AWS Partner Network (APN) Blog
Enabling Data-Centric Artificial Intelligence Through Snowflake and Amazon SageMaker
By Dylan Tong, Global Technical Lead, Decision Intelligence – AWS
By Andries Engelbrecht, Principal Partner Solutions Architect – Snowflake
By Bosco Albuquerque, Sr. Partner Solutions Architect – AWS
 |
| Snowflake |
 |
Data-centric AI (DCAI), as described by Dr. Andrew Ng, one of the pioneers of machine learning (ML), “is the discipline of systematically engineering the data used to build an AI system.” It prescribes prioritizing improving data quality over tweaking algorithms to improve ML models, which can power business foresight including customer churn, employee attrition, demand forecasting, credit risk, and more.
In this post, we’ll present a DCAI solution built on Snowflake and Amazon SageMaker to serve as a factory for predictive analytics solutions.
Amazon SageMaker is a fully-managed AWS service designed to help you manage the entire ML lifecycle. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations including AWS Competencies in Machine Learning and Data and Analytics.
This solution leverages Snowflake’s integrations with Amazon SageMaker. We’ll introduce you to these integrations and provide you with hands-on resources to help you put these capabilities into practice.
Why DCAI?
As state-of-the-art algorithms become more ubiquitous through open sourcing of ML research, data quality becomes increasingly the differentiator for ML initiatives. This post aims to help you enable a data-centric AI practice that improves your team’s operational capacity and scalability, and lower the time to deliver results.
Your team can achieve greater and faster gains by focusing on data quality such as correcting data errors or feature engineering—data transformations that amplify predictive signals. Furthermore, DCAI can be practiced without advanced ML skills. It enables you to leverage domain experts with limited ML expertise to offload your scarce data scientists.
DCAI promotes standard process and methodology enabling operational scalability and efficiency through reusable, automatable workflows.
DCAI Solution for Powering Predictive Analytics
To help you understand how to apply this solution, let’s consider a scenario—you’re an AWS customer using Snowflake for analytics workloads. You run a team of analysts, engineers, and data scientists that serve multiple business lines. Your team has a backlog of requests for foresight into the business, and ML models are well-suited for delivering high-performing predictive insights.
We’ll assume your team is adopting DCAI practices as part of your CRISP-DM based process.
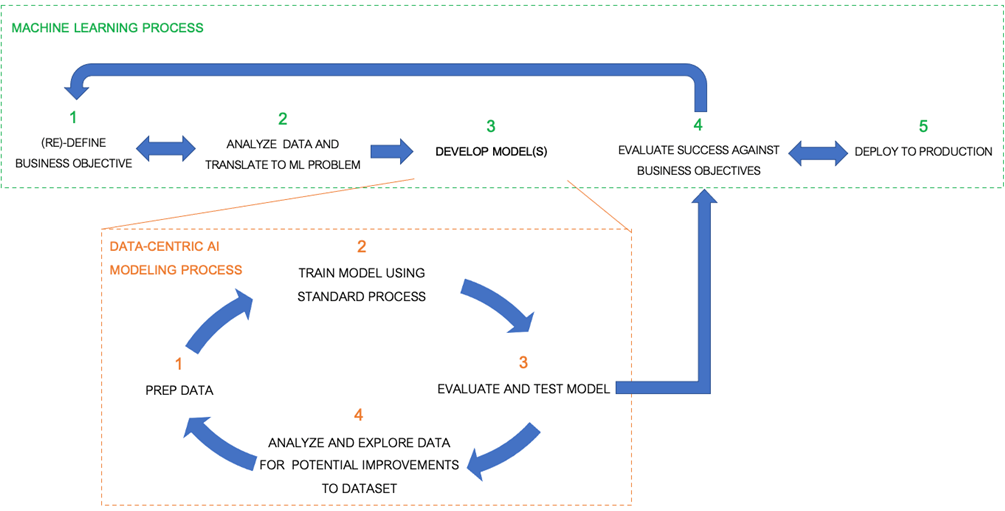
Figure 1 – Example process flow for DCAI model development based on industry standards.
