Amazon Web Services ブログ
Cortica が Amazon HealthLake を使用してより深い洞察を得て患者ケアを改善する方法
この記事は、“How Cortica used Amazon HealthLake to get deeper insights to improve patient care” を翻訳したものです。
これは、Cortica のエンタープライズアプリケーションおよびデータの責任者である Ernesto DiMarino (エルネスト・ディマリノ) によるゲスト投稿です。
Cortica は、自閉症やその他の神経発達症を持つ子供たちの医療に革命を起こすというミッションを達成するため日々活動をしています。Cortica は、多くの家族が子供の診断と治療法を探す時に典型的に辿る、統一されていないバラバラなユーザー体験を解決するために設立されました。目的を実現するために、Cortica では、神経学、研究ベースの治療法、テクノロジーをシームレスに融合させ、彼らが支える子供たちに包括的なケアプログラムを提供しています。この調和した取り組みは、利用者にとって最高の満足度に繋がり、家族の長く続く改善の達成を支援します。
この記事では、Cortica が Amazon HealthLake を使用してデータ分析ハブを構築し、患者の病歴、投薬歴、行動評価、検査レポート、および遺伝子変異を Fast Healthcare Interoperability Resource (FHIR) 標準フォーマットで保存する方法について説明します。また、患者の健康行程の合成図を作成し、高度な分析を適用して、Cortica の治療法による患者の進行の傾向を理解しています。
データの統一
Cortica の 3 人のデータエンジニアチームが抱えていた課題は他の医療企業と同じです。Cortica には 2種類のEHR(電子健康記録)、6つの専門分野、420のプロバイダー、および数種類のデータ収集用のアンケートを持っています。アンケートは独自の仕様であり、そのうちの1つは 842 個の質問があります。システムとデータソリューションが複数のベンダーから提供されているため、Cortica は、大量のデータ、多様なデータフォーマット、システム間で患者を照合する際の複雑さに悩まされるという医療業界でよくある状況に陥っています。この複雑さの一部を解決するために、Cortica は AWS にデータレイクを構築しました。
Cortica のチームは、すべてのデータを Amazon Simple Storage Service (Amazon S3) データレイクに取り込むために、Python の抽出、変換、ロード (ETL) を Apache Airflow で統合しました。さらに、財務分析と運用分析のために、キンボールモデルの星型スキーマを維持しています。データサイズは 16TB になり、かなりのサイズです。大抵のファイルフォーマットは CSV、PDFと Parquet になり、データレイクはこれらを十分に管理できます。ただし、データレイクソリューションはこの事例の一部にすぎません。データから真に価値を引き出すために、Cortica は、医療特有の言語や語彙、又は業界の多くの標準化されたコードセットを処理するために、標準化されたモデルを必要としていました。
データからより深い価値を引き出す
データレイクと星型スキーマのデータモデルは、一部の財務分析と運用分析には適していますが、有意義な洞察を患者と介護者に共有するために、データを深く掘り下げることは難しいと Cortica チームは気づきました。Cortica チームが解決したかった問題点の一部は次のようになります:
- Cortica は、患者の健康行程の合成図を介護者に提示するにはどうしたらよいですか?
- 標準化された評価、診療記録、目標追跡データを用いて、時間の経過とともに患者の状態が良くなっていることをどのように証明できますか?
- 特定の併存症のある患者は、そうでない患者に比べて、どのように目標に向かって進行していますか?
- Cortica は、独特な複数の専門的アプローチにより、患者がより良いアウトカムを得るかをどのように証明できますか?
- Cortica は、匿名化されたデータを共有し、業界の研究者とパートナーを組むことで、自閉症やその他の神経発達症のさらなる治療を支援できますか?
データレイクを構築する前に、スタッフは PDF、Excel、及びベンダーのシステムに目を通し、欲しい観測値をまとめる目的で Excel ファイルを作成していました。EHR を取り調べ、分析のために手動で文書やメモを大きなスプレッドシートに転写するには、数ヶ月の作業が必要でした。このプロセスは拡張性がなく、分析と洞察を再現することが困難でした。
データレイクを導入した Cortica は、大量のデータに素早くアクセスしたり、複雑な分析のために様々なデータセットを結合したりすることが未だに困難であることがわかりました。医療データは医学用語集によって駆動されるため、Cortica が提供するさまざまな専門分野を通じて明確な患者行程を提示するために、さまざまな医療分野のデータを統合するのに役に立つソリューションが必要とされていました。このより深い価値をすばやく引き出すために、Cortica は Amazon HealthLake を選択しました。これは、データにこの一層追加された意味を提供するためです。
Cortica のソリューション
