Category: Amazon Redshift
Amazon Redshift Spectrum – S3 데이터에 대한 엑사바이트(Exabyte)급 질의 수행 서비스
이제 몇 번의 클릭만으로 클라우드 기반 컴퓨팅 및 스토리지 리소스를 시작할 수 있게 되었기 때문에, 이러한 리소스를 사용하여 초기 데이터에서 실행 가능한 결과로 최대한 신속하고 효율적으로 이동해야합니다.
Amazon Redshift를 사용하면 다양한 내부 및 외부 소스의 데이터를 통합하는 페타 바이트 규모의 데이터웨어 하우스를 구축 할 수 있습니다. Redshift는 대형 테이블에서 복잡한 조인(Join, 여러 조인이 수반되는 경우가 많음)을 위해 최적화되어 대규모의 소매, 재고 및 재무 데이터를 처리 할 수 있습니다. 또한, Redshift 파트너가 제공하는 수많은 엔터프라이즈 비즈니스 인텔리전스 도구를 사용할 수 있습니다.
데이터웨어 하우스 운영의 가장 어려운 측면 중 하나는 지속적으로 변화하는 데이터 및 빠른 속도로 들어오는 데이터를 로드하는 것입니다. 뛰어난 쿼리 성능을 제공하기 위해 데이터웨어 하우스에 데이터를 로드하는 데에는 압축, 정규화 및 최적화 단계를 포함합니다. 이러한 단계를 자동화하고 확장 할 수는 있지만, 로드 프로세스는 여전히 오버 헤드와 복잡성을 야기하며 주요 실행 결과에 영향을 주게 됩니다.
데이터 형식은 또 다른 흥미로운 도전 과제입니다. 일부 애플리케이션은 데이터웨어 하우스 외부에서 원래 형식으로 데이터를 처리하거나, 데이터웨어 하우스에 쿼리를 실행합니다. 이 모델은 데이터를 두 번 저장해야하기 때문에 저장 비효율을 초래하며, 데이터 로드 프로세스에서 발생하는 지연으로 인해 한 가지 형식의 처리 결과가 다른 형식의 결과와 정렬되지 않을 수도 있습니다.
Amazon Redshift Spectrum 기능 출시
Amazon Redshift의 기능과 유연성을 활용하면서 데이터를 있는 그대로 처리 할 수 있도록 Amazon Redshift Spectrum을 정식 공개합니다. 스펙트럼을 사용하여 Amazon Simple Storage Service (S3)에 저장된 데이터에 대한 복잡한 쿼리를 로드하거나 다른 데이터를 준비 할 필요 없이 바로 실행할 수 있습니다.
평소와 같이 데이터 소스를 생성하고 Redshift 클러스터에 쿼리를 실행하면 됩니다. 그 이면에서, Spectrum은 쿼리 단위로 수천 개의 인스턴스로 확장되므로 데이터 세트가 엑사바이트(exabyte) 이상으로 커지더라도 빠르고 일관된 성능을 보장 할 수 있습니다! S3에 저장된 데이터를 쿼리 할 수 있다는 것은 Redshift 쿼리 모델 기능, 리포트 및 비즈니스 인텔리전스 도구를 자유롭게 사용하여 컴퓨팅 및 저장소를 독립적으로 확장 할 수 있다는 것을 의미합니다. 검색어는 Redshift 테이블과 S3에 저장된 모든 데이터의 조합을 참조할 수 있습니다.
쿼리를 실행하면 Redshift가 이를 구분하고 열(Column) 기반 형식과 날짜 또는 다른 키로 분할 된 데이터를 모두 활용하여, S3 읽기 데이터 양을 최소화하는 쿼리 계획을 생성합니다. 그런 다음 Redshift는 공유 풀(Pool)에서 Spectrum을 요청하고, S3 데이터를 가져와 필터링 및 집계하도록 지시합니다. 최종 처리는 Redshift 클러스터 내에서 수행되고 결과는 사용자에게 반환됩니다.
Spectrum은 S3에 저장된 데이터에서 작동하기 때문에Amazon EMR 및 Amazon Athena와 같은 다른 AWS 서비스를 사용하여 데이터를 처리 할 수 있습니다. Redshift 로컬 스토리지에 자주 질의되는 데이터가 저장되고, 나머지는 S3 차원 테이블(dimension tables)에서 팩트 테이블(fact tables)의 최신 데이터와 함께 Redshift에 존재하고, S3에는 이전 데이터가 있는 하이브리드 모델을 구현할 수도 있습니다. 높은 수준의 동시성을 구현하기 위해 동일 저장 데이터에서 여러 개의 Redshift 클러스터를 지정할 수 있습니다.
Spectrum은 CSV/TSV, Parquet, SequenceFile, RCFile을 비롯한 개방형 공통 데이터 유형을 지원합니다. 파일은 GZip 또는 Snappy를 사용하여 압축 할 수 있으며 다른 데이터 유형 및 압축 방법을 사용할 수 있습니다.
Spectrum 실행해 보기
Spectrum을 직접 경험해보기 위해 샘플 데이터 세트를 로드하고 쿼리를 실행합니다. 먼저 외부 스키마와 데이터베이스를 작성하여 시작했습니다.
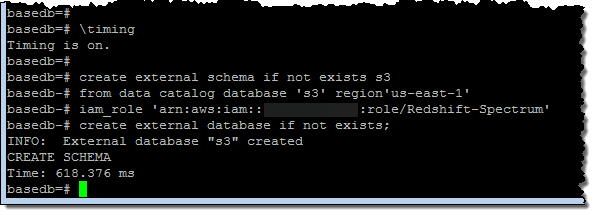
그런 다음 데이터베이스 내에 외부 테이블을 만들었습니다.
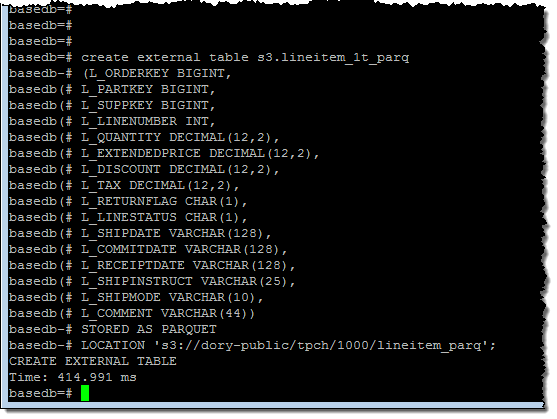
간단한 쿼리를 실행하여 데이터 세트의 크기(61 억 행)에 대한 감을 얻었습니다.
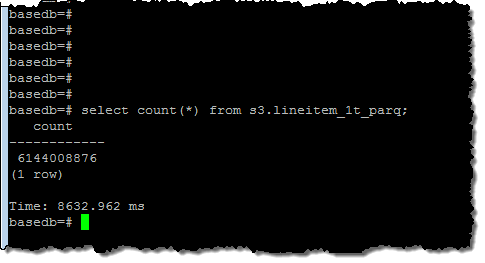
그런 다음 모든 행을 처리 한 쿼리를 실행했습니다.
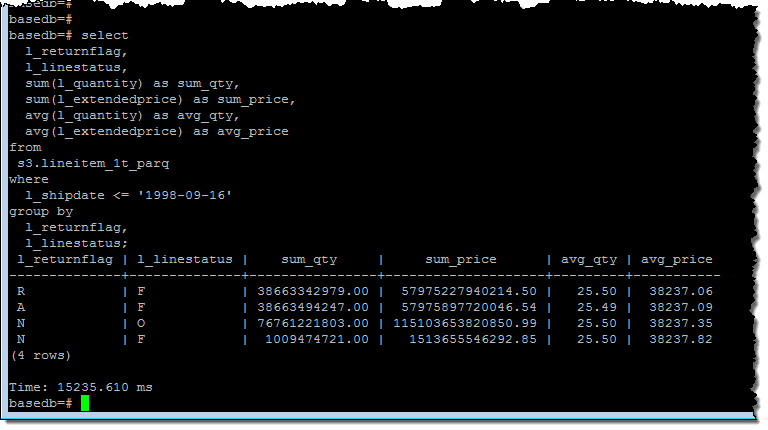
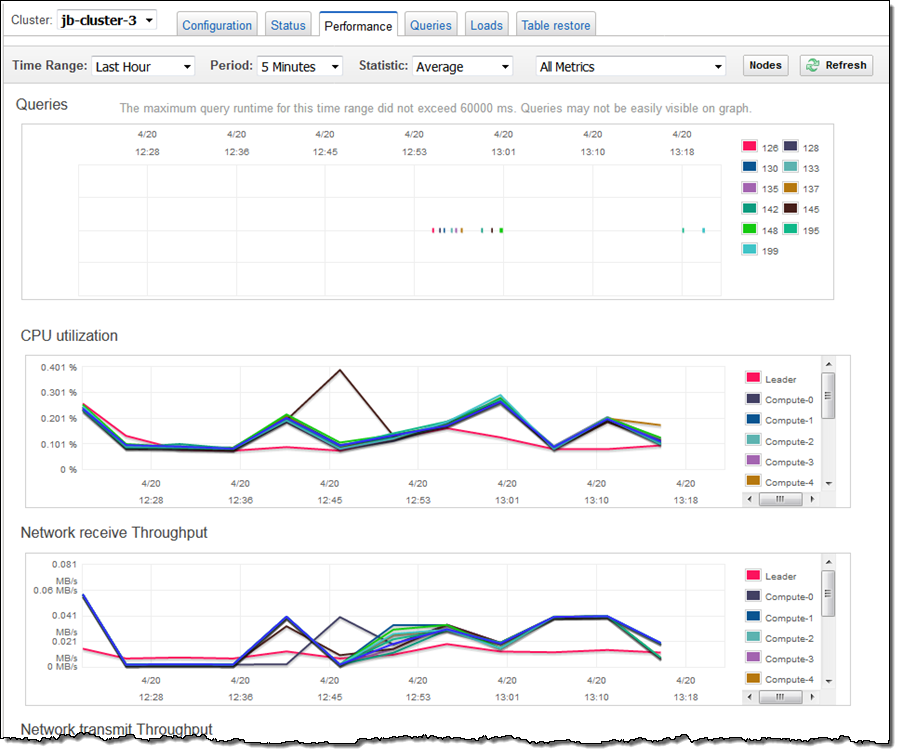
보시다시피, Spectrum은 약 15 초 만에 60 억 행을 처리할 수 있습니다. 클러스터 성능 메트릭을 확인한 결과 많은 쿼리를 동시에 실행하기에 충분한 CPU 성능을 갖춘 것처럼 보입니다.