Your team has defined business objectives and determined the models required to support your use cases, but you only have a few data scientists and they’re operating at full capacity.
Let’s walk through the six steps in Figure 2 below to understand the challenges and requirements for effective DCAI, and explore how the solution helps.

Figure 2 – DCAI solution architecture for AWS built on Snowflake and Amazon SageMaker.
Data Acquisition
Your DCAI practice will thrive if you provide your builders with access to diverse datasets that effectively represent the business functions you wish to improve—the quality of your models will only be as good as the quality of your data.
The first component of the solution is Snowflake, which serves as your enterprise data platform. It contains all of your business-critical data, and thus is a trove of information related to your target problems. The data you keep in Snowflake is inherently high-quality resulting from existing governance processes. It’s also sourced from business applications that capture ground truth by design, so additional labeling work is often unnecessary.
Your team can create ML datasets by taking snapshots of your data in Snowflake by using zero-copy-cloning as an alternative to keeping copies staged in Amazon Simple Storage Service (Amazon S3). This can help your team minimize bloat, and maintaining snapshots are important for ensuring you can reproduce models.
Your modelers may also be limited to what data they can use due to privacy requirements. However, these limitations can be minimized by running user-defined functions on Snowpark to obfuscate sensitive attributes or generate differentially private synthetic datasets by processing the data locally before sharing sensitive datasets through Snowflake’s Secure Data Sharing.
The second component of our solution highlights the ability to acquire third-party data sources to enhance the predictive signals of your datasets. For instance, this lab demonstrates how loan origination data enriched with macroeconomics data from the Snowflake Marketplace can uplift the accuracy of a credit risk model. Your team can also access third-party data providers through the AWS Data Exchange.
Data Quality
Data quality has many dimensions in the context of data-centric AI.
Is Your Data Trustworthy?
Does it conform to business rules? Is it already associated with a successful model? Your modelers will be more productive if they can quickly assess the trustworthiness of datasets.
The third component of our solution extends Snowflake with advanced capabilities for managing ML datasets through Amazon SageMaker and data governance partner technologies. By leveraging an enterprise data catalog provider like Collibra or Alation, your team can quickly discover and share datasets through a shopping interface and collaborate with business users during the modeling process.
Snowflake Data Quality (DQ) partners like Collibra and Talend also allow your team to apply rules to quantify, track and monitor DQ on Snowflake datasets. Depending on your choice of technology, DQ scores are surfaced through the catalog or as metadata in Snowflake allowing teams to quickly assess the trustworthiness of your datasets.
In addition to general data quality, there are ML-specific quality measures that are important to Responsible AI. Biases can exist in your dataset that can lead to ethical, legal, and compliance failure. For instance, a model that predicts credit-risk could be unintentionally trained to categorize applicants as high-risk based on minority group membership as a result of poor representation in the model training data.
Your team can schedule Amazon SageMaker Clarify jobs to evaluate data bias and keep your modelers informed about the risks in your sensitive datasets.
Optionally, your team can use a Feature Store to share and serve ML features and encourage reuse across your organization. They empower DCAI by promoting reuse of features for tackling problems similar to those addressed by proven production models. SageMaker provides native support for building dataflows that transform Snowflake datasets into ML features served by Amazon SageMaker Feature Store.
Are Your Labels Correct?
Consider a churn model trained on examples of customers who churned and ones that are still active—the attribute that indicates churn is called the label. Your model will be trained to make mistakes if your labels are wrong, so minimizing labeling errors is critical.
If your team requires data labeling, Amazon SageMaker Ground Truth helps scale and manage your internal and external labeling workforces like Amazon Mechanical Turk. SageMaker Ground Truth provides capabilities to manage label quality at scale like annotation consolidation, which combines labels produced by multiple workers to mitigate errors.
