Amazon Web Services ブログ
Amazon Managed Workflows for Apache Airflow (MWAA) のご紹介
データ処理パイプラインはそのボリュームを増し、ますます複雑になっていますが、プロセス全体を一連の小さなタスクに分解して簡素化し、これらのタスクの実行をワークフローの一部として調整することができます。その手段として、多くのデベロッパーやデータエンジニアが Apache Airflow を使用しています。Apache Airflow は、コミュニティによって作成され、プログラムによってワークフローを作成、スケジュール、モニタリングするプラットフォームです。Airflow を使用すると、ワークフローをスクリプトとして管理したり、ユーザーインターフェイス (UI) を介してワークフローをモニタリングしたり、強力なプラグインのセットを使用して機能を拡張したりできます。ただし、Airflow を手動でインストール、保守、スケールし、それと同時にユーザーのセキュリティ、認証、認可の処理を行うには多くの時間がかかり、実際のビジネス上の問題解決に集中できなくなってしまいます。
こうした問題点を解消するため、AWS で Apache Airflow のオープンソースバージョンを簡単に実行し、抽出、変換、読み込み (ETL) ジョブとデータパイプラインを実行するワークフローを構築可能な、フルマネージドサービスである Amazon Managed Workflows for Apache Airflow (MWAA) の提供を開始しましたことをお知らせします。
Airflow ワークフローでは、Amazon Athena クエリを使用して Amazon Simple Storage Service (S3) などのソースから入力を取得し、Amazon EMR クラスターで変換を実行し、結果として生成されたデータを使用して Amazon SageMaker で機械学習モデルをトレーニングできます。Airflow ワークフローは、Python プログラミング言語を使用して、有向非巡回グラフ (DAG) として作成されます。
Airflow の主な利点は、プラグインによりオープンな拡張が可能であることです。これにより、AWS とやり取りするタスクや、AWS Batch、Amazon CloudWatch、Amazon DynamoDB、AWS DataSync、Amazon ECS、AWS Fargate、Amazon Elastic Kubernetes Service (EKS)、Amazon Kinesis Firehose、AWS Glue、AWS Lambda、Amazon Redshift、Amazon Simple Queue Service (SQS)、Amazon Simple Notification Service (SNS) などのワークフローに必要なオンプレミスリソースを作成できます。
可観測性を高めるために、Airflow メトリクスを CloudWatch メトリクスとしてパブリッシュし、ログを CloudWatch Logs に送信することができます。Amazon MWAA では、デフォルトでマイナーバージョンのアップグレードとパッチが自動で提供されます。オプションとしてこのアップグレードを実行するメンテナンスウィンドウを指定することもできます。
Amazon MWAA の利用に必要なステップは、次の 3 つです。
- 環境を作成する – 各環境には、スケジューラ、ワーカー、ウェブサーバーを含む Airflow クラスターが含まれます。
- DAG とプラグインを S3 にアップロードする – Amazon MWAA はコードを Airflow に自動的にロードします。
- Airflow で DAG を実行する – Airflow UI またはコマンドラインインターフェイス (CLI) から DAG を実行し、CloudWatch で環境をモニタリングします。
それでは、実際にどのように機能するか見てみましょう。
Amazon MWAA を使用して Airflow 環境を作成する方法
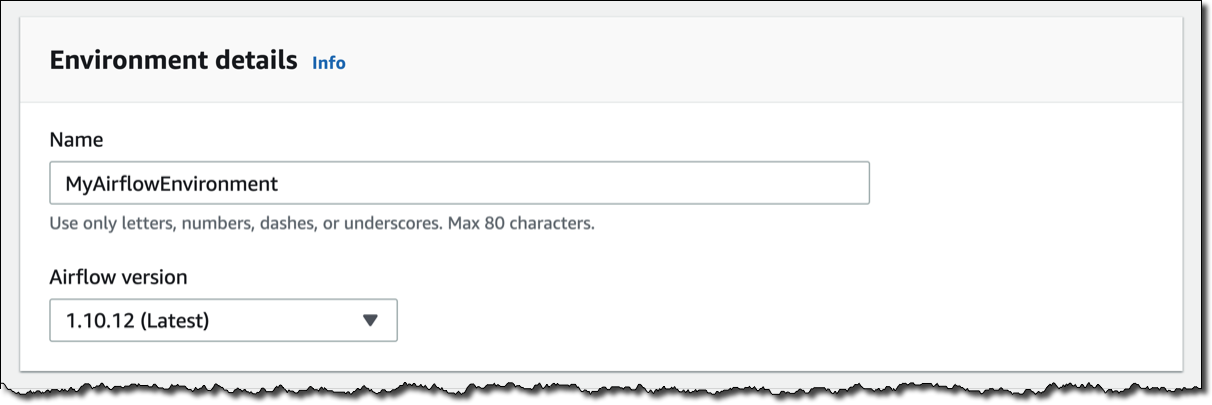