データの標準化と大規模の洞察を促進するために、Cortica は Amazon HealthLake を採用しました。FHIR 標準の実装を通じて、Amazon HealthLake は、データの標準化のために、より迅速なソリューションを提供し、運用保守の難易度もかなり下げました。彼らは基本となるリソースのセットを Amazon HealthLake にすばやくロードすることができました。これにより、Cortica のチームは概念実証(POC)を行い、患者集団を焦点にしたより大規模な疑問を解けることが始まりました。3日間の中で、行動療法目標と医学の併存症の観点から患者の行程を理解するために、POC を開発することができました。その3日間のプロセスのうち、二日間は Amazon QuickSight でのクエリの微調整とデータの可視化に費やしました。データから可視化の観点まで、データは数ヶ月ではなく数時間で準備できました。次の図は、そのパイプラインを示しています。
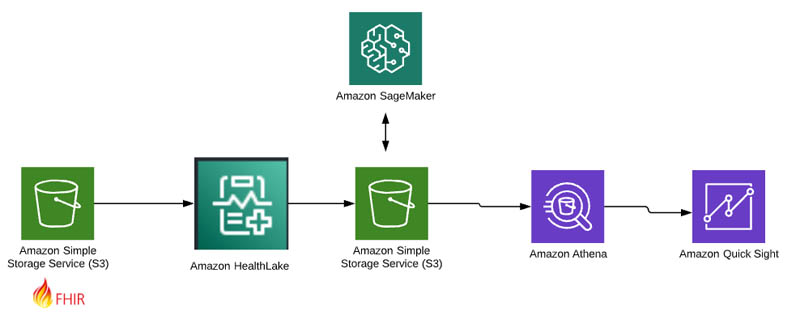
洞察をより早く得る
Cortica は、患者が目標を達成するのにかかった時間の長さを、患者集団全体で迅速に確認することができました。そして、チームは年齢の表現型(Cortica の患者集団を比較するために、指定された年齢層)で分類することができます。彼らは、目標を達成している患者が 4、6、9、12 ヶ月の間隔でグループに分かれることを発見しました。さらに、目標の状態などさまざまなカテゴリーを細かく分けて、積み重ねるように可視化しました。これまで、スタッフと臨床医は患者集団レベルのデータではなく、個人レベルのデータしか考察できませんでした。そのため、このような洞察を得られませんでした。この目標分析のために、臨床医によるチャートの抽象化プロセスを手動で行う場合は、完了するまで数ヶ月かかっていたでしょう。
次のグラフは、患者の目標の可視化の二種を示しています。
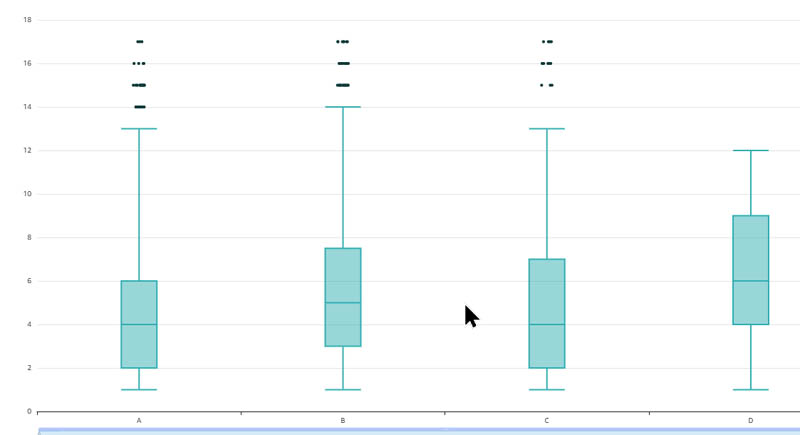

この POC のすぐあとに、Cortica は医学の併存症が目標の達成に、どのように影響したかを見たいと考えました。患者集団内で共通に見られていたため、特定の併存症において、発作、便秘、睡眠障害が注目されました。FHIR Condition Resource 関連のデータはパイプラインにロードされることによって、Cortica のチームは併存症別のコホートを特定し、情報をすばやく可視化することができました。数分で可視化が実行され、これらの併存症が目標達成に及ぼす影響も確認できました(次の図例を参照)。

Amazon HealthLake を使用すると、Cortica チームは、データパターンの分析と理解により多くの時間を配分することができ、データの出典の特定、フォーマットの整備、使用可能な状態のための結合処理、といった作業が要らなくなりました。Amazon が医療機関にもたらす価値は、データを移動し、一致させ、可視化を迅速に開始できることです。FHIR をデータモデルとして使用することで、小規模な非技術チームが組織の統合チームに、関心の FHIR リソースを構造のないファイルで S3 バケットに提供するように依頼することができます。このデータは、 AWS コマンドラインインターフェイス (AWS CLI)、AWS マネジメントコンソール、または API を介して、Amazon HealthLake データストアに簡単にロードできます。次に、SQL クエリ可能なツールにデータを公開するために Amazon Athena でクエリを実行でき、データを可視化するために、QuickSight を利用できます。臨床チームと非技術チームは、このソリューションを使用して、医療記録システム内に閉じ込められたデータから価値を引き出すことができます。
まとめ
Amazon HealthLake、 Amazon SageMaker、Athena、 Amazon Comprehend Medical、QuickSight などAWS をで利用可能なツールは、Cortica が支える患者集団に対して、実行可能な時間枠以内でより多くのこと知る能力を加速させています。数ヶ月かかっていた分析は、今では数日で、場合によっては数時間で完了できます。AWS のツールは、数分でデータに豊富なレイヤーを追加して分析を強化し、同じ分析の異なるビューを提供できます。さらに、チャートの抽象化が必要な分析は、自動化されたデータパイプラインを介して、何百、何千ものドキュメントを処理して、以前は少数の臨床医しか利用できなかったノートから洞察を引き出すことができるようになりました。
Cortica は、データパイプラインとプロセスにデータエンジニアや技術スタッフを不要な新しいデータ分析の時代に入っています。未知のことはデータから学ぶことができ、最終的には、Cortica が小児医療分野に革命をもたらし、家族の長く続く改善の達成をもたらすミッションに近づくことができます。
この投稿に記載されている内容および意見は、第三者である筆者のものであり、AWS はこの投稿の内容や正確性について責任を負いません。
著者について
Ernesto DiMarino は、Cortica のエンタープライズアプリケーションおよびデータ部門の責任者です。
Satadal Bhtatacharjee は、AWS Health AI で製品をリードするプロダクトマネジメント担当およびシニアマネージャーです。ヘルスケアのお客様からワーキングバックワーズの仕組みを利用して、Amazon HealthLake や Amazon Comprehend Medical などのサービスを開発することで、お客様がデータを理解できるように支援しています。
翻訳は Healthcare Solutions Architect の何勇と窪田が担当しました。原文はこちらです。