AWS Compute Blog
Implementing architectural patterns with Amazon EventBridge Pipes
This post is written by Dominik Richter (Solutions Architect)
Architectural patterns help you solve recurring challenges in software design. They are blueprints that have been used and tested many times. When you design distributed applications, enterprise integration patterns (EIP) help you integrate distributed components. For example, they describe how to integrate third-party services into your existing applications. But patterns are technology agnostic. They do not provide any guidance on how to implement them.
This post shows you how to use Amazon EventBridge Pipes to implement four common enterprise integration patterns (EIP) on AWS. This helps you to simplify your architectures. Pipes is a feature of Amazon EventBridge to connect your AWS resources. Using Pipes can reduce the complexity of your integrations. It can also reduce the amount of code you have to write and maintain.
Content filter and message filter pattern
To remove unwanted messages and content, combine content filter and message filter. The message filter pattern discards entire messages. The content filter pattern removes unwanted content from an individual message before forwarding it to a downstream system. Use cases for these patterns include reducing storage costs by removing unnecessary data or removing personally identifiable information (PII) for compliance purposes.
In the following example, the goal is to retain only non-PII data from “ORDER”-events. To achieve this, you must remove all events that aren’t “ORDER” events. In addition, you must remove any field in the “ORDER” events that contain PII.
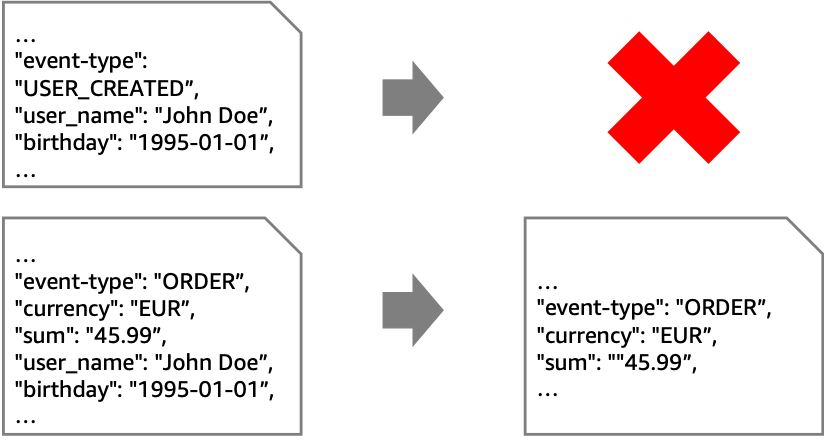
While you can use these patterns with various sources and targets, the following architecture shows this pattern with Amazon Kinesis. EventBridge Pipes filtering discards unwanted events. EventBridge Pipes input transformers remove PII data from events that are forwarded to the second stream with longer retention.

Instead of using Pipes, you could connect the streams using an AWS Lambda function. This requires you to write and maintain code to read from and write to Kinesis. However, Pipes may be more cost effective than using a Lambda function.
Some situations require an enrichment function. For example, if your goal is to mask an attribute without removing it entirely. For example, you could replace the attribute “birthday” with an “age_group”-attribute.

In this case, if you use Pipes for integration, the Lambda function contains only your business logic. On the other hand, if you use Lambda for both integration and business logic, you do not pay for Pipes. At the same time, you add complexity to your Lambda function, which now contains integration code. This can increase its execution time and cost. Therefore, your priorities determine the best option and you should compare both approaches to make a decision.
To implement Pipes using the AWS Cloud Development Kit (AWS CDK), use the following source code. The full source code for all of the patterns that are described in this blog post can be found in the AWS samples GitHub repo.
const filterPipe = new pipes.CfnPipe(this, 'FilterPipe', {
roleArn: pipeRole.roleArn,
source: sourceStream.streamArn,
target: targetStream.streamArn,
sourceParameters: { filterCriteria: { filters: [{ pattern: '{"data" : {"event_type" : ["ORDER"] }}' }] }, kinesisStreamParameters: { startingPosition: 'LATEST' } },
targetParameters: { inputTemplate: '{"event_type": <$.data.event_type>, "currency": <$.data.currency>, "sum": <$.data.sum>}', kinesisStreamParameters: { partitionKey: 'event_type' } },
});
To allow access to source and target, you must assign the correct permissions:
const pipeRole = new iam.Role(this, 'FilterPipeRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com') });
sourceStream.grantRead(pipeRole);
targetStream.grantWrite(pipeRole);
Message translator pattern
In an event-driven architecture, event producers and consumers are independent of each other. Therefore, they may exchange events of different formats. To enable communication, the events must be translated. This is known as the message translator pattern. For example, an event may contain an address, but the consumer expects coordinates.

If a computation is required to translate messages, use the enrichment step. The following architecture diagram shows how to accomplish this enrichment via API destinations. In the example, you can call an existing geocoding service to resolve addresses to coordinates.

There may be cases where the translation is purely syntactical. For example, a field may have a different name or structure.

You can achieve these translations without enrichment by using input transformers.

