Amazon Web Services ブログ
AWS Lambda: レジリエンスの詳細
この記事は、Adrian Hornsby (プリンシパル システム デベロッパー エンジニア) と Marcia Villalba (プリンシパル デベロッパー アドボケイト) が執筆しています。
AWS Lambda は 80 を超えるサービスで構成され、連携し、お客様へサーバーレスコンピューティングサービスを提供しています。内部的には、これらのサービスの多くは、アベイラビリティーゾーン内でプロビジョニングされた Amazon Elastic Compute Cloud (Amazon EC2) インスタンス上に構築されています。ただし、AWS Lambda はリージョンサービスです。つまり、顧客はリージョンレベルで Lambda を使用でき、その基盤であるアベイラビリティーゾーンで起きる可能性のある障害に対してレジリエントであるように設計されていることを意味します。
このブログ記事では、Lambda などのリージョンサービスがアベイラビリティーゾーンと静的安定性を活用して 高可用性の目標を達成する方法について説明し、Lambda チームが AWS Fault Injection Simulator (AWS FIS) を使用してサービスの静的安定性を検証する方法についても説明します。また、FIS、Amazon CloudWatch、Amazon Route 53 Application Recovery Controller (Route 53 ARC) のような AWS のサービスとツールを使用して、Lambda のレジリエンス戦略を実現するソリューションも提供しています。