Amazon MWAA コンソールで [Create environment (環境の作成)] をクリックします。環境に名前を付けて、使用する Airflow バージョンを選択します。
次に、S3 バケットとフォルダを選択して DAG コードをロードします。バケット名は、先頭に airflow- が付いている必要があります。
オプションで、プラグインファイルと要件ファイルを指定できます。
- プラグインファイルは、DAG で使用するプラグインを含んだ ZIP ファイルです。
- 要件ファイルには、DAG を実行するための Python の依存関係が記載されています。
プラグインと要件に使用する S3 オブジェクトのバージョンを選択できます。使用するプラグインや要件が環境内で回復不可能なエラーを起こした場合、Amazon MWAA は以前の正常に動作するバージョンに自動でロールバックします。

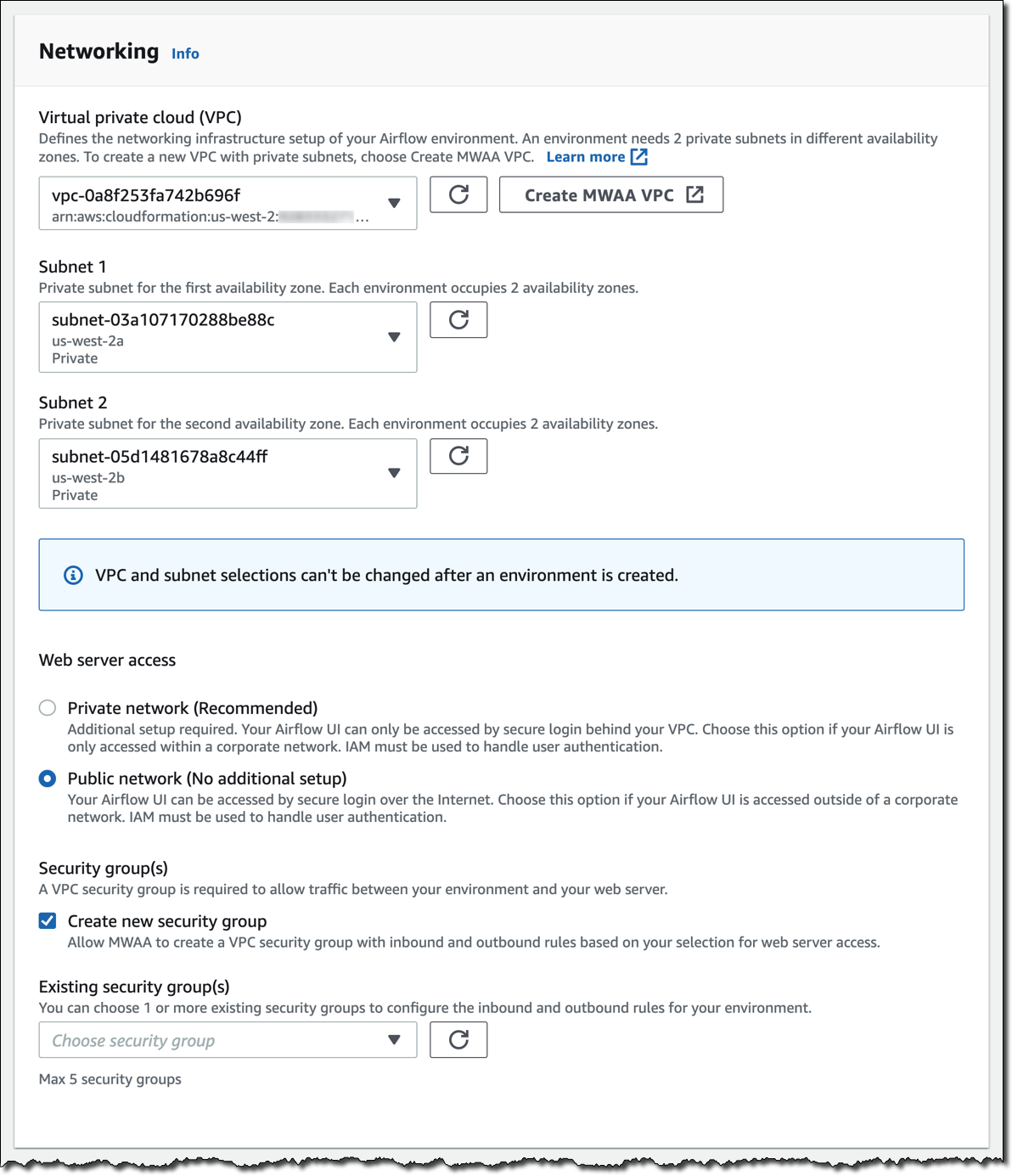
[Next (次へ)] をクリックして、まずはネットワークから詳細設定を行います。各環境は、2 つのアベイラビリティーゾーンのプライベートサブネットを使用して Amazon Virtual Private Cloud で実行されます。ウェブサーバーによる Airflow UI へのアクセスは、AWS Identity and Access Management (IAM) を使用した安全なログインによって常に保護されます。ただし、パブリックネットワーク上でウェブサーバーにアクセスできるようにして、インターネット経由で、または VPC 内のプライベートネットワークでログインすることもできます。ここではわかりやすくするために、[Public network (パブリックネットワーク)] を選択します。Amazon MWAA に、適切なインバウンドルールとアウトバウンドルールを使用して新しいセキュリティグループを作成させます。オプションで、1 つ以上の既存のセキュリティグループを追加して、環境のインバウンドトラフィックとアウトバウンドトラフィックの制御を調整することもできます。
ここからは、環境クラスを設定していきます。各環境には、スケジューラ、ウェブサーバー、ワーカーが含まれます。ワーカーは、ワークロードに応じて自動的にスケールアップおよびスケールダウンを行います。DAG の数に基づいてどのクラスを使用すればよいか提案されますが、クラスは、環境への負荷をモニタリングしていつでも変更することができます。

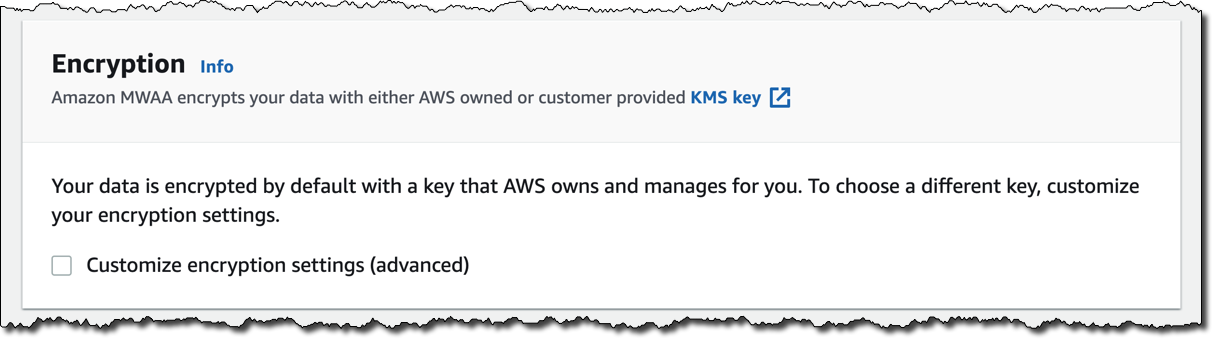
暗号化は保管時のデータに対して常に有効になっています。AWS Key Management Service (KMS) が管理するカスタマイズされたキーを選択することもできますが、ここでは AWS がユーザーに代わって所有および管理するデフォルトのキーをそのまま使います。
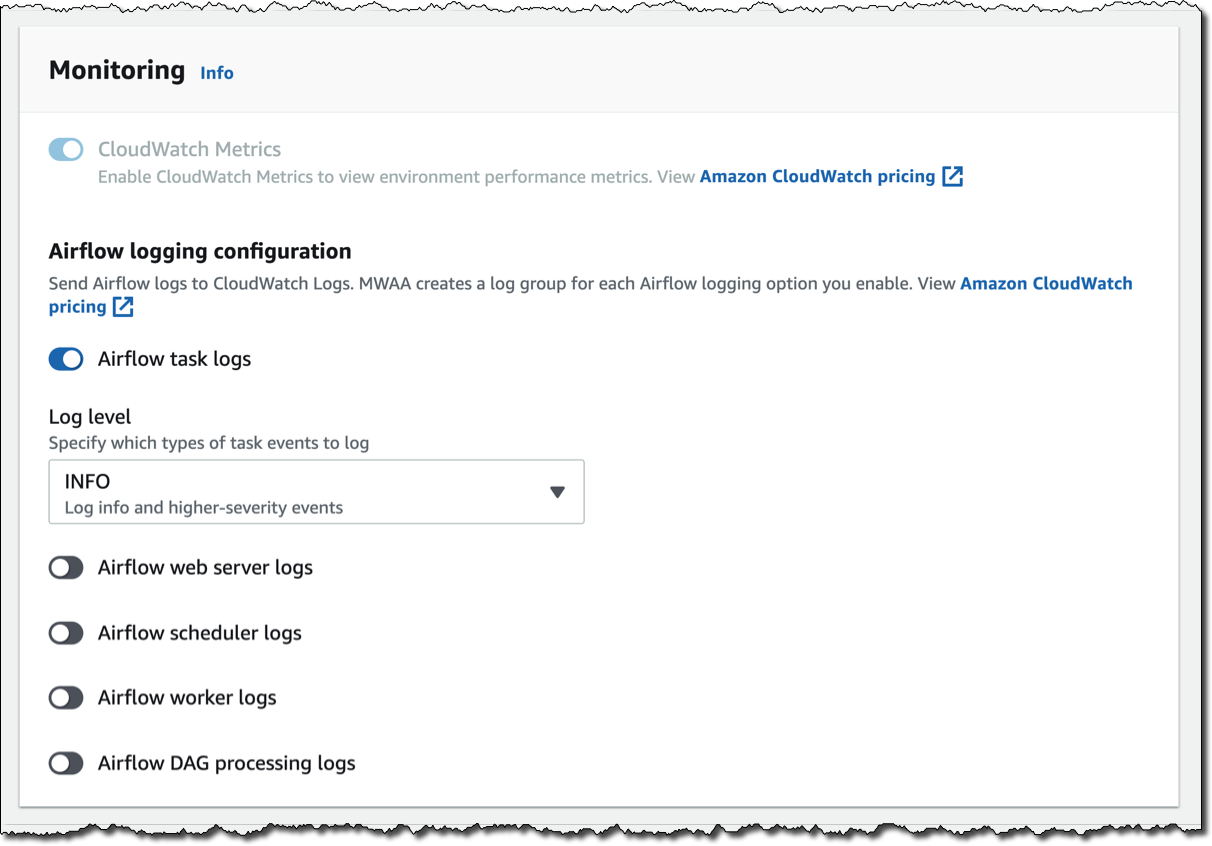
モニタリングのために、環境のパフォーマンスを CloudWatch メトリクスにパブリッシュします。この設定はデフォルトで有効になっていますが、起動後に CloudWatch メトリクスを無効にすることができます。ログについては、ログレベルと、CloudWatch Logs にログを送信する Airflow コンポーネントを指定できます。ここではデフォルトのままにして、タスクログだけを送信し、[INFO] ログレベルを使用します。
default_task_retries や worker_concurrency などの Airflow 設定オプションのデフォルト設定を変更できます。今回、これらの値は変更しません。

最後に、最も重要なアクセス許可の設定を行います。このアクセス許可は環境において、DAG へのアクセス、ログの書き込み、他の AWS リソースにアクセスする DAG の実行に使用されます。[Create a new role (新しいロールの作成)] を選択し、[Create environment (環境の作成)] をクリックします。数分後、新しい Airflow 環境を使用する準備が整います。

Airflow UI を使用する