Alternatively, you can outsource operations to Amazon SageMaker Ground Truth Plus, which provides a turnkey service and experts experienced with managing high-quality labels.
Where Are the “Data Bugs?”
Data drives everything in DCAI. If a bug arises, it’s likely related to your data. Your team needs mechanisms for identifying data issues. Capabilities that simplified data versioning, lineage tracing, and error analysis are important facilitators.
Lineage tracking provides you visibility into the path from raw data to an operationalized model to help you identify upstream changes that could be the cause of problems downstream. Amazon SageMaker provides ML Lineage Tracking that allows you to query lineage entities such as the training configurations associated with your models.
Snowflake’s Data Lineage partner offerings extend the limits of SageMaker lineage tracking. A good solution tracks the dataflow between Snowflake and the S3 URIs used by Amazon SageMaker, and provide visibility into the upstream processes that refresh your datasets. Among your options are vetted AWS and Snowflake partners like Collibra, Atlan, and Informatica.
Data-Centric Development
DCAI development is iterative: a builder may experiment with a new dataset or introduces a new ML feature, re-train a model on the new dataset, and then test for a performance uplift. The challenge is that model training is computationally expensive and slow. Your modelers need a cost-effective solution that enables rapid prototyping.
Secondly, if you’re going to keep “the code fixed”—as prescribed by DCAI advocates—your solution should enforce a standard modeling process; for instance, as a generalized workflows that are highly reusable. Use AutoML to provide a generalized process for automating model-centric optimizations like algorithm selection and last-mile hyperparameter tuning while your team focuses on data-centric optimizations. This allows your team to benefit from a DCAI strategy without forgoing the performance gains offered by tweaking your code.
The fourth part of our solution enables a DCAI-style modeling by providing different user experience for varying levels of ML expertise and required customization.
For Data Scientists
For your data scientists who seek a balance between flexibility and productivity, they have the option to build custom data prep flows for their Snowflake datasets with little code using Amazon SageMaker Data Wrangler.

Figure 3 – Designing data prep flows for Snowflake datasets on SageMaker Data Wrangler.
This lab is a good starting point for your modelers to learn how SageMaker Data Wrangler can support DCAI modeling. You’ll learn to source and prep loan origination data from Snowflake and build a model that predicts default risk, and you’ll use tools like Quick Model to rapidly prototype models to test potential improvements to your dataset.

Figure 4 – Quick Model reports are among the capabilities that enable rapid prototyping.
You’ll learn how to iteratively re-engineer your dataset by augmenting it with unemployment rate statistics to improve its predictive signals, and re-validate its integrity using tools like the Target Leakage report.

Figure 5 – Target Leakage report indicates the unemployment rate feature is safe.
With each iteration, you’ll use Quick Model to regenerate the prototype and test for an uplift. In the lab, you’ll discover the newly-added feature—unemployment rate—has high-impact and improves your prototype’s performance.