정식 출시
Amazon Redshift Spectrum 는 오늘부터 사용 가능합니다.
스펙트럼 가격은 쿼리 처리 중에 S3에서 가져온 데이터의 양을 기반으로 하며 테라 바이트 당 5 달러의 요금으로 청구됩니다 (데이터 압축 및 열 기반 형식으로 저장하여 비용을 절약 할 수 있음). Redshift 클러스터를 실행하고 S3에 데이터를 저장하는 데 일반적인 요금을 지불하지만 쿼리를 실행하지 않을 때는 스펙트럼 요금이 없습니다.
— Jeff;
PS – 어떤 분들은 Spectrum 과 Athena에 대한 차이에 대해 궁금하실 것입니다. 아래는 Redshift FAQ 에서 이들 서비스간의 차이에 대한 간단한 답변입니다.
Amazon Athena는 S3 데이터에 대한 임의(ad-hoc) 쿼리를 실행할 수 있는 가장 간단한 방법입니다. Athena는 서버가 없으므로 설치 또는 관리 할 인프라가 없으므로 즉시 데이터 분석을 시작할 수 있습니다. 자주 접근하는 데이터를 일관성 있고, 구조화 된 형식으로 저장해야 하는 경우 Amazon Redshift와 같은 데이터웨어 하우스를 사용해야 합니다. Amazon Redshift에 저장한 데이터는 Redshift Spectrum을 사용하여 Amazon Redshift 쿼리를 S3 전체 데이터로 확장 할 수 있습니다. 이렇게 하면 원하는 형식으로 원하는 위치에 자유롭게 데이터를 저장하고 필요할 때 처리 할 수 있습니다.
이 글은 Amazon Redshift Spectrum – Exabyte-Scale In-Place Queries of S3 Data의 한국어 번역입니다.
Amazon Redshift 쿼리 캐싱을 위해 pgpool 및 Amazon ElastiCache 사용
최근 국내의 많은 고객 분들이 Amazon Redshift 도입을 고려하고 계시거나, 또는 이미 도입하여 사용하고 계십니다. OLTP 뿐만 아니라 데이터 웨어하우스 시스템에서도 쿼리 캐싱은 전체적인 사용자 체감 속도를 개선할 수 있는 아주 좋은 방법입니다. 쿼리 캐싱을 위한 다양한 방법이 있겠지만, pgpool 및 Amazon ElastiCache 사용에 대한 좋은 블로그 글이 있어 소개하도록 하겠습니다.
원문은 Using pgpool and Amazon ElastiCache for Query Caching with Amazon Redshift (https://aws.amazon.com/blogs/big-data/using-pgpool-and-amazon-elasticache-for-query-caching-with-amazon-redshift/)입니다.
이 글에서는 실제 고객 시나리오를 사용하여 pgpool 및 Amazon ElastiCache를 사용하여 Amazon Redshift 앞에 캐시 레이어를 만드는 방법을 보여줍니다.
거의 모든 애플리케이션은 아무리 간단한 것이든 어떤 종류의 데이터베이스를 사용합니다. SQL 쿼리를 자주 사용하게 되면 때때로 중복 실행이 발생할 수 있습니다. 이러한 중복성은 다른 작업에 할당 될 수 있는 자원을 낭비합니다.
예를 들어 Amazon Redshift에 위치한 데이터를 사용하는 BI 도구 및 애플리케이션은 일반적인 쿼리를 실행할 가능성이 높습니다. 최종 사용자 환경을 개선하고 데이터베이스의 경합을 줄이기 위해 그중 일부를 캐시 할 수 있습니다. 사실 좋은 데이터 모델링 및 분류 정책을 사용하여 클러스터 크기를 줄임으로써 비용을 절약 할 수 있습니다.
캐싱이란 무엇입니까?
컴퓨팅에서 캐시는 데이터를 저장하는 하드웨어 또는 소프트웨어 구성 요소이므로 향후 해당 데이터에 대한 요청을 더 빨리 처리 할 수 있습니다. 캐시에 저장된 데이터는 이전 계산의 결과이거나 다른 곳에 저장된 데이터의 복제 일 수 있습니다. 요청 된 데이터가 캐시에서 발견되면 캐시 히트가 발생합니다. 그렇지 않은 경우 캐시 미스가 발생합니다. 캐시 히트는 캐시에서 데이터를 읽어 제공하기 때문에 결과를 다시 계산하거나 느린 데이터 저장소에서 읽는 것보다 빠릅니다. 캐시가 더 많은 요청을 처리 할수록 시스템은 더 빠르게 운영될 수 있습니다.
고객 사례 : 실험실 분석
임상 분석 실험실에서, 6-10 명의 과학자 (유전 학자, 의사 및 생물 학자)로 이루어진 특정 팀이 특정 유전자 변형을 찾는 약 200 만 줄의 유전자 코드를 검색합니다. 변형된 유전자 옆의 유전자는 질병이나 장애를 확인할 수 있기 때문에 매우 흥미롭습니다.
과학자들은 동시에 하나의 DNA 샘플을 분석 한 다음, 회의를 통해 서로의 의견을 공유하여 결론을 내립니다.
Node.js 웹 애플리케이션에는 Amazon Redshift 에 대해 쿼리를 실행하는 로직이 포함되어 있습니다. Amazon Redshift에 연결된 웹 애플리케이션을 사용함에 있어서 과학자 팀은 약 10 초의 대기 시간을 경험했습니다. pgpool을 사용하도록 아키텍처를 수정한 후, 이 과학자들은 동일한 쿼리를 1 초 미만 (즉, 10 배 더 빨리)에 실행할 수 있었습니다.

pgpool 소개
Pgpool은 데이터베이스 클라이언트와 데이터베이스 서버 사이에 위치하는 소프트웨어입니다. 역방향 프록시(reverse proxy) 역할을 하며 클라이언트로부터 연결을 수신하여 데이터베이스 서버로 전달합니다. 원래 PostgreSQL 용으로 작성된 pgpool은 캐싱 외에도 연결 풀링(pooling), 복제(replication), 로드 밸런싱 및 초과 연결 큐와 같은 다른 흥미로운 기능을 가지고 있습니다. 이러한 기능을 자세히 찾아보지 않았지만 PostgreSQL과 Amazon Redshift 간의 호환성으로 인해 Amazon Redshift와 함께 사용할 수 있다고 생각됩니다.
Pgpool은 Amazon EC2 인스턴스 또는 사내 구축 환경에서 실행할 수 있습니다. 예를 들어, 개발 및 테스트를 위해 한개의 EC2 인스턴스가 있고 프로덕션 환경에 Elastic Load Balancing 및 Auto Scaling을 사용하는 EC2 인스턴스 그룹이 있을 수 있습니다.
임상 분석 실험실이라는 우리의 사용 예제에서는 psql (command line) 및 Node.js 애플리케이션을 사용하여 Amazon Redshift에 대한 쿼리를 실행했으며 예상대로 동작했습니다. 그러나 아키텍처를 변경하기 전에 PostgreSQL 클라이언트에서 pgpool을 테스트 할 것을 강력하게 권장합니다.
pgpool 캐싱 기능 살펴보기
pgpool 캐싱 기능은 기본적으로 비활성화 되어 있습니다. 다음 두 가지 방법으로 구성 할 수 있습니다.
