のオブジェクトを 1 つのtarアーカイブに集約することで、Amazon S3 Glacier ストレージクラスへの移行回数を 100 万回まで減らすことができます。このブログを公開した時点では、100 万個のオブジェクトを集約した後のライフサイクル遷移コストの目安は 100 ドル程度です。このデータが示すように、オブジェクトの集約を利用することで、Amazon S3 Glacier ストレージクラスへのライフサイクル移行コストを大幅に削減することができます。
リファレンスアーキテクチャとソースコード
このユースケースに対処する AWS 環境でのソリューションを設計するには、様々な方法があります。ここで紹介するリファレンスアーキテクチャは、以下に示す要件を満たす producer / consumer のパターンです。
- アーカイブ内のファイル: アーカイブに埋め込むファイルは、最初に Amazon S3 からリストに登録する必要があります
- アーカイブの構築: アーカイブに埋め込むファイルは、Amazon S3 から読み込む必要があります
- アーカイブの圧縮: 作成された tar アーカイブは、圧縮されている必要があります
- Amazon S3 Glacier ストレージクラスにアーカイブをアップロード:圧縮されたアーカイブは、目的の Amazon S3 Glacier ストレージクラスにアップロードされます
完全なソリューションは、アーカイブの検索への影響など、アーカイブのエンドツーエンドのライフサイクルに関わる要件も考慮する必要があります。例えば、通常は一緒に復元されるオブジェクトは一緒に集約する必要があります。履歴データのコンテキストでは、集約は時間によって行われますが、デバイス ID やその他の一意の記述子など、様々なインデックス、名前付け、プレフィックス手法によって集約が行われることもあります。アーカイブへのオブジェクトのランダムな配置は、最終的に高い検索コストにつながるため、良い戦略とは言えません。具体的には、プロデューサーアプリケーションを設計する際に、検索パターンのコストを最適化するアーカイブのインデックス付け戦略(例:命名規則)を開発することです。このアーキテクチャは、独自のソリューションを構築するための出発点として使用することができますが、おそらく追加の要件があると思われます。
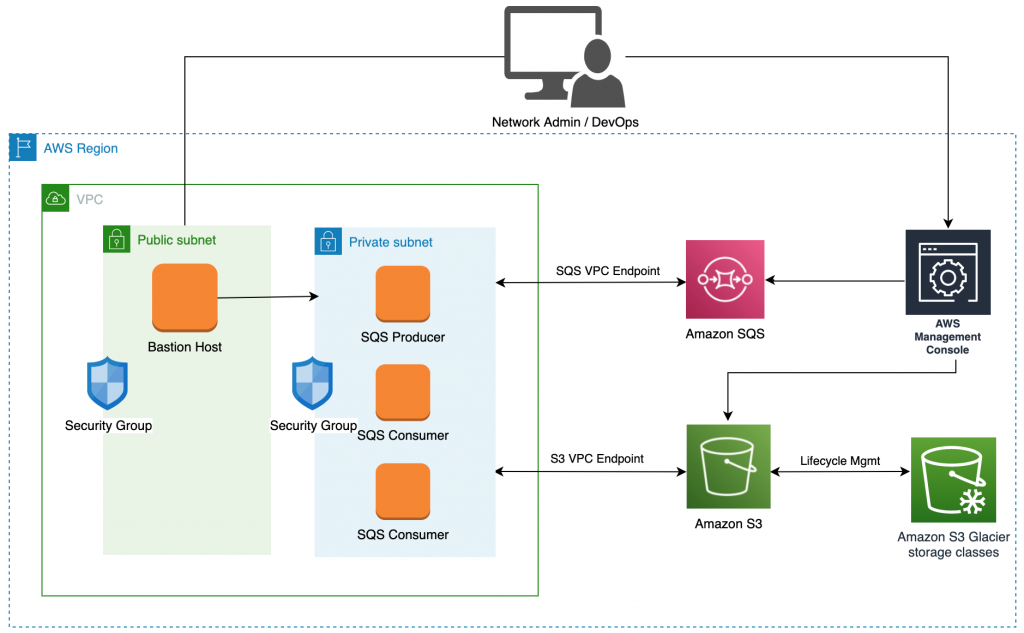
図 3: producer / consumer アーカイブリファレンスアーキテクチャ
プロデューサーとコンシューマー間の処理をオーケストレーションして調整するために、Amazon Simple Queue Service(SQS)を使用しました。Amazon SQS は、マイクロサービス、分散システム、サーバーレスアプリケーションのデカップリングとスケーリングを可能にするフルマネージドのメッセージキューイングサービスです。Amazon SQS は、メッセージ指向のミドルウェアの管理・運用に伴う複雑さとオーバーヘッドを排除し、開発者が差別化された作業に集中できるようにします。Amazon SQS を使用することで、ソフトウェアコンポーネント間で任意の量のメッセージを送信、保存、受信でき、メッセージを紛失したり、他のサービスを利用する必要がなくなります。
Amazon SQS プロデューサーは、シングルスレッドで Amazon EC2 インスタンスで動作するアプリケーションです。その機能は、ソースのAmazon S3 バケットからオブジェクトをリストし、アーカイブコンテキストを構築することです。アーカイブコンテキストオブジェクトは、アーカイブファイル(tar)に含まれるべきすべてのキーに関する情報を含む JSON blob です。Amazon SQS プロデューサーは、アーカイブコンテキスト(ワークアイテム)を Amazon SQS スタンダードキューにアップロードし、Amazon SQS コンシューマーが処理できるようにします。