アベイラビリティーゾーンの役割
アベイラビリティーゾーンは AWS リージョンの物理的に分離された区画で、動作においても障害の発生においても互いに独立するように設計されています。相互に関連する障害を防ぐため、相互に最大 100 km (60マイル) 程度の十分な距離を置いて離れていますが、1 桁ミリ秒の遅延で同期レプリケーションを使用できるほど近い距離にあります。
お客様と AWS サービスは長年にわたりアベイラビリティーゾーンを使用して、可用性が高く、耐障害性があり、スケーラブルなアプリケーションを構築してきました。特に、AWS Lambda、Amazon DynamoDB、Amazon Simple Queue Service (Amazon SQS)、Amazon Simple Storage Service (Amazon S3) などの AWS リージョンサービスは、サービスの複数の独立したレプリカを複数のアベイラビリティーゾーンに分散させることで、高い可用性を実現しています。アベイラビリティーゾーンの独立性と冗長性の原則を使用して、そのサービスの全体的な可用性を最大化します。
各レプリカはゾーンレプリカと呼ばれます。この仕組みは、どのレプリカでもいつでも障害が発生する可能性を考慮して設計されています。レプリカに障害が発生した場合は、すべてが再び期待どおりに動作するまで、そのレプリカをシステムから一時的に削除できます。その場合、負荷は残りのゾーンレプリカ間で分散されます。