- On-memory (shmem)
- 캐시를 활성화 하고, 설정을 전혀 변경하지 않았을 때 기본적으로 제공하는 방법입니다. Memcached 보다 약간 빠르며 구성 및 유지 관리가 더 쉽습니다. 반면에 고 가용성 시나리오에서는, 서버 당 쿼리를 캐싱하고 각 서버에 대해 적어도 한 번 캐싱할 쿼리를 처리하기 때문에 메모리와 일부 데이터베이스 처리를 낭비하는 경향이 있습니다. 예를 들어 4대로 구성된 pgpool 클러스터에서 20GB 캐시가 필요할 경우, 4대의xlarge 인스턴스를 준비하고 각 서버당 20GB메모리를 캐시를 위해 사용해야 합니다. 데이터베이스에 의해 처리되는 각 쿼리는 각 서버에 캐싱이 되어야 하기 때문에 최소한 4 번 캐싱 되어야 합니다.
- Memcached (memcached)
- 이 방법에서 캐시는 서버의 외부에서 유지 관리됩니다. 장점은 캐시 저장 영역 (Memcached)이 캐시 처리 영역(pgpool)에서 분리된다는 것입니다. 이는 쿼리가 Memcached에서만 처리되고 외부에서 캐싱되기 때문에 서버 메모리 및 데이터베이스 처리 시간을 낭비하지 않는다는 것을 의미합니다.
- Memcached를 구성할 수 있는 방법은 많지만, Amazon ElastiCache에서 제공하는Memcached를 함께 사용하는 것이 좋습니다. Amazon ElastiCache는 실패한 노드를 자동으로 감지하고 교체하는 기능을 제공하므로 직접 인프라를 관리하는 오버헤드가 줄어듭니다. 웹 사이트 및 애플리케이션 실행 시간을 지연시키는 데이터베이스의 과부화 위험을 완화시켜 안정적인 서비스를 가능하게 합니다.
pgpool을 이용한 쿼리 캐싱
다음의 흐름도는 쿼리 캐싱이 pgpool과 함께 작동하는 방법을 보여줍니다.
![]()
다음 다이어그램은 개발/테스트 환경을 위해 pgpool을 설치하고 구성하는 데 필요한 최소 아키텍처를 보여줍니다.

다음 다이어그램은 프로덕션 환경에 권장되는 최소 아키텍처를 보여줍니다.

선결 요건
이 단계는 AWS CLI (Command Line Interface)를 사용할 것입니다. Mac, Linux 또는 Microsoft Windows 시스템을 이용하여 구성해 보시려면AWS CLI가 설치되어 있어야합니다. 설치 방법은 AWS Command Line Interface 설치를 참조하십시오.
pgpool 설치 및 구성 단계
1. 변수 설정 :
IMAGEID=ami-c481fad3
KEYNAME=<set your key name here>
IMAGEID 변수는 미국 동부 (버지니아) 지역의 Amazon Linux AMI를 사용하도록 설정합니다.
KEYNAME 변수를 여러분이 사용할 EC2 Key pair 이름으로 설정하십시오. 이 Key pair는 미국 동부 (버지니아) 지역에서 생성 된 것이어야 합니다.
미국 동부 (버지니아) 이외의 지역을 사용하는 경우 IMAGEID 및 KEYNAME을 적절하게 수정하시기 바랍니다.
2. EC2 인스턴스 만들기 :
aws ec2 create-security-group --group-name PgPoolSecurityGroup --description "Security group to allow access to pgpool"
MYIP=$(curl eth0.me -s | awk '{print $1"/32"}')
aws ec2 authorize-security-group-ingress --group-name PgPoolSecurityGroup --protocol tcp --port 5432 --cidr $MYIP
aws ec2 authorize-security-group-ingress --group-name PgPoolSecurityGroup --protocol tcp --port 22 --cidr $MYIP
INSTANCEID=$(aws ec2 run-instances \
--image-id $IMAGEID \
--security-groups PgPoolSecurityGroup \
--key-name $KEYNAME \
--instance-type m3.medium \
--query 'Instances[0].InstanceId' \
| sed "s/\"//g")
aws ec2 wait instance-status-ok --instance-ids $INSTANCEID
INSTANCEIP=$(aws ec2 describe-instances \
--filters "Name=instance-id,Values=$INSTANCEID" \
--query "Reservations[0].Instances[0].PublicIpAddress" \
| sed "s/\"//g")
3. Amazon ElastiCache 클러스터 생성 :
aws ec2 create-security-group --group-name MemcachedSecurityGroup --description "Security group to allow access to Memcached" aws ec2 authorize-security-group-ingress --group-name MemcachedSecurityGroup --protocol tcp --port 11211 --source-group PgPoolSecurityGroup MEMCACHEDSECURITYGROUPID=$(aws ec2 describe-security-groups \ --group-names MemcachedSecurityGroup \ --query 'SecurityGroups[0].GroupId' | \ sed "s/\"//g") aws elasticache create-cache-cluster \ --cache-cluster-id PgPoolCache \ --cache-node-type cache.m3.medium \ --num-cache-nodes 1 \ --engine memcached \ --engine-version 1.4.5 \ --security-group-ids $MEMCACHEDSECURITYGROUPID aws elasticache wait cache-cluster-available --cache-cluster-id PgPoolCache
4. SSH를 통해 EC2 인스턴스 접근 후 필요한 패키지 설치 :
ssh -i <your pem file goes here> ec2-user@$INSTANCEIP sudo yum update -y sudo yum group install "Development Tools" -y sudo yum install postgresql-devel libmemcached libmemcached-devel -y
5. pgpool 소스코드 tarball 을 다운로드 :
curl -L -o pgpool-II-3.5.3.tar.gz http://www.pgpool.net/download.php?f=pgpool-II-3.5.3.tar.gz
6. 소스 추출 및 컴파일 :
tar xvzf pgpool-II-3.5.3.tar.gz cd pgpool-II-3.5.3 ./configure --with-memcached=/usr/include/libmemcached-1.0 make sudo make install
7. pgpool과 함께 제공되는 샘플 conf를 통해 pgpool.conf 생성
sudo cp /usr/local/etc/pgpool.conf.sample /usr/local/etc/pgpool.conf
8. pgpool.conf 편집 :
사용하기 편한 편집기(vi editor 등)를 사용하여 /usr/local/etc/pgpool.conf를 열고 다음 매개변수를 찾아서 설정하십시오 :
- Setlisten_addresses 를 *로 변경
- Setport 를 5432로 변경
- Setbackend_hostname0 을 여러분의 Amazon Redshift 클러스터 endpoint로 변경
- Setbackend_port0를 5439로 변경.
- Setmemory_cache_enabled를 on으로 변경
- Setmemqcache_method를 memcached로 변경
- Setmemqcache_memcached_host를 ElastiCache endpoint 주소로 변경
- Setmemqcache_memcached_port를 ElastiCache endpoint 포트로 변경
- Setlog_connections를 on으로 변경
- Setlog_per_node_statement를 on으로 변경
- Setpool_passwd를 “으로 변경
여러분의 설정 파일에서 수정된 매개변수는 아래와 같을 것입니다:
listen_addresses = '*' port = 5432 backend_hostname0 = '<your redshift endpoint goes here>' backend_port0 = 5439 memory_cache_enabled = on memqcache_method = 'memcached' memqcache_memcached_host = '<your memcached endpoint goes here>' memqcache_memcached_port = 11211 log_connections = on log_per_node_statement = on
9. 사용권한 설정 :
sudo mkdir /var/run/pgpool sudo chmod u+rw,g+rw,o+rw /var/run/pgpool sudo mkdir /var/log/pgpool sudo chmod u+rw,g+rw,o+rw /var/log/pgpool
10. pgpool 시작 :
pgpool -n
pgpool은 이미 포트 5432에서 수신 대기 중입니다.
2016-06-21 16:04:15: pid 18689: LOG: Setting up socket for 0.0.0.0:5432 2016-06-21 16:04:15: pid 18689: LOG: Setting up socket for :::5432 2016-06-21 16:04:15: pid 18689: LOG: pgpool-II successfully started. version 3.5.3 (ekieboshi)
11. 구성 테스트 :
이제 pgpool이 실행 중이므로 Amazon Redshift 클라이언트가 Amazon Redshift 클러스터 엔드포인트 대신 pgpool 엔드포인트를 가리키도록 구성합니다. 엔드포인트 주소를 얻으려면 콘솔이나 CLI를 사용하여 EC2 인스턴스의 공개 IP 주소를 확인하거나 $INSTANCEIP 변수에 저장된 값을 인쇄하여 확인 할 수 있습니다.
#psql –h <pgpool endpoint address> -p 5432 –U <redshift username>
쿼리를 처음 실행하면 pgpool 로그에 다음 정보가 표시됩니다 :
2016-06-21 17:36:33: pid 18689: LOG: DB node id: 0 backend pid: 25936 statement: select
s_acctbal,
s_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 5
and p_type like '%TIN'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey,
and s_suppkey = ps_suppkey,
and s_nationkey = n_nationkey,
and n_regionkey = r_regionkey,
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
로그의 첫 번째 줄은 쿼리가 Amazon Redshift 클러스터에서 직접 실행되는 것을 보여줍니다. 이는 캐시 미스입니다. 데이터베이스에 대해 쿼리를 실행하면 결과를 반환하는데 6814.595ms 가 걸렸습니다.
