Amazon Web Services ブログ
Amazon Kinesis Data Analytics Studio の概要 – SQL、Python、または Scala を使用してストリーミングデータをすばやく操作する
タイムリーなインサイトを得て、ビジネスとアプリケーションから受け取った新しい情報に迅速に対応するための最善の方法は、ストリーミングデータを分析することです。これは通常、レコード単位または変動する時間枠で連続的かつ増分的に処理する必要があるデータのことで、相関、集計、フィルタリング、サンプリングなどのさまざまな分析に使用できます。
ストリーミングデータの分析を容易にするために、Amazon Kinesis Data Analytics Studio を紹介します。
まず、Amazon Kinesis コンソールから Kinesis データストリームを選択し、1 回クリックするだけで、Apache Zeppelin と Apache Flink を搭載した Kinesis Data Analytics Studio ノートブックを起動し、ストリーム内のデータをインタラクティブに分析できるようになりました。
同様に、Amazon Managed Streaming for Apache Kafka コンソールでクラスターを選択してノートブックを起動し、Apache Kafka ストリーム内のデータを分析することができます。また、Kinesis Data Analytics Studio コンソールからノートブックを起動して、カスタムソースに接続することもできます。

ノートブックでは、ストリーミングデータを操作し、SQLクエリと Python または Scala プログラムを使用して数秒で結果を得ることができます。結果に満足したら、数回クリックするだけで、コードを本番稼働用ストリーム処理アプリケーションにプロモートして、追加の開発作業なしで確実かつ大規模に実行することができます。
新しいプロジェクトの場合は、Kinesis Data Analytics for SQL アプリケーションではなく、新しい Kinesis Data Analytics Studio を使用することをお勧めします。Kinesis Data Analytics Studio は、使いやすさと高度な分析機能を兼ね備えており、洗練されたストリーム処理アプリケーションを数分で構築できます。では、実際にどのように機能するか見てみましょう。
Kinesis Data Analytics Studio を使用してストリーミングデータを分析する
いくつかのセンサーから Kinesis データストリームに送信されたデータをさらに詳細に理解したいとします。
ワークロードをシミュレートするために、この random_data_generator.py Python スクリプトを使用します。Kinesis Data Analytics Studio を使用するのに Python の知識は必要ありません。実際に、次の手順で SQL を使用します。また、コーディングを行わずに、Amazon Kinesis Data Generator ユーザーインターフェイス (UI) を使用して、テストデータを Kinesis Data Streams または Kinesis Data Firehose に送信することもできます。これから、Python スクリプトを使用して、送信されるデータをより細かく制御しています。
import datetime
import json
import random
import boto3
STREAM_NAME = "my-input-stream"
def get_random_data():
current_temperature = round(10 + random.random() * 170, 2)
if current_temperature > 160:
status = "ERROR"
elif current_temperature > 140 or random.randrange(1, 100) > 80:
status = random.choice(["WARNING","ERROR"])
else:
status = "OK"
return {
'sensor_id': random.randrange(1, 100),
'current_temperature': current_temperature,
'status': status,
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
while True:
data = get_random_data()
partition_key = str(data["sensor_id"])
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data(STREAM_NAME, kinesis_client)このスクリプトにより、JSON 構文を使用して Kinesis データストリームにランダムなレコードが送信されます。以下はその例です。
Kinesis コンソールから、Kinesis データストリーム (my-input-stream) を選択し、[Process (プロセス)] ドロップダウンから [Process data in real time (データをリアルタイムで処理)] を選択します。このようにして、ストリームはノートブックのソースとして構成されます。

次に、以下のダイアログボックスで、Apache Flink – Studio ノートブックを作成します。
ノートブックの名前 (my-notebook) と説明を入力します。前に選択した Kinesis データストリーム ( my-input-stream) から読み取るための AWS Identity and Access Management (IAM) アクセス権限が、ノートブックが引き受ける IAM ロールに自動的にアタッチされます。