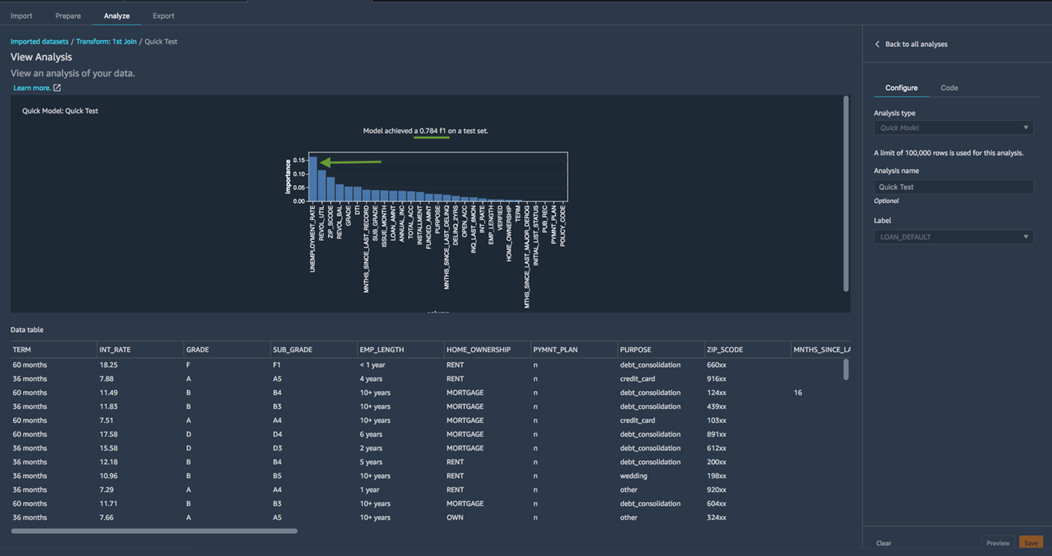
Figure 6 – Successive runs of the Quick Model report tell us whether changes to our dataset are beneficial.
Once you’re ready to fully train a model, the dataflows can be exported as a customizable script and executed as an Amazon SageMaker processing job to create your training-ready dataset.
Your data scientist can run custom algorithms on Amazon SageMaker to train a model, but we recommend using Amazon SageMaker Autopilot to standardize your model generation process and focus on improving your dataset.
SageMaker Autopilot provides your team with a fully-managed AutoML service that generates optimized regression and classification models—models that predict a number or a category and cover a broad range of use cases. A classification model, for instance, could predict the default probability of a loan applicant and assign them into risk categories.
SageMaker Autopilot automates feature engineering, algorithm selection, and hyperparameter tuning to produce a leaderboard of candidate models as follows.
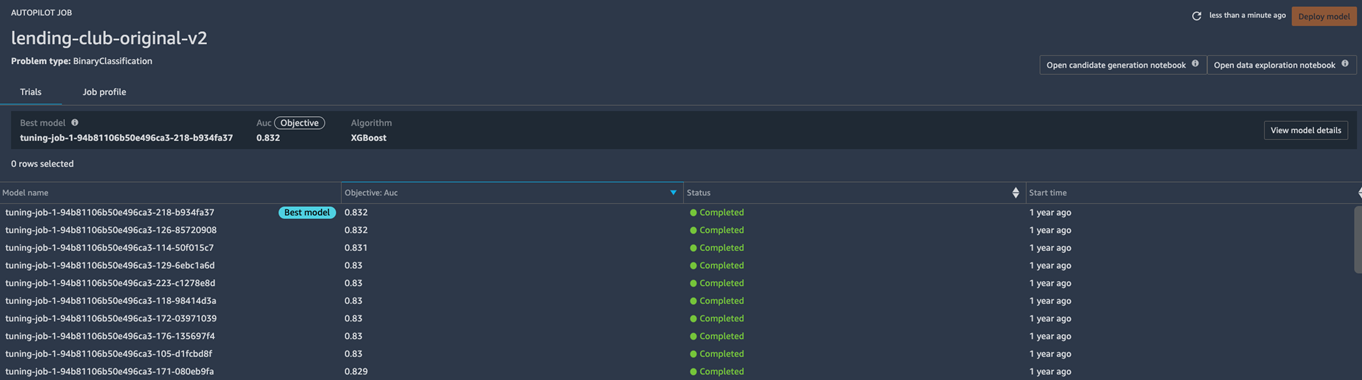
Figure 7 – SageMaker Autopilot generates a leaderboard of candidate models and surfaces the best optimizations.
Conveniently, it operates directly on your datasets—namely, it expects a tabular dataset and target labels as input. The DCAI practitioners’ job is to iteratively improve datasets and use SageMaker Autopilot to generate tuned models. All of the training jobs are audited in Amazon SageMaker Experiments, allowing your team to reproduce the models.