동일한 조건을 사용하여 이 쿼리를 다시 실행하면 로그에 다른 결과가 표시됩니다 :
2016-06-21 17:40:19: pid 18689: LOG: fetch from memory cache
2016-06-21 17:40:19: pid 18689: DETAIL: query result fetched from cache. statement:
select
s_acctbal,
s_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 5
and p_type like '%TIN'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey,
and s_suppkey = ps_suppkey,
and s_nationkey = n_nationkey,
and n_regionkey = r_regionkey,
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
로그의 처음 두 줄을 통해 원하는 결과가 캐시를 통해 검색되는 것을 알 수 있습니다. 이는 캐시 히트입니다. 차이점은 엄청납니다. 쿼리를 실행하는데 247.719ms 밖에 걸리지 않았습니다. 즉, 이전 시나리오보다 30 배 빠르게 실행됩니다.
pgpool 캐싱 동작 이해
Pgpool은 여러분의 SELECT 쿼리를 가져온 결과의 키로 사용합니다.
캐싱 동작과 무효화는 몇 가지 방법으로 구성 할 수 있습니다.
- 자동 무효화
- 기본적으로 memqcache_auto_cache_invalidation은 on으로 설정됩니다. Amazon Redshift의 테이블을 업데이트하면 pgpool의 캐시가 무효화됩니다.
- 만료
- memqcache_expire는 결과가 캐시에 남아 있어야하는 시간을 초로 정의합니다. 기본값은 0이며 무한대를 의미합니다.
- 블랙리스트와 화이트리스트
- white_memqcache_table_list
- 캐시되어야 하는 테이블의 목록을 쉼표로 구분하여 정의. 정규 표현식이 허용됩니다.
- black_memqcache_table_list
- 캐시해서는 안되는 테이블의 목록을 쉼표로 구분하여 정의. 정규 표현식이 허용됩니다.
- 캐시 무시
- / * NO QUERY CACHE * /
- white_memqcache_table_list
쿼리에 * / NO QUERY CACHE * / 주석을 지정하면 쿼리는 pgpool 캐시를 무시하고 데이터베이스에서 결과를 가져옵니다.
예를 들어, 만약 pgpool이 DNS 이름 확인 또는 라우팅 문제로 인해 캐시에 연결하지 못하면, 데이터베이스 엔드포인트로 직접 연결하고 캐시를 전혀 사용하지 않습니다.
결론
Amazon Redshift 및 Amazon ElastiCache와 함께 pgpool을 사용하여 캐싱 솔루션을 쉽게 구현할 수 있습니다. 이 솔루션은 최종 사용자 경험을 크게 향상시키고 클러스터의 부하를 크게 줄일 수 있습니다.
이 글은 pgpool과 이 캐싱 아키텍처가 여러분에게 어떤 도움이 되는지 보여주는 한 가지 간단한 예제 입니다. pgpool 캐싱 기능에 대한 자세한 내용은 pgpool 설명서의 이곳 및 이곳 을 참조하시기 바랍니다. 해피 쿼리 (물론 캐싱). 질문이나 제안이 있으시면 아래에 의견을 남겨주십시오.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.

Amazon Redshift 를 위한 10가지 성능 튜닝 기법
최근 국내의 많은 고객 분들이 Amazon Redshift 도입을 고려하고 계시거나, 또는 이미 도입하여 사용하고 계십니다. 도입 전, PoC(Proof of Concept) 등의 과정을 통해서 기존 업무와의 호환성 또는 원하는 성능에 대한 평가 등을 하신 후에 사용하고 계시겠지만, 제목과 같이 Redshift 의 성능 튜닝에 도움이 될 수 있는 내용을 다시 한번 살펴보시라는 의미에서, 좋은 블로그 포스트를 번역하여 제공하고자 합니다.
원문은 Top 10 Performance Tuning Techniques for Amazon Redshfit(Ian Meyers is a Solutions Architecture Senior Manager with AWS, Zach Christopherson, an Amazon Redshift Database Engineer, contributed to this post)
—
Amazon Redshift는 완벽하게 관리되는 페타 바이트 규모의 대규모 병렬 데이터 웨어하우스로서 간단한 조작을 통한 높은 성능을 제공합니다. 확장에 어려움을 겪고있는 기존 데이터베이스 환경 가속화에서부터 빅데이터 분석을 위한 웹 로그 처리에 이르기까지 많은 고객들이 Amazon Redshift를 사용합니다. Amazon Redshift는 업계 표준 JDBC/ODBC 드라이버 인터페이스를 제공하므로 고객은 기존 비즈니스 인텔리전스 도구를 연결하고, 분석을 위해 사용하던 기존 쿼리를 재사용 할 수 있습니다.
Amazon Redshift는 프로덕션 트랜잭션 시스템 제 3 정규형 모델(3NF)에서 스타 및 스노플레이크 스키마 또는 간단한 플랫 테이블에 이르기까지 모든 유형의 데이터 모델을 실행할 수 있습니다. 고객이 Amazon Redshift를 채택하면 데이터 모델이 데이터베이스에 올바르게 배치되고 유지 관리되도록 아키텍처를 고려해야합니다. 이 게시물을 통해 고객은 Amazon Redshift를 채택 할 때 가장 많이 발견되는 문제를 해결할 수 있으며 각 문제를 해결하는 방법에 대한 구체적인 지침을 제공합니다. 여기에서 언급하는 각 항목을 처리하면 최적의 쿼리 성능을 달성하고 고객 요구 사항을 충족시키기 위해 효과적으로 확장 할 수 있을 것입니다.
이슈 #1 : 잘못된 컬럼 인코딩
Amazon Redshift는 열(Column) 기반 데이터베이스로, 행(Row)별로 디스크에 데이터를 구성하는 대신 데이터를 열 별로 저장하고, 런타임에 행들은 열 기반 스토리지에서 추출됩니다. 이 아키텍처는 대부분의 쿼리가 가능한 모든 차원과 측정의 특정 하위 집합 만을 액세스 하는, 많은 수의 열이 있는 테이블에 대한 분석 쿼리에 특히 적합합니다. Amazon Redshift는 SELECT 또는 WHERE 절에 포함 된 열의 디스크 블록에만 액세스 할 수 있으며, 쿼리를 평가하기 위해 모든 테이블 데이터를 읽을 필요가 없습니다. 열에 저장된 데이터도 인코딩 됩니다. (Amazon Redshift 데이터베이스 개발자 가이드에서 열 압축 유형 선택 참조), 이는 높은 읽기 성능을 제공하기 위해 많이 압축되어 있음을 의미합니다. 또한 Amazon Redshift는 색인(Index)을 생성하고 관리할 필요가 없다는 것을 의미합니다. 즉, 모든 열은 저장되는 데이터에 적합한 구조와 함께 자체 색인과 거의 같습니다.
열 인코딩을 사용하지 않고 Amazon Redshift 클러스터를 실행하는 것은 좋지 않은 방법이며, 열 인코딩이 최적으로 적용될 때 고객이 큰 성능을 얻을 수 있습니다. 이 모범 사례에서 벗어나는 경우 다음 쿼리를 실행하여 열 인코딩이 적용되지 않은 테이블이 있는지 확인하십시오.
SELECT database, schema || '.' || "table" AS "table", encoded, size
FROM svv_table_info
WHERE encoded='N'
ORDER BY 2;
그렇게 난 후, 다음 쿼리를 실행하여 인코딩되지 않은 테이블과 열을 검토하십시오.
SELECT trim(n.nspname || '.' || c.relname) AS "table",trim(a.attname) AS "column",format_type(a.atttypid, a.atttypmod) AS "type",
format_encoding(a.attencodingtype::integer) AS "encoding", a.attsortkeyord AS "sortkey"
FROM pg_namespace n, pg_class c, pg_attribute a
WHERE n.oid = c.relnamespace AND c.oid = a.attrelid AND a.attnum > 0 AND NOT a.attisdropped and n.nspname NOT IN ('information_schema','pg_catalog','pg_toast') AND format_encoding(a.attencodingtype::integer) = 'none' AND c.relkind='r' AND a.attsortkeyord != 1 ORDER BY n.nspname, c.relname, a.attnum;
최적으로 열 인코딩을 하지 않은 테이블이 있으면 AWS Labs GitHub의 Amazon Redshift Column Encoding 유틸리티를 사용하여 인코딩을 적용하십시오. 이 명령 행 유틸리티는 각 테이블에서 ANALYZE COMPRESSION 명령을 사용합니다. 만약 인코딩이 필요한 경우, 올바른 인코딩으로 새 테이블을 만들고 모든 데이터를 새 테이블에 복사 한 다음 원래 데이터를 유지하면서 새 테이블의 이름을 이전 이름으로 트랜잭션 방식으로 변경하는 SQL 스크립트를 생성합니다. (복합 정렬 키(compound sort key)의 첫 번째 열은 인코딩 하면 안되며, 이 유틸리티로 인코딩 되지 않습니다.)