[Create (作成)] を選択して AWS Glue コンソールを開き、空のデータベースを作成します。Kinesis Data Analytics Studio コンソールに戻り、リストを更新して、新しいデータベースを選択します。ソースと送信先のメタデータを定義します。ここから、Studio ノートブックのデフォルト設定を確認することもできます。次に、[Create Studio notebook (Studio ノートブックの作成)] を選択します。

ノートブックが作成されたので、[Run (実行)] を選択します。
ノートブックの実行中に、[Open in Apache Zeppelin (Apache Zeppelin で開く)] を選択してノートブックにアクセスします。SQL、Python、または Scala でコードを記述して、ストリーミングデータを操作し、リアルタイムで洞察を得ることができます。
ノートブックで、新しいノートを作成し、Sensors という名前を付けます。次に、ストリーム内のデータの形式を記述する sensor_data テーブルを作成します。
%flink.ssql
CREATE TABLE sensor_data (
sensor_id INTEGER,
current_temperature DOUBLE,
status VARCHAR(6),
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
)
PARTITIONED BY (sensor_id)
WITH (
'connector' = 'kinesis',
'stream' = 'my-input-stream',
'aws.region' = 'us-east-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
)
前のコマンドの最初の行は Apache Zeppelin に Apache Flink インタープリタ用のストリーム SQL 環境 (%flink.ssql) を提供するように指示します。また、バッチ SQL 環境 (%flink.bsql)、Python (%flink.pyflink) または Scala (%flink) コードを使用してストリーミングデータを操作することもできます。
CREATE TABLE ステートメントの最初の部分は、SQL とデータベースを使用したことのあるユーザーにはよく知られています。ストリームにセンサーデータを格納するためのテーブルが作成されます。WATERMARK オプションは、Apache Flink ドキュメントの「Event Time and Watermarks」セクションで説明されているように、イベント時間の進行状況を測定するために使用されます。
CREATE TABLE ステートメントの 2 番目の部分は、テーブル内のデータの受信に使用されるコネクタ (kinesis または kafka など)、ストリームの名前、AWS リージョン、ストリームの全体的なデータ形式 (json や csv など)、タイムスタンプに使用される構文 (この場合は ISO 8601) について記述します。ストリームを処理する開始位置を選択することもできます。最新のデータを最初に読み込むために LATEST を使用することにします。
テーブルの準備ができたら、ノートブックを作成したときに選択した AWS Glue Data Catalog でそれを探します。

