AWS Big Data Blog
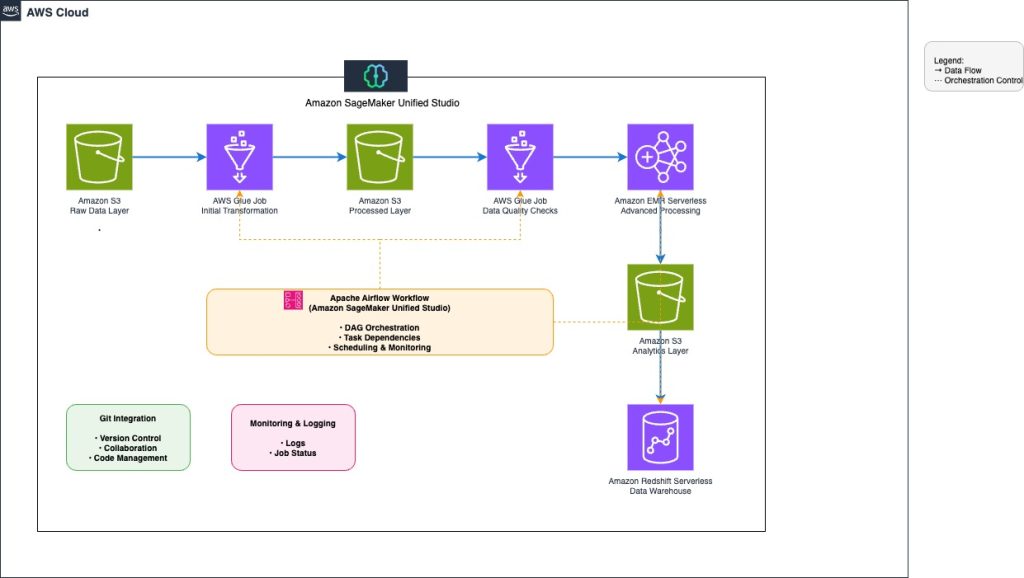
Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows
This post explores how to build and manage a comprehensive extract, transform, and load (ETL) pipeline using SageMaker Unified Studio workflows through a code-based approach. We demonstrate how to use a single, integrated interface to handle all aspects of data processing, from preparation to orchestration, by using AWS services including Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This solution streamlines the data pipeline through a single UI.
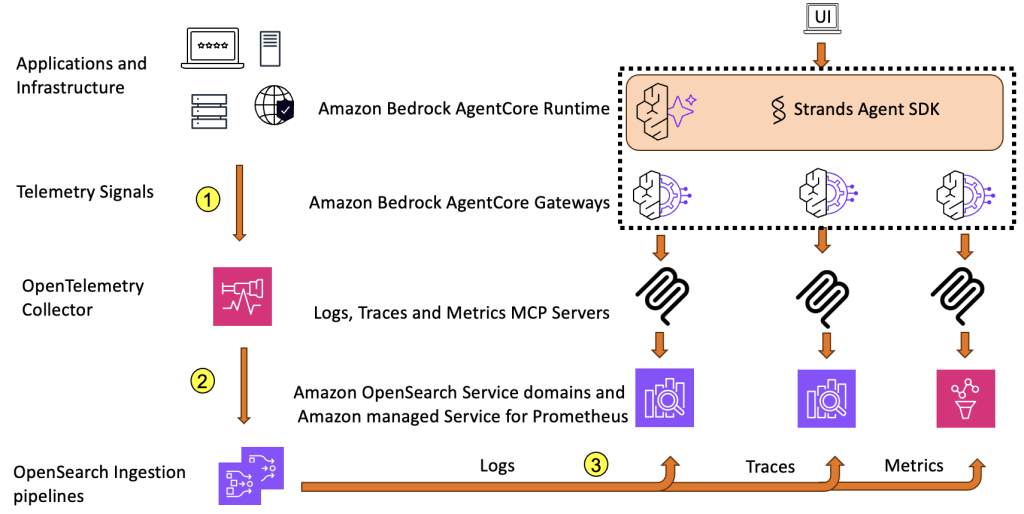
Reduce Mean Time to Resolution with an observability agent
In this post, we present an observability agent using OpenSearch Service and Amazon Bedrock AgentCore that can help surface root cause and get insights faster, handle multiple query-correlation cycles, and ultimately reduce MTTR even further.

Amazon OpenSearch Ingestion 101: Set CloudWatch alarms for key metrics
This post provides an in-depth look at setting up Amazon CloudWatch alarms for OpenSearch Ingestion pipelines. It goes beyond our recommended alarms to help identify bottlenecks in the pipeline, whether that’s in the sink, the OpenSearch clusters data is being sent to, the processors, or the pipeline not pulling or accepting enough from the source. This post will help you proactively monitor and troubleshoot your OpenSearch Ingestion pipelines.

Use Amazon MSK Connect and Iceberg Kafka Connect to build a real-time data lake
In this post, we demonstrate how to use Iceberg Kafka Connect with Amazon Managed Streaming for Apache Kafka (Amazon MSK) Connect to accelerate real-time data ingestion into data lakes, simplifying the synchronization process from transactional databases to Apache Iceberg tables.

Optimizing Flink’s join operations on Amazon EMR with Alluxio
In this post, we show you how to implement real-time data correlation using Apache Flink to join streaming order data with historical customer and product information, enabling you to make informed decisions based on comprehensive, up-to-date analytics. We also introduce an optimized solution to automatically load Hive dimension table data into Alluxio Universal Flash Storage (UFS) through the Alluxio cache layer. This enables Flink to perform temporal joins on changing data, accurately reflecting the content of a table at specific points in time.