이슈 #2 : 왜곡된 테이블 데이터
Amazon Redshift는 클러스터의 각 노드가 전체 데이터의 일부를 저장하는 분산된 비 공유 데이터베이스 아키텍처입니다. 테이블을 만들 때 노드 간에 데이터를 고르게 분산(기본값) 할지 또는 열 중 하나를 기준으로 노드에 데이터를 분산할지 결정해야 합니다. 일반적으로 함께 조인되는 열을 분산의 기준으로 선택하면, 조인 중에 네트워크를 통해 전송되는 데이터의 양을 최소화 할 수 있습니다. 이렇게 하면 여러가지 유형의 쿼리에서 성능이 크게 향상 될 수 있습니다.
좋은 분산 키(Distribution Key)를 선택하는 것은 “가장 적합한 분산 스타일 선택“을 포함한 많은 AWS 관련 글들의 주제입니다. Amazon Redshift 에서 스타 스키마 최적화 및 인터리빙된 정렬 블로그 게시물을 통해 스타 스키마의 분산과 정렬에 대한 확실한 안내를 받으시기 바랍니다. 일반적으로 좋은 분산 키는 다음과 같은 속성을 가지고 있습니다.
- 높은 카디널리티 – 클러스터의 노드 수에 비례하여 열에 많은 수의 고유 한 데이터 값이 있어야 합니다.
- 균일 분산 / 저 왜곡 – 분산 키의 각 고유 값은 테이블에서 짝수 번 발생해야 합니다. 이렇게 하면 Amazon Redshift가 클러스터의 각 노드에 동일한 수의 레코드를 넣을 수 있습니다.
- 일반적으로 조인 – 분산 키의 열은 일반적으로 다른 테이블에 조인하는 열 이어야 합니다. 이 기준에 맞는 여러 개의 가능한 열이 있는 경우 가장 큰 테이블에 조인하는 열을 선택할 수 있습니다.
왜곡된 분산 키는 쿼리 실행 시 각 노드들이 똑같이 힘들지 않고, CPU 또는 메모리의 불균형이 발생하며 그리고 궁극적으로 가장 느린 노드의 속도만큼 실행됩니다.

왜곡 문제가 있는 경우 일반적으로 노드들의 성능이 클러스터에서 고르지 않은 것으로 나타납니다. Amazon Redshift Utils GitHub 저장소의 관리 스크립트 중 하나(예 : table_inspector.sql)를 사용하여 분산 키의 데이터 블록을 클러스터의 슬라이스 및 노드에 매핑하는 방법을 확인하십시오.
왜곡된 분산 키가 있는 테이블이 있는 경우, 배포 키를 높은 카디널리티와 균일 한 분포를 나타내는 열로 변경하십시오. CTAS를 사용하여 새 테이블을 작성하여 후보 열을 분산 키로 평가하십시오.
CREATE TABLE MY_TEST_TABLE DISTKEY (<COLUMN NAME>) AS SELECT * FROM <TABLE NAME>;테이블에 대해 table_inspector.sql 스크립트를 다시 실행하여 데이터 왜곡을 분석하십시오.
레코드에 좋은 분산 키가 없으면 단일 노드를 핫스폿으로 만들지 않기 위해 EVEN 방식으로 분산하는 것이 효과적이라는 것을 알 수 있습니다. 작은 테이블의 경우 DISTSTYLE ALL을 사용하여 테이블 데이터를 클러스터 내의 모든 노드에 저장 할 수 있습니다.
이슈 #3 : 정렬 키를 사용하지 않는 쿼리
Amazon Redshift 테이블에는 다른 데이터베이스의 인덱스처럼 작동하지만 다른 플랫폼과는 달리 저장소 비용이 발생하지 않는 정렬 키 열을 설정할 수 있습니다. 자세한 내용은 정렬 키 선택을 참조하십시오. 정렬 키는 WHERE 절에서 가장 일반적으로 사용되는 열에 작성되어야 합니다. 알려진 쿼리 패턴이 있는 경우 COMPOUND 정렬 키가 최상의 성능을 제공합니다. 최종 사용자가 다른 열을 똑같이 쿼리하면 INTERLEAVED 정렬 키를 사용하십시오.
정렬 키가 없는 테이블을 찾고, 얼마나 자주 쿼리가 되었는지 확인하려면 다음 쿼리를 실행합니다.
SELECT database, table_id, schema || '.' || "table" AS "table", size, nvl(s.num_qs,0) num_qs
FROM svv_table_info t
LEFT JOIN (SELECT tbl, COUNT(distinct query) num_qs
FROM stl_scan s
WHERE s.userid > 1
AND s.perm_table_name NOT IN ('Internal Worktable','S3')
GROUP BY tbl) s ON s.tbl = t.table_id
WHERE t.sortkey1 IS NULL
ORDER BY 5 desc;
Amazon Redshift Developer Guide에서 정렬되지 않은 테이블을 처리하는 방법론을 참고하실 수 있습니다. 또한 쿼리 활동을 기반으로 정렬 키 권장 이라는 GitHub 의 관리 스크립트를 활용할 수도 있습니다. 정렬 키 열에 대해 평가 된 조회는 정렬 키에 SQL 함수를 적용해서는 안됩니다. 대신 비교 값에 함수를 적용하여 정렬 키가 사용되는지 확인하십시오. 이것은 일반적으로 정렬 키로 사용되는 TIMESTAMP 컬럼에서 발견됩니다.

이슈 #4 : 통계가 없거나 버큠(vacuum)이 필요한 테이블
Amazon Redshift는 다른 데이터베이스와 마찬가지로 쿼리를 계획 할 때 올바른 결정을 내리기 위해 테이블 및 저장될 테이터 블록의 구성에 대한 통계정보가 필요합니다(자세한 내용은 테이블 분석 참조). 좋은 통계가 없으면 옵티마이저는 테이블에 액세스하는 순서나 데이터 세트를 조인하는 방법에 대해 최선이 아니거나 잘못된 선택을 할 수 있습니다.
Amazon Redshift Developer Guide의 ANALYZE Command History 항목은 누락되거나 부실한 통계를 해결하는 데 도움이 되는 쿼리를 제공하며, missing_table_stats.sql 관리 스크립트를 실행하여 통계가 누락 된 테이블을 확인하거나 아래 구문을 사용하여 오래된 통계정보를 가지고 있는 테이블을 확인할 수 있습니다.
SELECT database, schema || '.' || "table" AS "table", stats_off
FROM svv_table_info
WHERE stats_off > 5
ORDER BY 2;
Amazon Redshift에서 데이터 블록은 변경 불가능합니다. 행이 삭제되거나 업데이트되면 단순히 논리적으로 삭제되고 (삭제 플래그가 있음) 디스크에서 물리적으로 제거되지는 않습니다. 업데이트로 인해 새로운 블록이 작성되고 새로운 데이터가 추가됩니다. 이 두 가지 조작으로 인해 행의 이전 버전이 계속해서 디스크 스페이스를 소비하고 특정 쿼리가 테이블을 스캔할 때 논리적으로 삭제된 행이 계속 읽히게 됩니다. 결과적으로, 테이블의 저장 공간이 증가하고, 스캔 중에 디스크 I/O를 피할 수 없으므로 성능이 저하됩니다. VACUUM 명령은 삭제 된 행에서 공간을 복구하고 정렬 순서를 복원합니다.
누락되거나 오래된 통계가 있거나 버큠이 필요한 테이블 문제를 해결하려면 AWS Labs 유틸리티인 Analyze & Vacuum Schema 를 실행하십시오. 이렇게 하면 항상 최신 통계를 유지하고 실제로 재구성이 필요한 테이블들만 버큠을 할 수 있습니다.
이슈 # 5 – 매우 큰 VARCHAR 열을 가진 테이블
복잡한 쿼리를 처리하는 동안 중간 쿼리 결과를 임시 블록에 저장해야 할 수 있습니다. 이러한 임시 테이블은 압축되지 않으므로 불필요하게 넓은 열은 과도한 메모리 및 임시 디스크 공간을 소비하므로 쿼리 성능에 영향을 줄 수 있습니다. 자세한 내용은 가능한 가장 작은 열 크기 사용을 참조하십시오.
다음 쿼리를 사용하여 최대 열 너비를 포함하는 테이블 목록을 검토할 수 있습니다.
다음 쿼리를 사용하여 최대 열 너비를 포함하는 테이블 목록을 검토할 수 있습니다.
SELECT database, schema || '.' || "table" AS "table", max_varchar
FROM svv_table_info
WHERE max_varchar > 150
ORDER BY 2;
테이블 목록을 얻은 후에는, 다음 쿼리를 사용하여 넓은 varchar 열을 가진 테이블 열을 식별 한 다음 각 열에 대한 실제 최대 너비를 결정하십시오.
