AWS Storage Blog
Aggregate and compress logs for archiving to the Amazon S3 Glacier storage classes
In distributed architectures, there is often a need to preserve application logs, and for AWS customers preservation is often done via an Amazon S3 bucket. The logs may contain information on runtime transactions, error/failure states, or application metrics and statistics. These logs are later used in business intelligence to provide useful insights and generate dashboards, analytics, and reports. In some applications, log files serve as the ultimate source of truth and are essential for governance and audit purposes. As such, there is a need to retain logs permanently with high availability and durability guarantees. Many customers elect to write logs directly to S3 in various formats, while others prefer to stream logs via AWS services such as Amazon Kinesis.
In this blog post, I highlight some of the cost-related considerations of archiving millions of log files to the Amazon S3 Glacier storage classes. Amazon S3 Glacier storage classes (S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, and S3 Glacier Deep Archive) are secure, durable, and extremely low-cost Amazon S3 cloud storage classes for data archiving and long-term backup. To transition objects into the S3 Glacier storage classes, S3 offers the Amazon S3 Intelligent-Tiering storage class which is the only cloud storage class that delivers automatic storage cost savings when data access patterns change, without performance impact or operational overhead. Additionally, S3 also provides bucket/object lifecycle policies that can automatically take transition actions or expiration actions. Effective archival strategies serve to reduce storage costs while upholding high availability and durability guarantees for your data.
The data archiving use case detailed in this post originated directly from an AWS customer, Primex Inc. Primex, a sophisticated platform for monitoring vaccines and healthcare assets, took full advantage of the available AWS resources around object archiving to develop a solution that ultimately ended up reducing object transition costs into the S3 Glacier storage classes by over two orders of magnitude.
Note: For an alternative archive-focysed solution that uses the s3tar tool, rather than the Java-based method featured in this post, read this blog. For customers with Java development background, the solution in this post offers options to customize it to fit their specific needs and deployment methods. In addition, for further reading on aggregation to improve query performance, read this blog.
Primex Inc. archiving use case
Applications running over an IoT device fleet generated 450 million log files over a period of 3 years. The log files represented just over 40 TB of storage on the S3 Standard storage class, at an average object size of approximately 88 KB. With the desire to reduce costs of storing this seldom-accessed data, Primex considered archiving the data to S3 Glacier Flexible Retrieval (formerly S3 Glacier). Lifecycle transition costs are directly proportional to the number of objects being transitioned. Because Primex had a large number of small files to transition into S3 Glacier Flexible Retrieval (450 million), the cost to archive them via an effective lifecycle policy was comparatively high. Thus, the primary objective of the solution was to minimize the overall number of lifecycle transitions required to archive the data. This was achieved by taking advantage of log aggregation and compression.
Impact of log sizes on S3 Glacier storage costs
Objects that transition to S3 Glacier storage classes are stored with an additional 32 KB of data containing index information and related object metadata. In addition, S3 uses 8 KB of storage for the name of the object and other metadata, billed at S3 Standard storage rates. Together, these metadata objects allow you to identify, list, and retrieve your objects from S3, irrespective of what storage class they are in. Although any size objects can be archived into the S3 Glacier storage classes, due to this management storage overhead, it is inefficient to archive objects smaller than 128 KB. However, it is preferrable and recommended to aggregate smaller objects prior to archiving. This ensures that lifecycle transition costs and S3 Glacier storage overhead costs are minimized. The lifecycle policy configuration screen in the S3 console specifically warns of this issue and provides suggestions on how to avoid it:

Figure 1: Lifecycle policy cost caution message
In addition, an effective file compression protocol such as bzip2 or gzip may reduce storage requirements by up to an order of magnitude. In terms of storage related costs, it means that you are storing ten times more data for the same cost. Compression, however, doesn’t reduce the number of logs that will need to be archived into the S3 Glacier storage classes via lifecycle transitions. Therefore, object compression has no impact on lifecycle transition costs.
The S3 Glacier storage classes provide you with the lowest cost archive storage in the cloud. For more details on the S3 Glacier storage classes and associated costs, see the S3 storage classes FAQs.
Impact of number of logs on lifecycle transitions costs
If you have a business need to retain log files permanently while reducing storage costs, archiving to S3 Glacier storage classes are great options. In order to reduce costs associated with lifecycle transitions, it is important to minimize the number of logs generated. The number of logs that are generated depends upon the number of devices in the fleet and how frequently these devices produce logs (log rotation policy). Some applications commonly rotate logs by time interval, while others rotate logs by size. Understanding the logging behavior of your applications and the number of devices producing logs, should provide a good estimate of the total number of logs generated over a period of interest. Knowing the number of log files generated will allow you to estimate the archival costs associated with lifecycle transitions by utilizing the AWS Pricing Calculator.