障害を想定した設計
AWS でサービスを構築する際に学んだ教訓の 1 つ は、アベイラビリティーゾーンに障害が発生した場合、コントロールプレーンの操作 による復旧に頼らない方が良いということです。例えば、コントロールプレーンの操作とは、障害の影響を受けないアベイラビリティーゾーンでより多くの容量をプロビジョニングすることです。
この原則は静的安定性と呼ばれ、システムが破壊的なイベントにさらされた場合でも、何も変更せずに元の定常状態 (または動作) を維持できることを表しています。静的に安定したサービスは、復旧プロセスにおける依存関係が少なくなります。
これは、AWS Lambda のようなリージョンサービスの場合、正常なアベイラビリティーゾーンの残りの容量が、障害の可能性があるアベイラビリティーゾーンからのトラフィックをスケールアップすることなく吸収できることを意味します。これは、すべてのアベイラビリティーゾーンでリソースを過剰にプロビジョニングすることを意味します。その余分な容量を事前にプロビジョニングしておくと、Lambda は静的安定性を実現できます。これは、リソースを過剰にプロビジョニングするコストと、サービスの可用性の間のトレードオフです。AWS Lambda はお客様に高い可用性を約束し、月間稼働率 を 99.95% とすることを約束しているため、そのトレードオフではサービスの可用性を優先しています。
障害に備える方法