Amazon MWAA コンソールで、作成したばかりの新しい環境を探し、[Open Airflow UI (Airflow UI を開く)] をクリックします。新しいブラウザウィンドウが開き、AWS IAM を介した安全なログインで認証が行われます。
movie_list_dag.py ファイルで S3 に格納していた DAG を探します。DAG は MovieLens データセットをダウンロードし、Amazon Athena を使用して S3 のファイルを処理し、結果を Redshift クラスターにロードします。欠落がある場合はテーブルを作成します。
DAG のフルソースコードは次のとおりです。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators import HttpSensor, S3KeySensor
from airflow.contrib.operators.aws_athena_operator import AWSAthenaOperator
from airflow.utils.dates import days_ago
from datetime import datetime, timedelta
from io import StringIO
from io import BytesIO
from time import sleep
import csv
import requests
import json
import boto3
import zipfile
import io
s3_bucket_name = 'my-bucket'
s3_key='files/'
redshift_cluster='my-redshift-cluster'
redshift_db='dev'
redshift_dbuser='awsuser'
redshift_table_name='movie_demo'
test_http='https://grouplens.org/datasets/movielens/latest/'
download_http='http://files.grouplens.org/datasets/movielens/ml-latest-small.zip'
athena_db='demo_athena_db'
athena_results='athena-results/'
create_athena_movie_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS Demo_Athena_DB.ML_Latest_Small_Movies (
`movieId` int,
`title` string,
`genres` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://my-bucket/files/ml-latest-small/movies.csv/ml-latest-small/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
"""
create_athena_ratings_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS Demo_Athena_DB.ML_Latest_Small_Ratings (
`userId` int,
`movieId` int,
`rating` int,
`timestamp` bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://my-bucket/files/ml-latest-small/ratings.csv/ml-latest-small/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
"""
create_athena_tags_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS Demo_Athena_DB.ML_Latest_Small_Tags (