In order to optimize the costs associated with lifecycle transitions, we must reduce the number of objects transitioning into the S3 Glacier storage classes. An effective way to reduce the number of objects to transition is to take advantage of object aggregation. For example, suppose that we want to transition 365 million log objects from S3 Standard into one of the S3 Glacier storage classes. The approximate lifecycle transition costs are highlighted in the graph below:
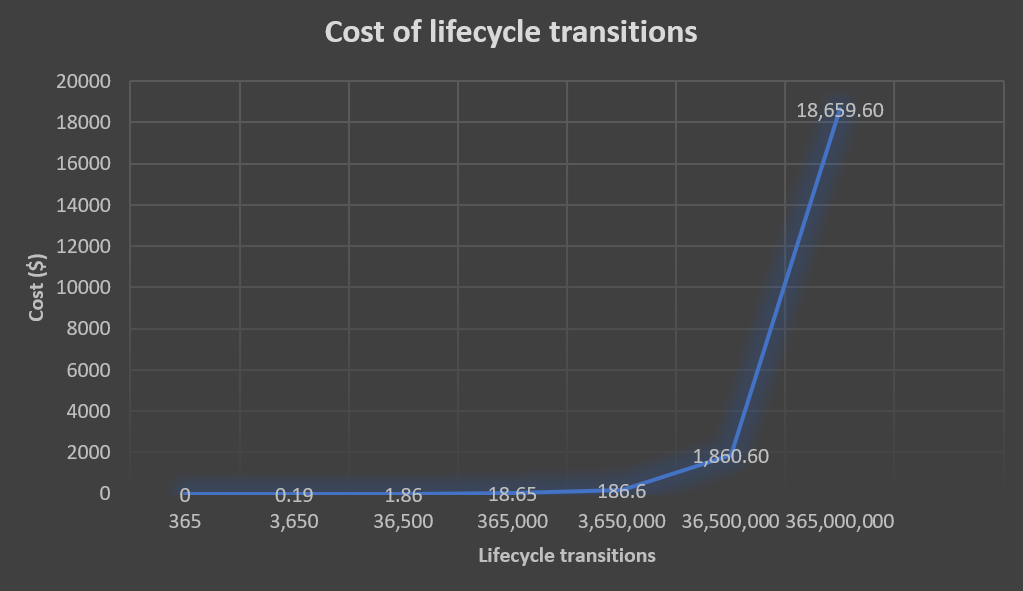
Figure 2: Cost of lifecycle transitions before object aggregation
By aggregating 365 objects into a single tar archive, we reduce the number of transitions into the S3 Glacier storage classes down to 1 million. At the time of publishing this blog, the approximate lifecycle transition costs after object aggregation for 1 million objects is around $100. As the data shows, we can significantly reduce the cost of lifecycle transitions into the S3 Glacier storage classes by utilizing object aggregation.
Reference architecture and source code
There are a variety of ways to design a solution that addresses this use case on AWS. The reference architecture presented here is a producer/consumer pattern that satisfies the requirements listed below:
- Files in archive: Files to be embedded in an archive must first be listed from S3
- Building an archive: Files to be embedded in an archive must be read from S3
- Archive compression: The resulting tar archive must be compressed
- Upload archive to the S3 Glacier storage classes: The compressed archive is uploaded to the desired S3 Glacier storage class
A complete solution would also take into account requirements around the end-to-end lifecycle of archives including impacts on archive retrievals. For example, you should typically aggregate objects together that will be restored together. In the context of temporal data, that would be by time, but it could also be by a variety of indexing, naming, or prefixing techniques such as by device ID or other unique descriptors. Doing random placement of objects into archives is not a good strategy as it will eventually lead to high retrieval costs. Specifically, when designing the producer application, develop an indexing strategy (e.g. naming convention) for the archives that optimizes the cost of your retrieval patterns. This architecture can be used as a starting point towards constructing your own solution that will likely have additional requirements.