Federate access to Amazon SageMaker Unified Studio with AWS IAM Identity Center and Ping Identity
In this post, we show how to set up workforce access with SageMaker Unified Studio using Ping Identity as an external IdP with IAM Identity Center.
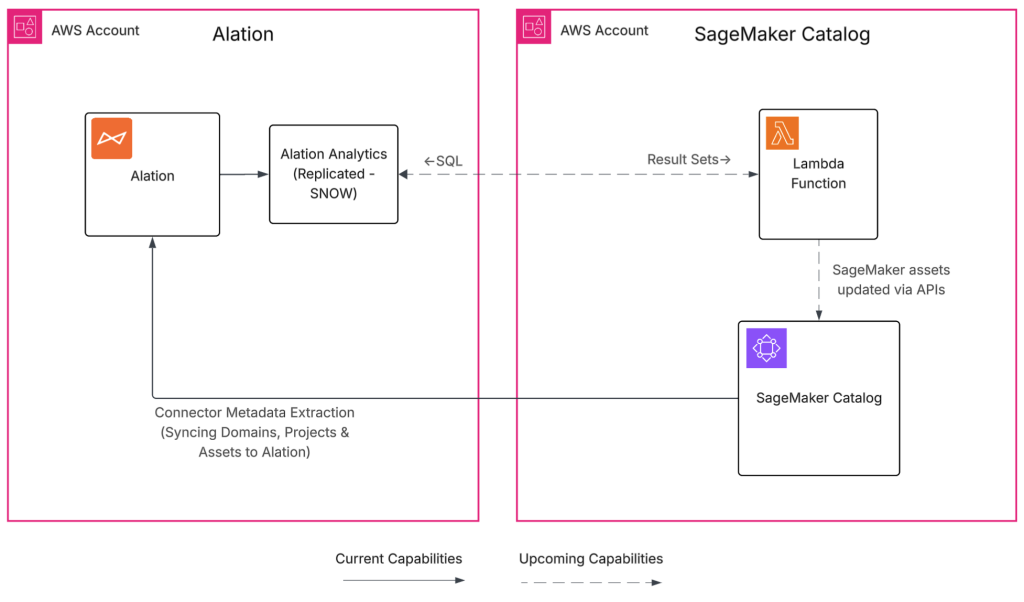
Build a trusted foundation for data and AI using Alation and Amazon SageMaker Unified Studio
The Alation and SageMaker Unified Studio integration helps organizations bridge the gap between fast analytics and ML development and the governance requirements most enterprises face. By cataloging metadata from SageMaker Unified Studio in Alation, you gain a governed, discoverable view of how assets are created and used. In this post, we demonstrate who benefits from this integration, how it works, the specific metadata it synchronizes, and provide a complete deployment guide for your environment.

Reduce EMR HBase upgrade downtime with the EMR read-replica prewarm feature
In this post, we show you how the read-replica prewarm feature of Amazon EMR 7.12 improves HBase cluster operations by minimizing the hard cutover constraints that make infrastructure changes challenging. This feature gives you a consistent blue-green deployment pattern that reduces risk and downtime for version upgrades and security patches.
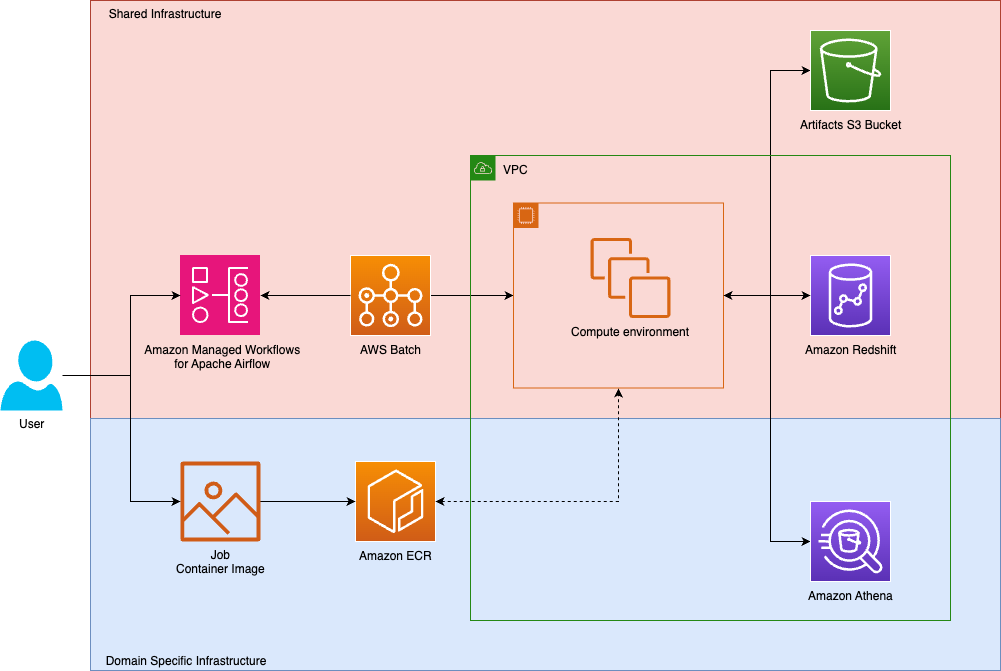
How Tipico democratized data transformations using Amazon Managed Workflows for Apache Airflow and AWS Batch
Tipico is the number one name in sports betting in Germany. Every day, we connect millions of fans to the thrill of sport, combining technology, passion, and trust to deliver fast, secure, and exciting betting, both online and in more than a thousand retail shops across Germany. We also bring this experience to Austria, where we proudly operate a strong sports betting business. In this post, we show how Tipico built a unified data transformation platform using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and AWS Batch.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.