`userId` int,
`movieId` int,
`tag` int,
`timestamp` bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://my-bucket/files/ml-latest-small/tags.csv/ml-latest-small/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
"""
join_tables_athena_query="""
SELECT REPLACE ( m.title , '"' , '' ) as title, r.rating
FROM demo_athena_db.ML_Latest_Small_Movies m
INNER JOIN (SELECT rating, movieId FROM demo_athena_db.ML_Latest_Small_Ratings WHERE rating > 4) r on m.movieId = r.movieId
"""
def download_zip():
s3c = boto3.client('s3')
indata = requests.get(download_http)
n=0
with zipfile.ZipFile(io.BytesIO(indata.content)) as z:
zList=z.namelist()
print(zList)
for i in zList:
print(i)
zfiledata = BytesIO(z.read(i))
n += 1
s3c.put_object(Bucket=s3_bucket_name, Key=s3_key+i+'/'+i, Body=zfiledata)
def clean_up_csv_fn(**kwargs):
ti = kwargs['task_instance']
queryId = ti.xcom_pull(key='return_value', task_ids='join_athena_tables' )
print(queryId)
athenaKey=athena_results+"join_athena_tables/"+queryId+".csv"
print(athenaKey)
cleanKey=athena_results+"join_athena_tables/"+queryId+"_clean.csv"
s3c = boto3.client('s3')
obj = s3c.get_object(Bucket=s3_bucket_name, Key=athenaKey)
infileStr=obj['Body'].read().decode('utf-8')
outfileStr=infileStr.replace('"e"', '')
outfile = StringIO(outfileStr)
s3c.put_object(Bucket=s3_bucket_name, Key=cleanKey, Body=outfile.getvalue())
def s3_to_redshift(**kwargs):
ti = kwargs['task_instance']
queryId = ti.xcom_pull(key='return_value', task_ids='join_athena_tables' )
print(queryId)
athenaKey='s3://'+s3_bucket_name+"/"+athena_results+"join_athena_tables/"+queryId+"_clean.csv"
print(athenaKey)
sqlQuery="copy "+redshift_table_name+" from '"+athenaKey+"' iam_role 'arn:aws:iam::163919838948:role/myRedshiftRole' CSV IGNOREHEADER 1;"
print(sqlQuery)
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
DbUser=redshift_dbuser,