Amazon SQS コンシューマーは、マルチスレッド、分散アプリケーションとして Amazon EC2 インスタンスで動作するアプリケーションです。Amazon SQS コンシューマーの機能は、Amazon SQS から受信したアーカイブコンテキストを取得して処理することです。アーカイブコンテキストを取得すると、Amazon SQS コンシューマーのスレッドまたはインスタンスは、コンテキストに含まれるすべてのオブジェクトを Amazon S3 から(非同期に)読み込みます。その後、オブジェクトをストリームとして圧縮アーカイブファイルストリーム(tar.gz)に書き込みます。圧縮されたアーカイブファイルが作成されると、Amazon SQS コンシューマーは目的の Amazon S3 Glacier ストレージクラスにアップロードし、Amazon SQS からアーカイブコンテキストを削除します。アーカイブに成功すると、Amazon SQS コンシューマーはオプションでアーカイブコンテキストに含まれるオブジェクトキーをソースバケットから削除することができます。
このリファレンス アーキテクチャの詳細と、このソリューションの構築に役立つサンプルソースコードについては、こちらの GitHub リポジトリを参照してください。
リファレンスアーキテクチャソリューションのコスト
ソリューションの全体的なコストに大きく影響するのは、今回紹介したアーキテクチャパターンに関連する AWS のコストです。このソリューションのコストを見積もるには、生成するアーカイブの数と生成に必要な時間(計算コスト)について、いくつかの仮定が必要です。ユースケースが当初定義したとおりであると仮定すると、4.5 億のログファイル、Amazon S3 Standard の 40 TB、アーカイブあたり 450 個のログファイル、100 万個のアーカイブオブジェクトを生成します。また、このワークロードは1ヶ月で完了すると仮定します。
- Amazon SQS のコスト試算:100万メッセージ/月の場合、Amazon SQS のコストは 0.48 ドルです
- Amazon SQS プロデューサー:コンピューティング集中型ではなく、Amazon EC2 無料利用枠で実行できます
- Amazon SQSコンシューマー:使用するインスタンス数とインスタンスタイプによって異なります。このコストは、どのようなパフォーマンスを求めるかにもよります。8 vcpu インスタンス、4 GB メモリ、8 TB SSD、1 Gbps ネットワークと想定した場合は、149.72 ドル/月です
- Amazon S3 Standard コスト:4.5 億ログファイルをリストして読み込む場合は ~ 1,130 ドル/月 です
- Amazon S3 Glacier コスト:4 TB/月、~ 14.75 ドル/月 です
- ライフサイクルコスト:0 ドルです(アプリケーションが Amazon S3 Glacier ストレージクラスに直接アップロードしているため)
- 合計:~ 1,294.95 ドル
Amazon S3 Glacier ストレージクラスへのアーカイブに関する今後の考慮事項
ワークロードを最適化し、バックアップ/アーカイブへの明確でコスト効率の良いパスが存在することを確認するためには、正しい問いかけをすることが重要です。アプリケーションのログ動作を変更することで、ライフサイクルの移行を少なくし、コストを削減することは可能でしょうか?もし答えが明確でない、あるいはコストがかかりすぎて効果的に実施できない場合は、別の質問が浮かび上がります。何百万ものライフサイクル遷移に関連するコストを削減するために、どのようにしてログをアーカイブファイルに集約し、圧縮すればよいでしょうか?再利用する可能性が高い効率的なアーカイブツールに投資し、それが正しい方法で設計されていることを確認することをお勧めします。設計上の考慮事項については、AWS ソリューションアーキテクト、AWS 認定パートナー、または AWS プロフェッショナルサービスに相談してください。さらに、オブジェクトアーカイブに向けた明確でコスト効率の良いパスが存在することを確認するために、ワークロードをさらに最適化する方法があるかどうかも尋ねてください。
Amazon S3 Glacier ストレージクラス(Amazon S3 Glacier Instant Retrieval、Amazon S3 Glacier Flexible Retrieval、Amazon S3 Glacier Deep Archive)は、データアーカイブ専用に設計されており、クラウドで最高のパフォーマンス、最も高い取得の柔軟性、最も低いコストのアーカイブストレージを提供するように設計されています。Amazon S3 Glacier ストレージクラスが提供するすべての利点を活用する前に、データをアーカイブストレージクラスに移行するための明確で簡潔な計画を持つことが不可欠です。
翻訳はプロフェッショナルサービス本部の葉山が担当しました。