これで、sensor_data テーブルでSQLクエリを実行し、スライドウィンドウまたはタンブリングウィンドウを使用して、センサーに生じている事柄をより深く理解することができます。
ストリーム内のデータの概要を得るには、簡単な SELECT から始めて sensor_data テーブルのすべてのコンテンツを取得します。
%flink.ssql(type=update)
SELECT * FROM sensor_data;今回は、コマンドの最初の行にはパラメータ (type=update) があり、新しいデータが到着すると、SELECT の出力が継続的に更新されます。これは複数行になっています。
ノートパソコンの端末で、random_data_generator.py スクリプトを起動します。
最初は、データが入っているテーブルがそのまま表示されます。さらに詳しく理解するために、棒グラフビューを選択します。次に、以下に示すように、結果を status でグループ化して、その current_temperature を表示します。
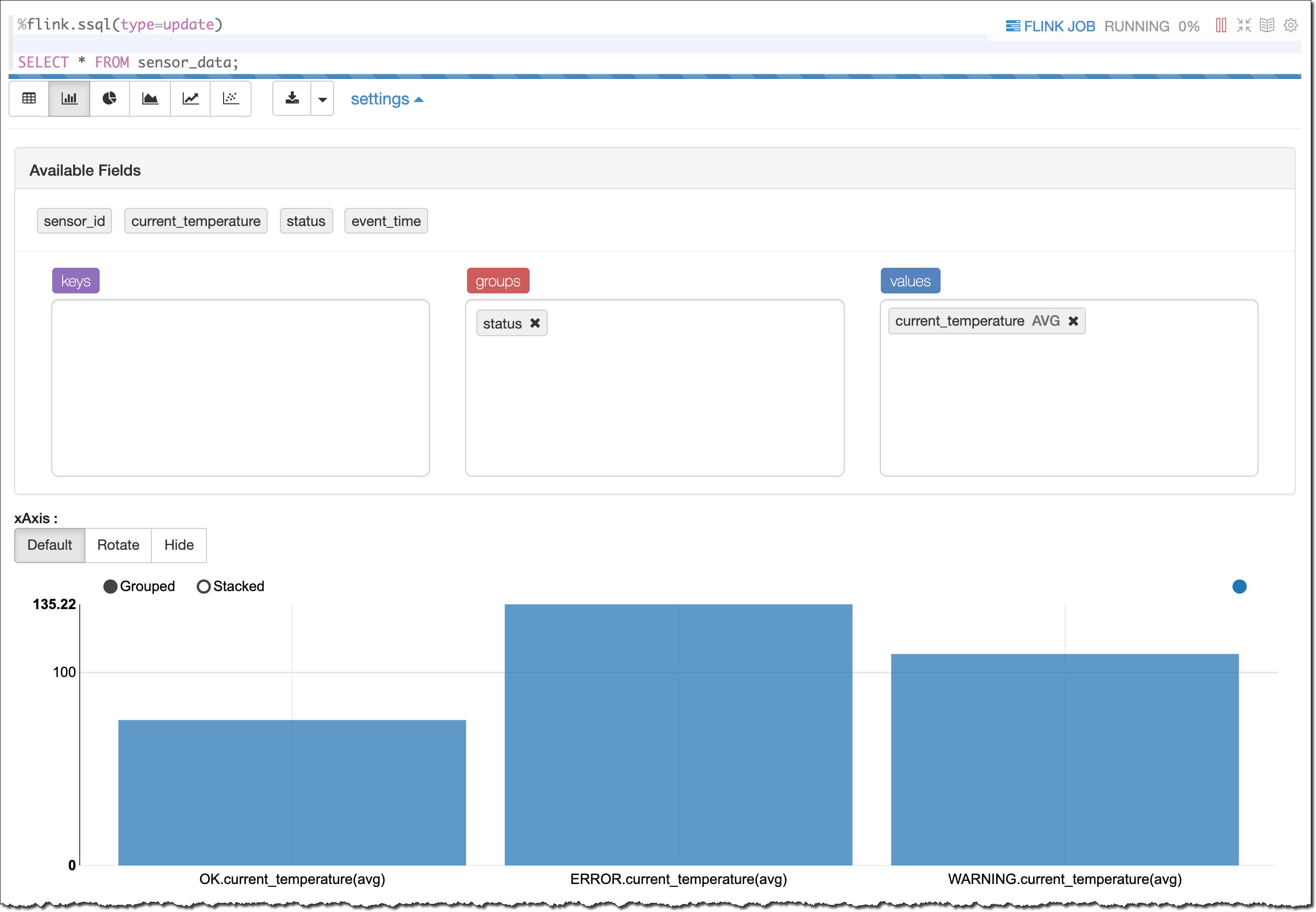
この結果から予想されるように、status (OK、WARNING、または ERROR) に応じて平均温度は異なります。温度が高いほど、センサーで何かが正しく作動していない可能性が高くなります。
SQL 構文を使用して集約クエリを明示的に実行できます。今回は、10 秒ごとに更新される結果を、1 分間のスライディングウィンドウで計算します。これを行うために、SELECT ステートメントの GROUP BY セクションで HOP 関数を使用します。select の出力の時間を追加するには、HOP_ROWTIME 関数を使用します。詳細については、Apache Flink ドキュメントのグループウィンドウ集約の仕組みをご覧ください。
%flink.ssql(type=update)
SELECT sensor_data.status,
COUNT(*) AS num,
AVG(sensor_data.current_temperature) AS avg_current_temperature,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_time
FROM sensor_data
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), sensor_data.status;今回は、結果を表形式で確認します。

クエリの結果を送信先ストリームに送信するには、テーブルを作成し、テーブルをストリームに接続します。まず、ストリームに書き込むためにノートブックにアクセス権限を与える必要があります。
Kinesis Data Analytics Studio コンソールで、my-notebook を選択します。次に、[Studio notebooks details (Studio ノートブックの詳細)] セクションで、[Edit IAM permissions (IAM アクセス権限の編集)] を選択します。ここで、ノートブックで使用されるソースと送信先を設定すると、IAM ロールのアクセス権限が自動的に更新されます。