Sql=sqlQuery
)
print(resp)
return "OK"
def create_redshift_table():
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
DbUser=redshift_dbuser,
Sql="CREATE TABLE IF NOT EXISTS "+redshift_table_name+" (title character varying, rating int);"
)
print(resp)
return "OK"
DEFAULT_ARGS = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False
}
with DAG(
dag_id='movie-list-dag',
default_args=DEFAULT_ARGS,
dagrun_timeout=timedelta(hours=2),
start_date=days_ago(2),
schedule_interval='*/10 * * * *',
tags=['athena','redshift'],
) as dag:
check_s3_for_key = S3KeySensor(
task_id='check_s3_for_key',
bucket_key=s3_key,
wildcard_match=True,
bucket_name=s3_bucket_name,
s3_conn_id='aws_default',
timeout=20,
poke_interval=5,
dag=dag
)
files_to_s3 = PythonOperator(
task_id="files_to_s3",
python_callable=download_zip
)
create_athena_movie_table = AWSAthenaOperator(task_id="create_athena_movie_table",query=create_athena_movie_table_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'create_athena_movie_table')
create_athena_ratings_table = AWSAthenaOperator(task_id="create_athena_ratings_table",query=create_athena_ratings_table_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'create_athena_ratings_table')
create_athena_tags_table = AWSAthenaOperator(task_id="create_athena_tags_table",query=create_athena_tags_table_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'create_athena_tags_table')
join_athena_tables = AWSAthenaOperator(task_id="join_athena_tables",query=join_tables_athena_query, database=athena_db, output_location='s3://'+s3_bucket_name+"/"+athena_results+'join_athena_tables')
create_redshift_table_if_not_exists = PythonOperator(
task_id="create_redshift_table_if_not_exists",
python_callable=create_redshift_table
)
clean_up_csv = PythonOperator(
task_id="clean_up_csv",
python_callable=clean_up_csv_fn,
provide_context=True