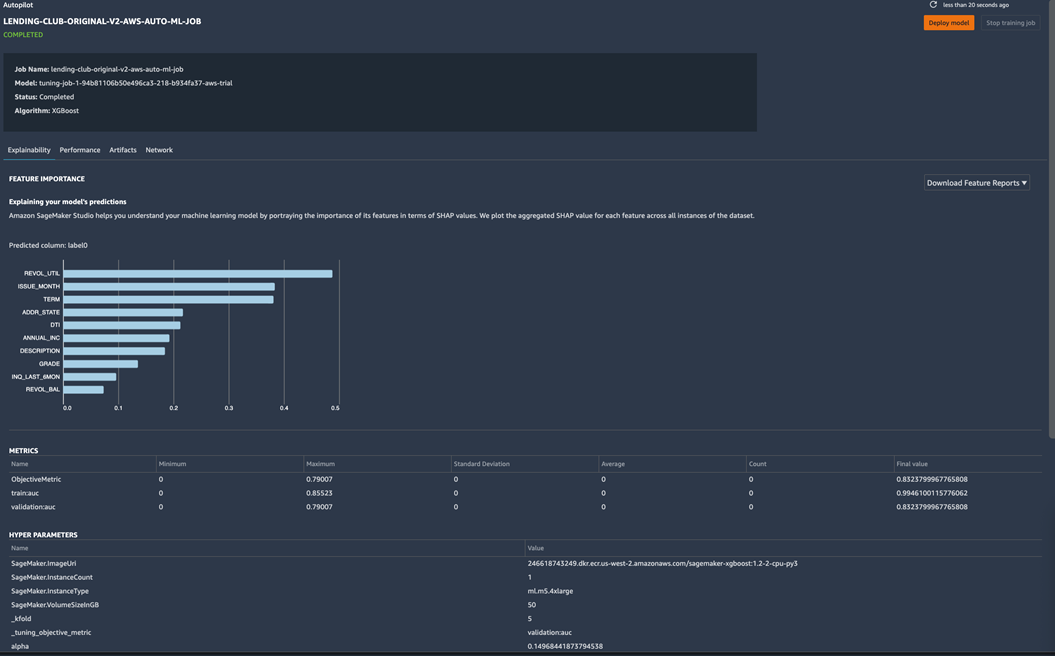
Figure 8 – Experiments automated by SageMaker Autopilot are tracked enabling reproducibility.
For Data Analysts and Engineers
If your project doesn’t require advanced feature engineering, you can empower your analysts to offload your data scientists using Snowflake’s integration with SageMaker Autopilot. This is called Snowflake AutoML, and it enables users to create and integrate optimized models directly through Snowflake.
Your analysts can use SQL to clone and manipulate datasets through their everyday editor and run an AutoML job with a single command:

Figure 9 – Generate optimized models using Snowflake SQL.
Predictions from the generated models can be queried and joined with other data sources. This lab provides your team with some hands-on experience with this capability. The lab guides you through the process of turning financial transactions into fraud risk insights with just several database commands.

Figure 10 – Run SQL queries to obtain predictions from Snowflake Autopilot-generated models.
To enable this capability, your team should use the AWS Quick Start titled Amazon SageMaker Autopilot for Snowflake to provision the integration components into your AWS account.