[Included destinations in IAM policy (IAM ポリシーに含まれる送信先)] セクションで送信先を選択し、my-output-stream を選択します。変更を保存し、ノートブックが更新されるのを待ちます。これで送信先ストリームを使用する準備ができました。
ノートブックで、my-output-stream に接続された sensor_state テーブルを作成します。
%flink.ssql
CREATE TABLE sensor_state (
status VARCHAR(6),
num INTEGER,
avg_current_temperature DOUBLE,
hop_time TIMESTAMP(3)
)
WITH (
'connector' = 'kinesis',
'stream' = 'my-output-stream',
'aws.region' = 'us-east-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601');ここで、この INSERT INTO ステートメントを使用して、SELECT の結果を sensor_state テーブルに継続的に挿入します。
%flink.ssql(type=update)
INSERT INTO sensor_state
SELECT sensor_data.status,
COUNT(*) AS num,
AVG(sensor_data.current_temperature) AS avg_current_temperature,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_time
FROM sensor_data
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), sensor_data.status;
データは、他のアプリケーションで使用できるように、送信先の Kinesis データストリーム (my-output-stream ) にも送信されます。たとえば、送信先ストリーム内のデータは、リアルタイムダッシュボードを更新したり、ソフトウェアの更新後のセンサーの動作を監視するために使用できます。
満足のいく結果になりました。このクエリとその出力を Kinesis Analytics アプリケーションとしてデプロイします。
まず、ノートブックに SensorsApp ノートを作成し、アプリケーションの一部として実行するステートメントをコピーします。テーブルは既に作成されているので、上記の INSERT INTO ステートメントをコピーするだけです。
次に、ノートブックの右上にあるメニューから [Build SensorsApp and export to Amazon S3 (SensorsApp をビルドして Amazon S3 にエクスポート)] を選択して、アプリケーション名を確認します。

エクスポートの準備ができたら、同じメニューで [Deploy SensorsApp as Kinesis Analytics application (SensorsApp を Kinesis Analytics アプリケーションとしてデプロイ)] を選択します。その後、アプリケーションの構成を微調整します。入力した Kinesis データストリームにはシャードが 1 つしかなく、トラフィックも多くはないため、並列度を 1 に設定しました。次に、コードを記述しないでアプリケーションを実行します。
Kinesis Data Analytics アプリケーションコンソールから [Open Apache Flink dashboard (Apache Flink ダッシュボードを開く)] を選択して、アプリケーションの実行に関する詳細情報を取得します。

利用可能なリージョンと料金
現在、Amazon Kinesis Data Analytics Studio は、Kinesis Data Analytics が一般に利用可能なすべての AWS リージョンで使用できます。詳細については、AWS リージョン別のサービス表をご覧ください。
Kinesis Data Analytics Studio では、オープンソースバージョンの Apache Zeppelin と Apache Flink を実行し、上位の変更に貢献しています。たとえば、Apache Zeppelin のバグ修正に貢献したり、Kinesis Data Streams や Kinesis Data Firehose 用の AWS コネクタなど、Apache Flink 用の AWS コネクタにも貢献しています。また、Apache Flink のコミュニティと協力して、実行時のエラーを自動的に分類し、エラーがユーザーコードにあるのか、それともアプリケーションインフラストラクチャにあるのかを把握するなど、可用性の向上に貢献しています。
Kinesis Data Analytics Studio では、実行中のノートブックで使用されているものも含め、1 時間あたりの Kinesis 処理ユニット (KPU) の平均数に基づいて料金が発生します。1 つの KPU は、1 vCPU のコンピューティング、4 GB のメモリ、および関連するネットワークで構成されます。また、実行中のアプリケーションストレージと耐久性の高いアプリケーションストレージについても料金が発生します。詳細については、Kinesis Data Analytics の料金ページをご覧ください。
Kinesis Data Analytics Studio を今すぐ使用して、ストリーミングデータからより優れたインサイトを得ましょう。
— Danilo