)
transfer_to_redshift = PythonOperator(
task_id="transfer_to_redshift",
python_callable=s3_to_redshift,
provide_context=True
)
check_s3_for_key >> files_to_s3 >> create_athena_movie_table >> join_athena_tables >> clean_up_csv >> transfer_to_redshift
files_to_s3 >> create_athena_ratings_table >> join_athena_tables
files_to_s3 >> create_athena_tags_table >> join_athena_tables
files_to_s3 >> create_redshift_table_if_not_exists >> transfer_to_redshiftこのコードでは、一般的な Python コードの場合には PythonOperator、Amazon Athena との統合を使用する場合には AWSAthenaOperator というふうに、各種の演算子を使用してさまざまなタスクが作成されます。これらのタスクがワークフローでどのように接続されているかは、最後の数行で確認できます。以下に (インデントなしで) 抜粋します。
check_s3_for_key >> files_to_s3 >> create_athena_movie_table >> join_athena_tables >> clean_up_csv >> transfer_to_redshift
files_to_s3 >> create_athena_ratings_table >> join_athena_tables
files_to_s3 >> create_athena_tags_table >> join_athena_tables
files_to_s3 >> create_redshift_table_if_not_exists >> transfer_to_redshiftAirflow コードは、Python の右シフト >> 演算子をオーバーロードして依存関係を作成しています。つまり、左側のタスクを最初に実行し、出力を右側のタスクに渡します。コードを見ると、このことがよくわかります。上記の 4 行それぞれが依存関係を追加しており、すべてが一緒に評価されるので正しい順序でタスクを実行できます。
Airflow コンソールでは DAG のグラフビューが表示されます。これを見ればタスクがどのように実行されるかが明確にわかります。

今すぐ利用可能
Amazon Managed Workflows for Apache Airflow (MWAA) は、米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ)、アジアパシフィック (シンガポール)、アジアパシフィック (東京)、アジアパシフィック (シドニー)、欧州 (アイルランド)、欧州 (フランクフルト)、欧州 (ストックホルム) の各リージョンで現在利用可能です。新しい Amazon MWAA 環境は、コンソール、AWS コマンドラインインターフェイス (CLI)、AWS SDK から起動することができます。その後、Airflow の統合エコシステムを使用して Python でワークフローを開発できます。
Amazon MWAA では、使用する環境クラスとワーカーに基づいて料金が発生します。詳細については、料金ページをご参照ください。
上位互換は、Amazon MWAA の中核となる理念です。Airflow プラットフォームに対するコード変更は、オープンソースにリリースされます。
Amazon MWAA を使用すると、Airflow プラットフォームのインフラストラクチャの管理やスケーリングに費やす時間が減り、エンジニアリングやデータサイエンスのタスクのワークフローを構築するための時間が増えます。
Amazon MWAA の詳細をご覧になったら、今日から利用を開始しましょう。
– Danilo