SELECT max(len(rtrim(column_name)))
FROM table_name;
경우에 따라 JSON 함수를 사용하여 쿼리하는 JSON 조각을 테이블에 저장하기 때문에 큰 VARCHAR 유형 열이 있을 수 있습니다. top_queries.sql 관리 스크립트를 사용하여 데이터베이스에 대해 가장 많이 실행되는 쿼리를 찾는 경우, JSON 조각 열을 포함하는 SELECT * 쿼리에 특히 주의하십시오. 최종 사용자가 이러한 큰 열을 쿼리하지만 실제로 JSON 함수를 사용하지 않으면, 원래 테이블의 기본 키 열과 JSON 열만 포함하는 다른 테이블로 데이터를 이동하는 것이 좋습니다.
필요한 것보다 넓은 열이 테이블에 있는 경우 deep copy 를 수행하여 적절한 너비의 열로 구성되는 새로운 버전의 테이블을 만들어야 합니다.
이슈# 6 – 큐(Queue) 슬롯에서 대기중인 쿼리
Amazon Redshift는 작업 부하 관리(WLM)라는 큐 시스템을 사용하여 쿼리를 실행합니다. 서로 다른 작업 부하를 분리하기 위해 최대 8 개의 큐를 정의 할 수 있으며 전체 처리량 요구 사항을 충족하도록 개별 큐의 동시성을 설정할 수 있습니다.
어떤 경우에는 사용자 또는 쿼리가 할당 된 큐가 완전히 사용 중이어서 추가 쿼리는 슬롯이 열릴 때까지 대기 해야합니다. 이 시간 동안 시스템은 추가 쿼리를 전혀 실행하지 못하기 때문에 이는 동시성을 높여야 한다는 신호입니다.
먼저 queuing_queries.sql 관리 스크립트를 사용하여 쿼리가 대기 중인지 여부를 확인해야합니다. 그리고 난 후 wlm_apex.sql을 사용하여 과거에 클러스터가 필요로 했던 최대 동시성을 검토하고 wlm_apex_hourly.sql을 사용하여 시간별 히스토리 분석을 진행하십시오. 동시성을 높이면, 동시에 더 많은 쿼리를 실행할 수 있지만 동일한 양의 메모리(증가시키지 않는 한)를 공유한다는 점을 유의하십시오. 동시성을 높이면 일부 쿼리는 실행 중에 임시 디스크 저장소를 사용하여야 하며, 다음 문제에서 볼 수 있듯이 최적의 방안은 아닙니다.
이슈 # 7 – 디스크 기반 쿼리
쿼리가 메모리에서 완전히 실행될 수 없는 경우, Explain 플랜의 일부에 대해 디스크 기반의 임시 저장 영역을 사용해야 할 수도 있습니다. 추가적인 디스크 I/O는 쿼리 속도를 늦추게 되는데, 이는 세션에 할당 된 메모리 양을 늘림으로써 해결할 수 있습니다(자세한 내용은 WLM 동적 메모리 할당 참조).
디스크에 사용하는 쿼리가 있는지 확인하려면 다음 쿼리를 사용하십시오.
SELECT
q.query, trim(q.cat_text)
FROM (SELECT query, replace( listagg(text,' ') WITHIN GROUP (ORDER BY sequence), '\n', ' ') AS cat_text FROM stl_querytext WHERE userid>1 GROUP BY query) q
JOIN
(SELECT distinct query FROM svl_query_summary WHERE is_diskbased='t' AND (LABEL LIKE 'hash%' OR LABEL LIKE 'sort%' OR LABEL LIKE 'aggr%') AND userid > 1) qs ON qs.query = q.query;
사용자 또는 큐 할당 규칙에 따라 선택한 큐에 지정된 메모리 양을 늘려서 완료해야하는 쿼리가 디스크를 사용하지 않도록 할 수 있습니다. 세션의 WLM_QUERY_SLOT_COUNT 를 기본값인 1에서 큐의 최대 동시성으로 늘릴 수도 있습니다. 문제# 6에서 설명한 것처럼 쿼리 대기열이 생길 수 있으므로 주의해서 사용해야 합니다.
이슈 # 8 – 커밋 큐 대기
Amazon Redshift는 트랜잭션 처리가 아닌 분석 쿼리를 위해 설계 되었습니다. COMMIT 비용이 상대적으로 높기 때문에 COMMIT를 과도하게 사용하면 쿼리가 커밋 큐를 액세스하기 위해 기다릴 수 있습니다.
데이터베이스에 너무 자주 커밋하는 경우commit_stats.sql 관리 스크립트로 커밋 큐에서 대기하는 쿼리가 증가하는 것을 볼 수 있습니다. 이 스크립트는 지난 2 일 동안 실행 된 쿼리의 최대 큐 길이 및 큐 시간을 보여줍니다. 만약 커밋 큐에서 대기중인 쿼리가 있는 경우, 진행상황을 로깅하거나 비효율적인 데이터 로드를 구행하는 ETL 작업과 같이, 세션 당 다수의 커밋을 수행하는 세션을 찾아야 합니다.
이슈 # 9 – 비효율적인 데이터 로드
Amazon Redshift 모범 사례는 COPY 명령을 사용하여 데이터로드를 수행 할 것을 제안합니다. 이 API 작업은 클러스터의 모든 컴퓨트 노드를 사용하여 Amazon S3, Amazon DynamoDB, Amazon EMR HDFS 파일 시스템 또는 SSH 연결과 같은 원본에서 데이터를 병렬로 로드 합니다.
데이터 로드를 수행 할 때 가능하다면 로드 할 파일을 압축해야 합니다. Amazon Redshift는 GZIP 및 LZO 압축을 모두 지원합니다. 하나의 큰 파일보다 많은 수의 작은 파일을 로드하는 것이 더 효율적이며 이상적인 파일 수는 슬라이스 수의 배수입니다. 노드 당 슬라이스 수는 클러스터의 노드 크기에 따라 다릅니다. 예를 들어, 각 DS1.XL 컴퓨트 노드에는 두 개의 슬라이스가 있고 각 DS1.8XL 컴퓨트 노드에는 16 개의 슬라이스가 있습니다. 슬라이스 당 짝수 개의 파일을 사용함으로써 COPY 실행이 클러스터 리소스를 고르게 사용하고 최대한 빨리 완료됨을 알 수 있습니다.
안티 패턴은 단일 레코드를 INSERT 하거나 또는 한 번에 최대 16MB 데이터를 INSERT 할 수 있는 다중 값 INSERT 문의 사용으로 Amazon Redshift에 직접 데이터를 INSERT하는 것입니다. 이는 리더 노드 기반 작업이며 리더 노드의 CPU 또는 메모리 사용을 극대화하여 성능 병목 현상을 유발할 수 있습니다.
이슈 # 10 – 비효율적인 임시 테이블 사용
Amazon Redshift는 임시 테이블을 제공합니다. 이 테이블은 단일 세션 내에서만 볼 수 있다는 것을 제외하면 일반 테이블과 같습니다. 사용자가 세션의 연결을 끊으면 테이블은 자동으로 삭제됩니다. 임시 테이블은 CREATE TEMPORARY TABLE 구문을 사용하거나 SELECT … INTO #TEMP_TABLE 쿼리를 실행하여 만들 수 있습니다. SELECT … INTO 및 C(T)TAS 명령은 입력 데이터를 사용하여 열 이름, 크기 및 데이터 유형을 결정하고 기본 저장소 특성을 사용하는 반면 CREATE TABLE 문은 임시 테이블의 정의를 완벽하게 제어합니다.
이러한 기본 저장소 속성은 신중하게 고려하지 않으면 문제가 발생할 수 있습니다. Amazon Redshift의 기본 테이블 구조는 열 인코딩이 없는 EVEN 분산 방법을 사용하는 것입니다. 이것은 많은 유형의 쿼리에 대해 차선의 데이터 구조이며, select/into 구문을 사용하는 경우 열 인코딩이나 분산 및 정렬 키를 설정할 수 없습니다.
CREATE 문을 사용하려면 모든 select/into 구문을 변환하실 것을 권장합니다. 이렇게 하면 임시 테이블에 열 인코딩이 적용되고 워크플로의 일부인 다른 엔터티에 동정적인 방식으로 분산됩니다. 사용하는 명령문을 변환하려면 다음을 수행하십시오.
select column_a, column_b into #my_temp_table from my_table;
최적의 열 인코딩을 위해 임시 테이블을 분석합니다.

그런 다음 select/into 문을 다음으로 변환합니다.
BEGIN;
create temporary table my_temp_table(
column_a varchar(128) encode lzo,
column_b char(4) encode bytedict)
distkey (column_a) -- Assuming you intend to join this table on column_a
sortkey (column_b); -- Assuming you are sorting or grouping by column_b
insert into my_temp_table select column_a, column_b from my_table;
COMMIT;
임시 테이블이 후속 쿼리의 조인 테이블로 사용되는 경우 임시 테이블의 통계를 분석 할 수도 있습니다.
analyze my_temp_table;
이렇게 하면, 분산 키를 지정하고 열 인코딩을 사용하여 Amazon Redshift의 열 기반 특성의 장점을 취함으로써, 임시 테이블을 사용하는 기능은 그대로 유지되지만 클러스터에 데이터 위치를 제어 할 수 있습니다.