Here is the source code for the pipe, including the role with the correct permissions:
const pipeRole = new iam.Role(this, 'MessageTranslatorRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com'), inlinePolicies: { invokeApiDestinationPolicy } });
sourceQueue.grantConsumeMessages(pipeRole);
targetStepFunctionsWorkflow.grantStartExecution(pipeRole);
const messageTranslatorPipe = new pipes.CfnPipe(this, 'MessageTranslatorPipe', {
roleArn: pipeRole.roleArn,
source: sourceQueue.queueArn,
target: targetStepFunctionsWorkflow.stateMachineArn,
enrichment: enrichmentDestination.apiDestinationArn,
sourceParameters: { sqsQueueParameters: { batchSize: 1 } },
});
Normalizer pattern
The normalizer pattern is similar to the message translator but there are different source components with different formats for events. The normalizer pattern routes each event type through its specific message translator so that downstream systems process messages with a consistent structure.

The example shows a system where different source systems store the name property differently. To process the messages differently based on their source, use an AWS Step Functions workflow. You can separate by event type and then have individual paths perform the unifying process. This diagram visualizes that you can call a Lambda function if needed. However, in basic cases like the preceding “name” example, you can modify the events using Amazon States Language (ASL).

In the example, you unify the events using Step Functions before putting them on your event bus. As is often the case with architectural choices, there are alternatives. Another approach is to introduce separate queues for each source system, connected by its own pipe containing only its unification actions.
![]()
This is the source code for the normalizer pattern using a Step Functions workflow as enrichment:
const pipeRole = new iam.Role(this, 'NormalizerRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com') });
sourceQueue.grantConsumeMessages(pipeRole);
enrichmentWorkflow.grantStartSyncExecution(pipeRole);
normalizerTargetBus.grantPutEventsTo(pipeRole);
const normalizerPipe = new pipes.CfnPipe(this, 'NormalizerPipe', {
roleArn: pipeRole.roleArn,
source: sourceQueue.queueArn,
target: normalizerTargetBus.eventBusArn,
enrichment: enrichmentWorkflow.stateMachineArn,
sourceParameters: { sqsQueueParameters: { batchSize: 1 } },
});
Claim check pattern
To reduce the size of the events in your event-driven application, you can temporarily remove attributes. This approach is known as the claim check pattern. You split a message into a reference (“claim check”) and the associated payload. Then, you store the payload in external storage and add only the claim check to events. When you process events, you retrieve relevant parts of the payload using the claim check. For example, you can retrieve a user’s name and birthday based on their userID.

The claim check pattern has two parts. First, when an event is received, you split it and store the payload elsewhere. Second, when the event is processed, you retrieve the relevant information. You can implement both aspects with a pipe.
In the first pipe, you use the enrichment to split the event, in the second to retrieve the payload. Below are several enrichment options, such as using an external API via API Destinations, or using Amazon DynamoDB via Lambda. Other enrichment options are Amazon API Gateway and Step Functions.
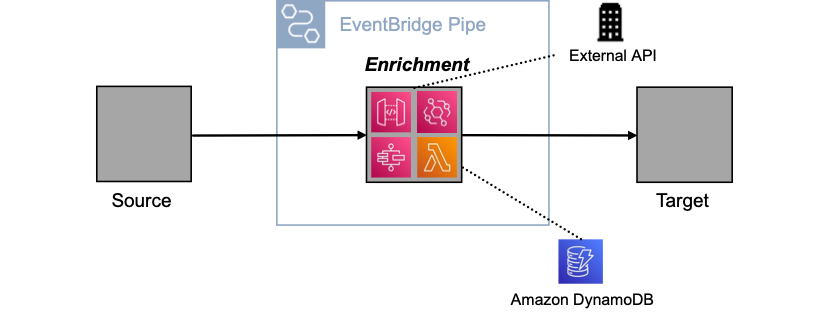
Using a pipe to split and retrieve messages has three advantages. First, you keep events concise as they move through the system. Second, you ensure that the event contains all relevant information when it is processed. Third, you encapsulate the complexity of splitting and retrieving within the pipe.
The following code implements a pipe for the claim check pattern using the CDK:
const pipeRole = new iam.Role(this, 'ClaimCheckRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com') });
claimCheckLambda.grantInvoke(pipeRole);
sourceQueue.grantConsumeMessages(pipeRole);
targetWorkflow.grantStartExecution(pipeRole);
const claimCheckPipe = new pipes.CfnPipe(this, 'ClaimCheckPipe', {
roleArn: pipeRole.roleArn,
source: sourceQueue.queueArn,
target: targetWorkflow.stateMachineArn,
enrichment: claimCheckLambda.functionArn,
sourceParameters: { sqsQueueParameters: { batchSize: 1 } },
targetParameters: { stepFunctionStateMachineParameters: { invocationType: 'FIRE_AND_FORGET' } },
});
Conclusion
This blog post shows how you can implement four enterprise integration patterns with Amazon EventBridge Pipes. In many cases, this reduces the amount of code you have to write and maintain. It can also simplify your architectures and, in some scenarios, reduce costs.
You can find the source code for all the patterns on the AWS samples GitHub repo.
For more serverless learning resources, visit Serverless Land. To find more patterns, go directly to the Serverless Patterns Collection.