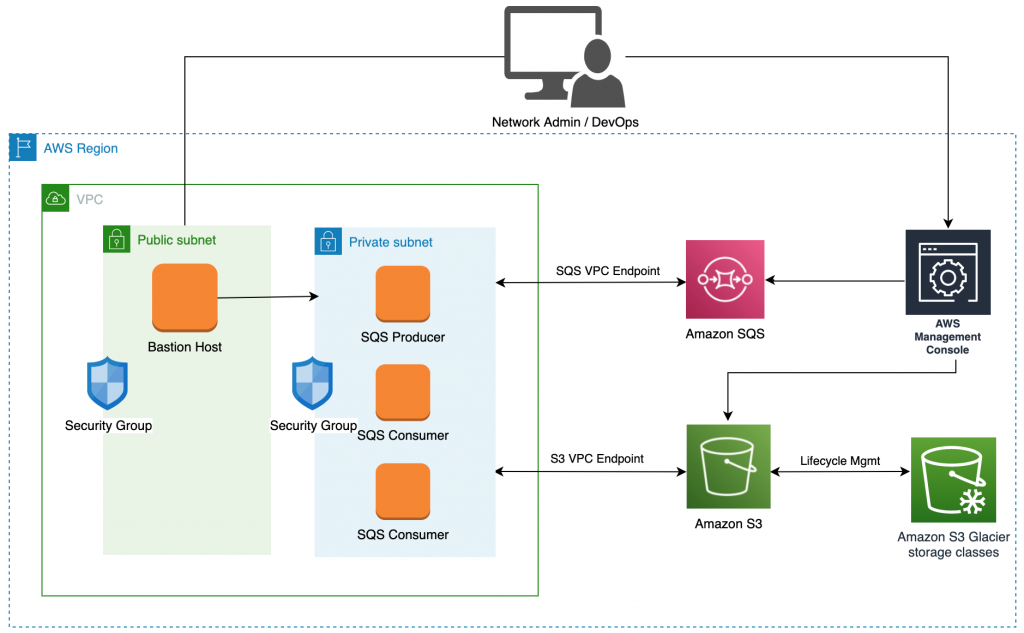
Figure 3: Producer/consumer archiving reference architecture
In order to orchestrate and coordinate processing between the producer and consumers, we used Amazon Simple Queue Service (SQS). Amazon SQS is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. SQS eliminates the complexity and overhead associated with managing and operating message-oriented middleware, and empowers developers to focus on differentiating work. Using SQS, you can send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be available.
The SQS Producer is a single-threaded application and runs on an Amazon EC2 instance. Its function is to list objects from the source S3 bucket and construct archive contexts. An archive context object is a JSON blob that contains information about all the keys that should be included in an archive file (tar). The SQS Producer then uploads archive contexts (work items) to an SQS Standard Queue where they can be processed by SQS Consumers.
SQS Consumers are applications that may be multi-threaded, distributed, and run on EC2 instances. Their function is to retrieve and process archive contexts received from SQS. Upon retrieving an archive context, the SQS Consumer thread or instance will read all the objects included in the context from S3 (asynchronously). It will then write the objects as streams into a compressed archived file stream (tar.gz). Once the compressed archive file is created, SQS Consumer will then upload it to the desired S3 Glacier storage class and delete the archive context from SQS. Upon successful archival, the SQS Consumer can optionally delete the object keys included in the archive context from the source bucket.
For more details on this reference architecture as well as sample source code to help in building out this solution, view this GitHub repository.
Reference architecture solution cost
Of significant consideration to the overall cost of the solution are the AWS costs associated with the architecture pattern presented. In order to estimate costs for this solution, some assumptions must be made about the number of archives to be generated and the time required to generate them (compute costs). Assuming that the use case remains as originally defined: 450 million log files, 40 TB on S3 Standard, and 450 log files per archive yielding 1 million archive objects. Let’s also assume that this workload will complete in one month.
- SQS Costs Estimates: For 1 million messages/month the SQS costs are $0.48
- SQS Producer: Not compute intensive and can be executed on the Amazon EC2 free tier
- SQS Consumers: Depends on the number of instances used and what type of instance. This cost is also driven by what performance is desired. Assuming one 8 vcpu instance, 4 GB memory, 8 TB SSD, 1 Gbps network ~ $149.72 / month
- S3 Standard Costs: List and read 450 million log files ~ $1,130/month
- S3 Glacier Costs: 4 TB/month ~ $14.75/month
- Lifecycle Costs: $0 (since application is uploading to Amazon S3 Glacier storage classes directly)
- Total: ~ $1,294.95
Future considerations for archiving to the S3 Glacier storage classes
Asking the right questions is critical in optimizing your workloads to ensure that a clear and cost-effective path toward backup/archiving exists. Can the application logging behavior be modified to yield fewer lifecycle transitions and thus reduce cost? If the answer isn’t clear or is too costly to implement effectively, then another question emerges. How can I aggregate and compress logs into archive files to reduce costs associated with millions of lifecycle transitions? It is good practice to invest in an efficient archiving tool that you are likely to reuse and ensure it is designed the right way. Talk to your AWS Solutions Architect, an AWS Certified Partner, or AWS Professional Services to help with design considerations. In addition, ask if there are ways to further optimize your workloads to ensure a clear and cost-effective path toward object archiving exists.
The Amazon S3 Glacier storage classes (Amazon S3 Glacier Instant Retrieval, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive) are purpose-built for data archiving, and are designed to provide you with the highest performance, the most retrieval flexibility, and the lowest cost archive storage in the cloud. Prior to taking advantage of all that the S3 Glacier storage classes offer, it is imperative to have a clear and concise plan for migrating data to archival storage classes.
Thanks for reading this blog post! If you have any questions or suggestions, please leave your feedback in the comments section.