Tip: Explain plan 경고 사용
마지막 팁은 쿼리 실행 중에 클러스터의 진단 정보를 사용하는 것입니다. 이것은 STL_ALERT_EVENT_LOG라는 매우 유용한 뷰(view)에 저장됩니다. perf_alert.sql 관리 스크립트를 사용하여 지난 7 일 동안 클러스터에서 발생한 문제를 진단할 수 있습니다. 이는 시간이 지남에 따라 클러스터가 어떻게 발전 하는지를 이해하는 데 매우 귀중한 자료입니다.
요약
Amazon Redshift는 클라우드 기반에서 성능을 크게 향상시키고 비용을 절감 할 수 있는 완벽하게 관리되는 강력한 데이터 웨어하우스 입니다. Amazon Redshift는 모든 유형의 데이터 모델을 실행할 수 있지만 데이터를 저장하고 관리하는 방법을 알고 있으면 성능이 저하되거나 비용이 증가 할 수 있는 오류를 피할 수 있습니다. 일반적인 문제에 대한 간단한 진단 쿼리들을 실행하고 최상의 성능을 얻을 수 있도록 하십시오.
—
데이터 로딩 성능을 높이려면, Amazon Redshift에서 빠르게 데이터 로딩하기 글을 참고하시기 바랍니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.
Amazon Redshift에서 빠르게 데이터 로딩하기
Amazon Redshift는 페타바이트급의 데이터를 빠르고 저렴하고 간단하게 분석할 수 있는 클라우드 기반 데이터 웨어하우스(DW)서비스입니다. 병렬 실행, 압축 스토리지, 암호화 등 다양한 매니지드 서비스를 제공합니다. Amazon Redshift의 데이터 활용 크기는 160GB의 클러스터로 부터 1,000/TB/Year의 페타바이트급 대량 데이터를 다루는데 적합합니다.

우선 DW에서 데이터 로딩의 특성에 대해 살펴보겠습니다. 일반적으로 DW는 하나 이상의 서로 다른 데이터 소스에서 수집된 데이터의 통합 저장소로 사용합니다. 현재 및 과거의 데이터를 저장한 뒤, 데이터 분석가들이 기업 전체의 분석 보고서를 작성하는데 주로 사용됩니다. 상세한 일일 판매 분석, 연간 및 분기별 비교 또는 동향에 이르기까지 다양합니다.
일반적으로 데이터 분석가는 가능한 최신 데이터를 사용하고 싶어합니다만, 데이터 크기 및 업무의 특성으로 기존의 OLTP(Online Transaction Processing)와는 다른 방식으로 진행됩니다. 예를 들어, 웹 로그 분석 DW는 일반적으로 야간 또는 하루에 몇 번 데이터를 DW로 로드합니다. 하지만, 매 시간, 매 분 단위로 지속적으로 데이터를 갱신하려는 요구 사항도 있습니다.
이 글에서는 Amazon Redshift에서 짧은 주기로 지속적인 데이터를 로딩할 때, 더 빠르게 할 수 있는 모범 사례를 소개하고자 합니다. 이는 주별 또는 일별 로딩과는 다르게 빠른 시간 내에(수분 단위 등) 최신 데이터를 Amazon Redshift에 반영하기 위한 방법입니다. Amazon Redshift는 단일 MERGE 또는 UPSERT를 지원하지 않지만, 스테이징 테이블을 이용한 UPDATE 와 INSERT 조합을 이용하여 기존 테이블에 새로운 데이터를 효율적으로 추가할 수 있습니다. 스테이징 테이블에 아주 짧은 시간내에 데이터를 로딩하기 위해서 이 글에서 소개하는 방법이 여러분에게 의미 있을 것으로 생각합니다.
1. 데이터 입력 파일의 균형 맞추기
우선 Amazon Redshift 클러스터의 모든 컴퓨팅 노드를 효율적으로 사용하여 데이터를 로딩하기 위해서 COPY 명령어를 사용합니다. COPY 명령어는 Amazon S3, Amazon EMR, Amazon DynamoDB 또는 원격 호스트로 부터의 데이터 로딩을 병렬적으로 처리하기 때문에 많은 양의 데이터를 INSERT 구문에 비해 효율적으로 처리할 수 있습니다.
Amazon Redshift 클러스터는 노드들의 집합체 입니다. 클러스터의 각 노드는 자신의 운영체제, 전용 메모리 및 전용 디스크 저장 장치를 가지고 있습니다. 그 중 하나의 노드는 컴퓨팅 노드로 데이터 및 질의 처리 작업(query processing tasks)의 분배를 관리하는 리더 노드입니다. 그리고 컴퓨팅 노드의 디스크 스토리지는 몇 개의 슬라이스로 나누어 집니다. 이 때 슬라이스 갯수는 컴퓨팅 노드의 프로세서 갯수와 동일합니다. 예를 들어, DS1.XL 컴퓨팅 노드는 2개의 슬라이스를 가지고 있으며, DS1.8XL 컴퓨팅 노드에는 32개의 슬라이스가 있습니다. 가능한 모든 노드의 모든 슬라이스를 통해 고르게 데이터를 분산 저장하고, 병렬적으로 질의를 처리합니다.
가장 빠른 성능으로 데이터를 로딩하기 위해서는, 클러스터의 모든 슬라이스(하나의 가상 CPU, 메모리 및 디스크)에 동일한 양의 작업을 수행하도록 해야 합니다. 이것은 각 슬라이스당 수행 시간을 짧게 해주고, 선형에 가까운 확장을 보장합니다. 이를 위해서, 입력 파일의 수가 슬라이스 갯수의 배수인지 확인해야 합니다.
이제 여러분이 Amazon S3에서 데이터를 로딩하는 경우, Amazon S3에 업로드 하기 전에 Amazon Redshift 클러스터의 모든 슬라이스 갯수의 배수(1 또는 그 이상의)로 입력 파일을 분할하는 것이 필요합니다. 즉, 4대의 DS1.XL 컴퓨팅 노드로 클러스터를 생성하셨다면, 전체 슬라이스 갯수는 8 입니다. 이때 입력 파일을 8 또는 16/24/32 개로 분할하여 Amazon S3에 업로드 한 후, 단일 COPY 명령어로 모든 입력파 일을 병렬적으로 로딩하도록 하면 동시에 슬라이스 갯수만큼 로딩 작업이 수행됩니다.
아래 예는 Linux의 split 명령어를 통해 원하는 갯수로 파일을 분할하는 간단한 예제 입니다.
$ ls -la
total 12020
drwxrwxr-x 2 ec2-user ec2-user 4096 Jul 22 14:43 .
drwx------ 4 ec2-user ec2-user 4096 Jul 22 14:41 ..
-rw-rw-r-- 1 ec2-user ec2-user 12299878 Jul 22 14:41 customer-fw.tbl
$ split -l `wc -l customer-fw.tbl | awk '{print $1/16}'` -d --verbose customer-fw.tbl "customer-fw.tbl-"
creating file ‘customer-fw.tbl-00’
creating file ‘customer-fw.tbl-01’
...
creating file ‘customer-fw.tbl-14’
creating file ‘customer-fw.tbl-15’
$ ls -la
total 24052
drwxrwxr-x 2 ec2-user ec2-user 4096 Jul 22 14:44 .
drwx------ 4 ec2-user ec2-user 4096 Jul 22 14:41 ..
-rw-rw-r-- 1 ec2-user ec2-user 12299878 Jul 22 14:41 customer-fw.tbl
-rw-rw-r-- 1 ec2-user ec2-user 768750 Jul 22 14:44 customer-fw.tbl-00
-rw-rw-r-- 1 ec2-user ec2-user 768750 Jul 22 14:44 customer-fw.tbl-01
...
-rw-rw-r-- 1 ec2-user ec2-user 768750 Jul 22 14:44 customer-fw.tbl-14
-rw-rw-r-- 1 ec2-user ec2-user 768628 Jul 22 14:44 customer-fw.tbl-15이제 Amazon Redshift를 통해 COPY 명령을 수행해 보겠습니다.
copy customer
from 's3://<your-bucket-name>/load/customer-fw.tbl'
credentials 'aws_access_key_id=<Your-Access-Key-ID>; aws_secret_access_key=<Your-Secret-Access-Key>'
이제 Amazon S3에서 데이터를 로드하는 자세한 방법은 개발자 문서을 참고하시기 바랍니다.
2. 칼럼(Column) 압축 인코딩 미리 정의하기
Amazon Redshift 는 데이터가 저장될 때 크기를 줄일 수 있는 칼럼 레벨 압축을 지원합니다. 압축은 저장 공간을 절약하는 장점과 함께 스토리지로 부터 읽어야 할 데이터의 크기를 줄이기 위해 디스크의 I/O 를 줄임으로써 쿼리의 성능을 개선할 수 있는 방법입니다. Amazon Redshift 는 기본적으로는 압축되지 않은 형식으로 데이터를 저장합니다. 여러분은 테이블을 생성할 때 수동으로 각 칼럼의 압축 방식 또는 인코딩을 지정할 수 있습니다.