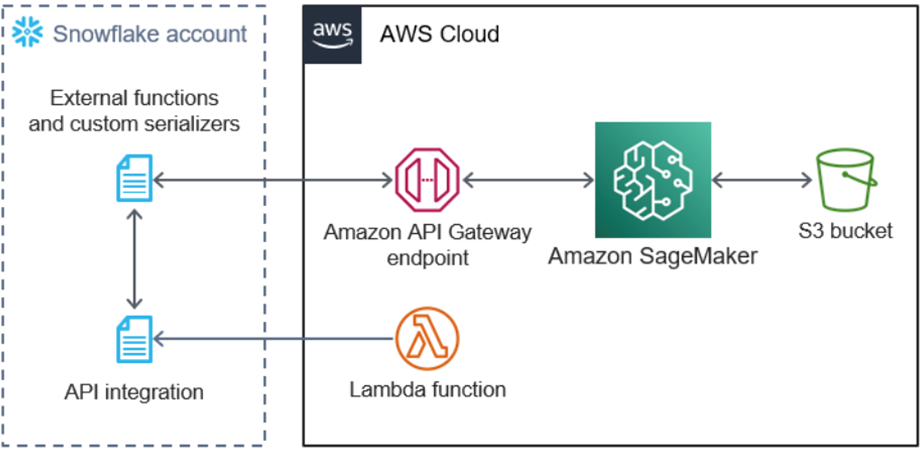
Figure 11 – AWS Quick Start to enable Snowflake Autopilot.
Analytics-Ready Interface
Delivering predictive analytics requires more than just operationalizing machine learning models. Your team needs to deliver predictions through your incumbent analytics toolchain. The fifth component of our solution highlights the analytics-ready interface provided by Snowflake’s integrations.
Models generated through Snowflake AutoML provide a SQL interface. You can also integrate SageMaker Autopilot-generated models that were created directly through Amazon SageMaker through the external functions provisioned by the AWS Quick Start (Figure 11). You simply need to include “-job” as a suffix in your SageMaker Autopilot job name. For instance, by naming your job “my-model-job”, Snowflake will be able to identified the deployed endpoint as “my-model”.
The SQL interface for ML models simplifies the operationalization of models for analytics workloads. Your incumbent analytics tools that run on SQL, like your business intelligence (BI) platforms, can tap into real-time predictions without customizations. This allows your team to deliver fresher insights with less effort.
This capability also allows modelers to use their everyday visualization tools to perform error analysis without writing code—that is to compare predictions against expected results to gain insights into errors and how to correct them.
Alternatively, if your use case permits it, you can deploy a batch inference pipeline to periodically materialize predictions into Snowflake. You can refer to the aforementioned lab on how to do this using Amazon SageMaker Pipelines, Batch Transform, and Snowpipe.
Continuous Improvement
ML model development is a continuous function. Each model requires maintenance and should be continually improved. The sixth component of the solution provides the capabilities to facilitate this continuous process.
Models have a shelf-life as their performance degrades over time. For instance, a product recommender can degrade as consumer tastes and brand perceptions shift—models require re-training for maintenance. Your team has the option to enable Amazon SageMaker Model Monitor on each of your SageMaker-hosted models to monitor data quality, model quality, bias, and feature attribution drift.
Your team can also deploy human review workflows alongside your hosted models with Amazon Augmented AI. These workflows can prompt humans to intervene on low-confidence predictions and solicit these experts for data to retrain and improve the model.
As your team continually deploys new model variants into production, deployment guardrails will assist with advanced deployment strategies like canary that mitigate the risk of unintended faulty models.
Conclusion
A data-centric AI (DCAI) strategy can help your team deliver successful outcomes on your machine learning initiatives quickly and efficiently. In this post, you’ve learned how you can put DCAI into practice. Next, your team can gain experience by working through these labs:
- Data-centric Approach to Machine Learning Using Snowflake and Amazon SageMaker Data Wrangler
- Snowflake and Amazon SageMaker Autopilot Integration: Machine Learning with SQL
If you’d like to test drive Snowflake Autopilot, be sure to take advantage of this AWS Quick Start to launch the integration. At last, think big and have fun on your DCAI journey!
.

.
Snowflake – AWS Partner Spotlight
Snowflake is an AWS Competency Partner that has reinvented the data warehouse, building a new enterprise-class SQL data warehouse designed from the ground up for the cloud and today’s data.