COPY 명령의 가장 큰 특징은 테이블이 비어있을 때 자동으로 최적의 칼럼 인코딩을 적용한다는 것입니다. 그러나, 이 작업은 약간의 시간이 필요합니다. 왜냐하면 자동 압축 분석을 위해서는 각 슬라이스 당 적어도 100,000행의 데이터를 먼저 샘플링 해야 하기 때문입니다. 아래는 COPY 명령을 통해 수행되는 자동 압축 분석 단계입니다.
- 입력 파일로 부터 초기 샘플링을 위한 행을 로딩 합니다. 샘플 데이터의 크기는 COMPROWS 파라미터 값을 통해 정의되는데, 특별한 지정이 없을 시 기본값은 100,000 입니다.
- 각 열에 알맞은 압축 옵션(인코딩 방식)이 결정됩니다.
- 초기 로딩된 샘플 행이 테이블에서 제거됩니다.
- 결정한 압축 옵션으로 테이블이 새롭게 생성됩니다.
- 전체 입력 파일을 새로운 인코딩 방식을 사용하여 로딩하고 압축합니다.
추후에 추가적인 데이터가 해당 테이블에 추가될 때는 기존에 결정된 인코딩 방식을 이용하여 압축됩니다.
아주 짧은 주기로 스테이징 테이블에 데이터를 추가해야 하는 상황에서는 사전에 인코딩 방식을 결정하여 테이블을 생성해 놓는다면 이런 자동 압축 분석의 단계를 생략할 수 있습니다. 이때 각 컬럼에 알맞는 정확한 인코딩 방식을 미리 결정해 놓아야 합니다.
이렇게 하려면 아래와 같이 테이블을 대표할 수 있는 데이터를 한 번 COPY 명령어를 통해서 로딩하고 난 후, pg_table_def에 기록된 각 컬럼의 인코딩 방식을 사용합니다. 그런 다음 테이블을 DROP 하고 앞에서 찾은 컬럼의 인코딩 방식을 포함하여 테이블을 생성합니다. 이후 COPY 명령어를 사용하여 데이터를 로딩 할 때, 자동 압축 분석 작업을 생략하도록 ‘COMPUPDATE OFF’를 추가합니다.
select "column", type, encoding from pg_table_def where tablename = 'nations';아래는 각 컬럼에 맞게 접합하게 선택된 인코딩 방법입니다.
| Column | Type | Ecoding |
| nationkey | integer | DELTA |
| name | character(25) | TEXT255 |
| regionkey | integer | RUNLENGTH |
| comment | character varying(152) | LZO |
그런 다음 테이블을 DROP 하고, 테이블 생성 DDL에 ENCODE 키워드를 추가하여 컬럼에 대한 인코딩 방식을 명시하고 테이블을 다시 생성합니다.
CREATE TABLE NATIONS (
NATIONKEY INT ENCODE DELTA,
NAME CHAR(25) ENCODE TEXT255,
REGIONKEY INT ENCODE RUNLENGTH,
COMMENT VARCHAR(152) ENCODE LZO
);이후 다시 데이터를 Amazon S3로 부터 COPY합니다.
copy nation
from 's3://<your-bucket-name>/load/nations.tbl'
credentials 'aws_access_key_id=<Your-Access-Key-ID>; aws_secret_access_key=<Your-Secret-Access-Key>'
COMPUPDATE OFF;3. 통계 계산의 빈도 줄이기
Amazon Redshift의 COPY 명령은 최적화(Optimizer)를 위해 각 데이터 로딩에 대해서 테이블의 통계를 계산합니다. 추후 질의(Query)를 위해서는 굉장히 유용하지만, 이 또한 시간이 걸립니다. 그래서 열 인코딩으로, 정해진 데이터 세트에 대해서 통계를 계산한 후 COPY 명령이 수행되는 동안 재계산을 막는 것이 빠른 데이터 로딩을 위한 좋은 방법입니다.
이를 위해서 압축 인코딩을 사전 정의하는 방식과 동일하게, 테이블을 대표할 수 있는 데이터 세트를 로딩한 다음, ANALYZE 명령어를 이용하여 분석을 할 수 있습니다. 그러고 난 후 매번 수행되는 COPY 명령어의 옵션으로 ‘STATUPDATE OFF’를 설정하여 자동 분석 작업을 중지할 수 있습니다.
단, Query를 효율성을 위해 테이블에 대한 통계정보를 최신으로 유지하기 위해서 주기적으로 ANALYZE 명령을 실행할 필요가 있습니다. 질의 설계기(Query planner)는 최적화된 query plan을 선택하기 위해서 테이블의 통계에 대한 메타데이터 정보를 사용하기 때문입니다.
만약 시간이 경과함에 따라 로딩한 데이터의 특성이 크게 변한 경우, 통계 및 컬럼 인코딩은 테이블 구조에 맞게 재계산해야 합니다.
4. 정렬키(Sort Keys) 순서로 데이터 로딩
Amazon Redshift은 테이블을 생성할 때 단일 또는 복수개 컬럼을 정렬키(Sort Keys)로 지정할 수 있습니다. Redshift는 1MB의 디스크 블록에 컬럼 데이터를 저장합니다. 각 블록에 저장된 최소값 그리고 최대값을 메타데이터로 관리합니다.
만약 질의에 범위 제한적인 조건이 포함된 경우, 테이블을 스캔하는 과정에서 필요한 블록만을 읽어 들일 수 있게 최소값, 최대값을 활용합니다. 질의에 필요한 블록에 대해서만 디스크 I/O를 일으킴으로써 질의에 대한 성능을 개선할 수 있는 좋은 기능입니다. 위와 같은 장점을 극대화 하기 위해, 데이터를 정렬키(Sort Keys)의 순서에 맞춰 로딩한다면 추후 테이블에 대한 VACUUM 작업을 회피할 수 있습니다.
Amazon Redshift 는 클러스터로 로딩하는 데이터를 정렬합니다.날짜 기반의 컬럼을 정렬키(Sort Keys)로 지정하셨다면 시간 순서로 데이터를 로딩하는 것이 좋은 방법입니다. 예를 들면, 정렬키로 설정된 순서대로 오후 1시 ~ 2시 데이터를 먼저 로딩하고 이후에 2시~3시 데이터를 로딩하는 방식입니다.
이 방식을 참고하여 데이터를 로딩한다면, VACUUM 명령을 delete 또는 update 작업의 결과로 발생하는 빈 공간(free space)을 회수하는 용도로만 사용하면 됩니다.
정렬키(Sort Keys)에 대한 자세한 내용은 기술 문서를 참고하시기 바랍니다.
5. SSD 노드 유형 사용하기
Amazon Redshift는 두 개(세부적으로는 6개)의 상이한 노드 유형을 제공하고 있습니다. 첫번째 ds1/ds2 패밀리는 마그네틱 디스크를 사용합니다. ds1(ds2).xlarge 노드 유형은 각 노드당 2TB의 사용 가능한 스토리지를 제공하고, ds1(ds2).8xlarge 노드 유형은 각 노드당 16TB 의 사용 가능한 스토리지를 제공합니다.
앞에서 설명드린 것 처럼 짧은 주기로 데이터를 로딩해야 하는 환경을 위해서라면 I/O 지연시간(latency)을 획기적으로 감소시킬 수 있는 SSD 디스크를 사용하는 dc1 패밀리를 사용하는 것이 도움이 됩니다. 데이터 로드의 간격(interval) 내에 원하는 데이터에 대한 로딩을 완료하기 위해서는 빠른 I/O가 필요 합니다. dc1.large는 각 노드당 160GB, dc1.8xlarge는 각 노드 당 2.56TB의 스토리지를 제공합니다. 이처럼 dc1 노드 유형은 높은 컴퓨팅-스토리지 비율을 제공하여 COPY 명령어를 수행할 때 낮은 지연 시간(latency)을 제공합니다.
지금까지 짧은 시간 간격으로 Amazon Redshift 로 데이터를 로드할 때 사용할 수 있는 다섯 가지 방법에 대해 알려드렸습니다. 특정 고객사의 경우, Amazon Redshift에서 위와 같은 방법들을 이용하여 데이터의 로드 시간을 90% 이상 개선한 경험이 있습니다. 물론 이러한 방법들이 모든 경우에 해당되는 것은 아닙니다. 다만, 하루에 한번 또는 일주일에 한번씩 배치(Batch)로 데이터를 로딩할 경우에는 약간 다른 방법을 사용 해야할 가능성도 있습니다. 여러분의 업무 목적에 맞는 적합한 방법을 사용하는 것이 업무의 효율성을 위해서는 매우 중요합니다.
마지막으로 2013년 re:Invent 에서 소개되었던 “Getting Maximum Performance from Amazon Redshift”세션에서의 HasOffers 사례 발표인 Fast Data Loads 부분도 참고해 보시길 권합니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 작성해주셨습니다.