アベイラビリティーゾーンの障害に備えることは困難です。なぜなら、問題の事象や規模は大きく変わる可能性があるからです。アベイラビリティーゾーンには、部分的にアクセス可能な場合もあれば、まったくアクセスできない場合もあります。障害の原因には、ファイバー切断、電源の問題、過熱、ハードウェアの誤動作、ネットワークの問題、容量の問題、およびその他の予期しない状況などがあります。そのような状況は起こりますが、めったに起こりません。障害の最も一般的な種類は、不適切なデプロイや不適切な設定です。
これらの障害の中には、推測や再現が難しいものもありますが、一般的な症状としては、接続の中断、遅延の増加、急増するリトライによるトラフィックの増加、CPU とメモリの使用量の増加、I/O の低下などがあります。
AWS では、予期せぬ事態を想定し、障害に備えることを学びました。つまり、システムに障害を注入してアベイラビリティーゾーンの障害の一般的な症状を再現し、システムがどのように反応するかを観察し、改善を実施することになります。さらに、システムに障害を注入することで、モニタリングやアラートにおける潜在的な盲点を明らかにすることができ、チームが復旧までの時間を短縮することに重点を置いて、イベントへの対応を練習して改善する機会にもなります。
Lambda がアベイラビリティーゾーンの障害への対応をテストする方法
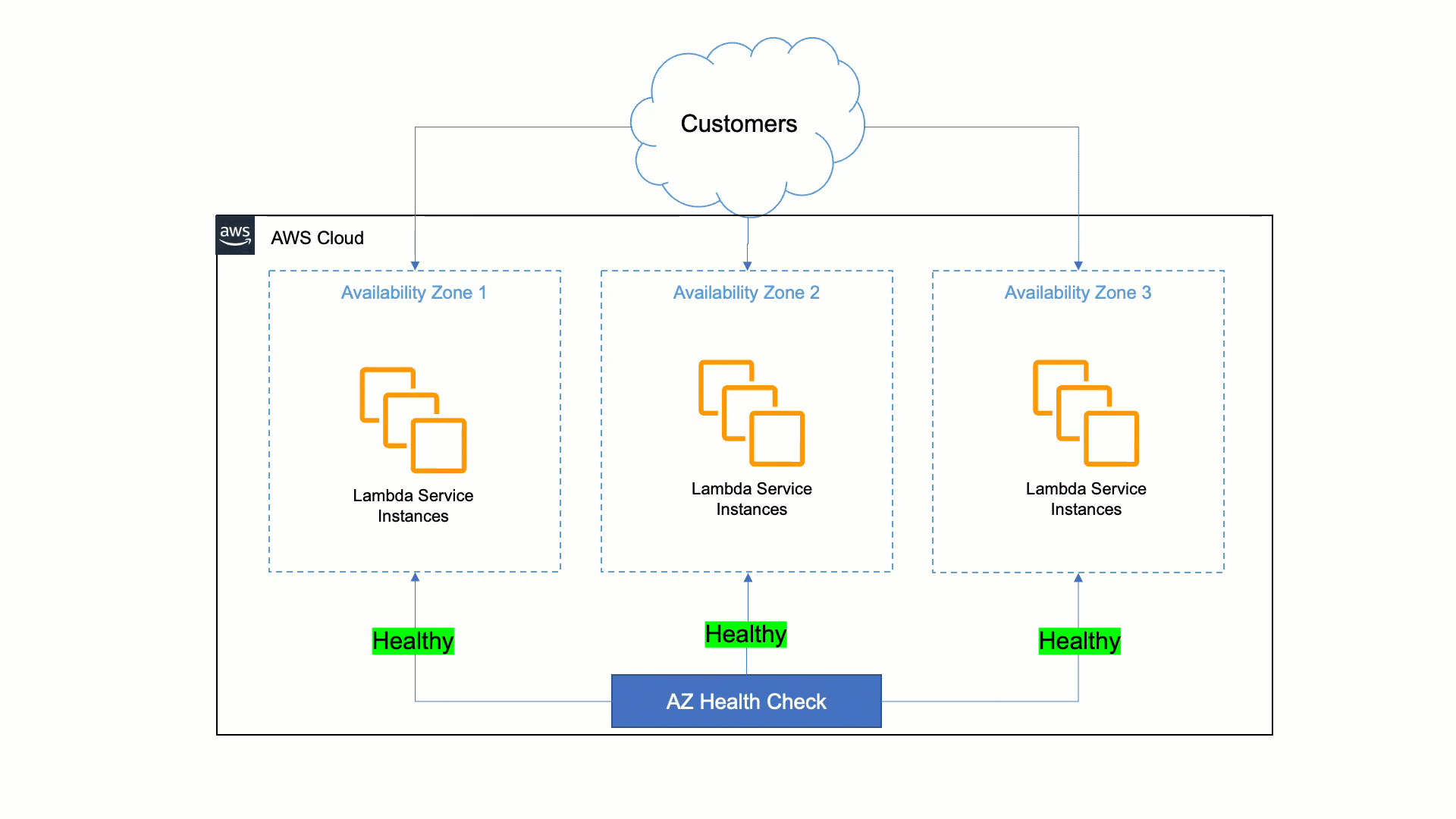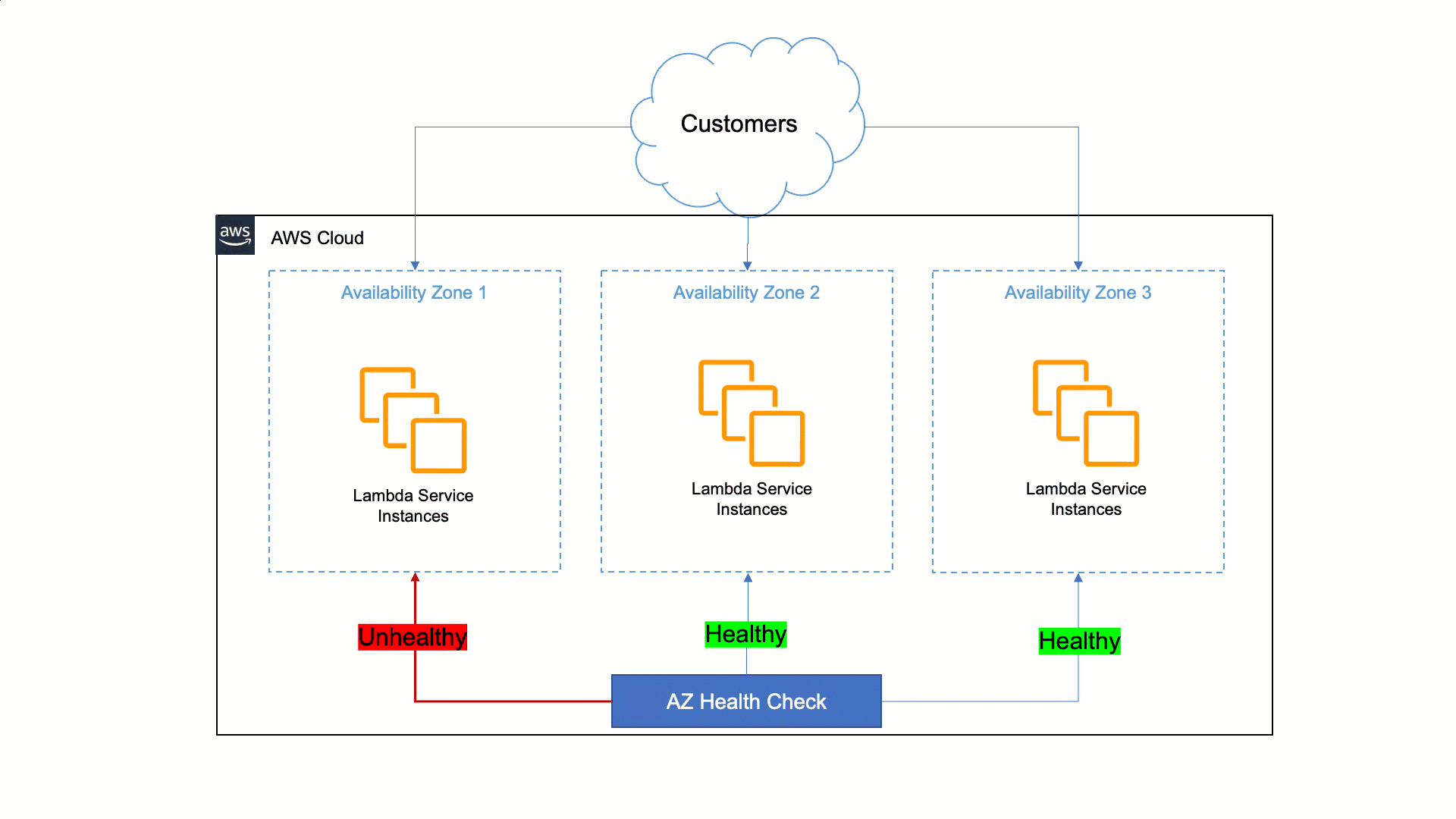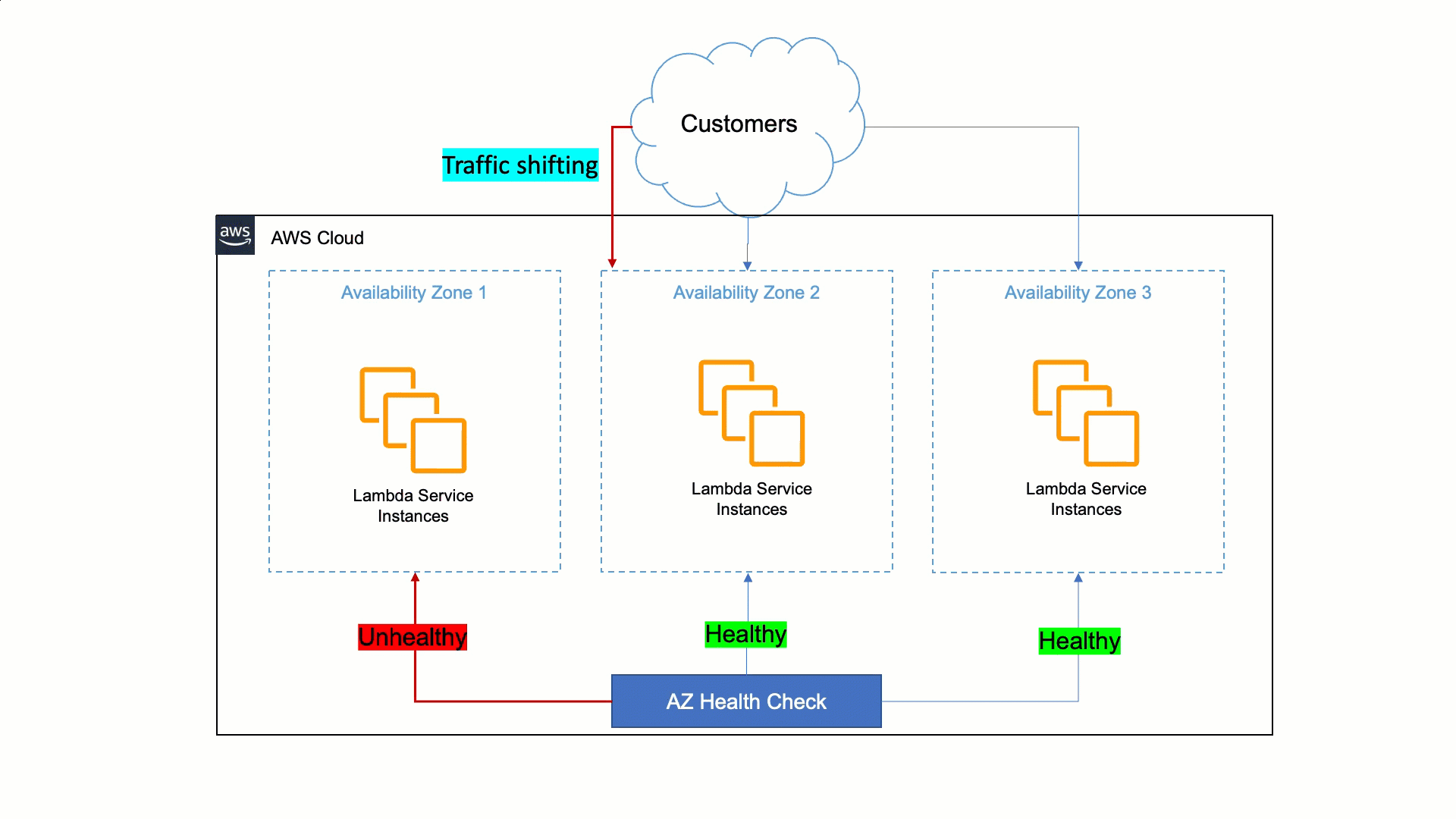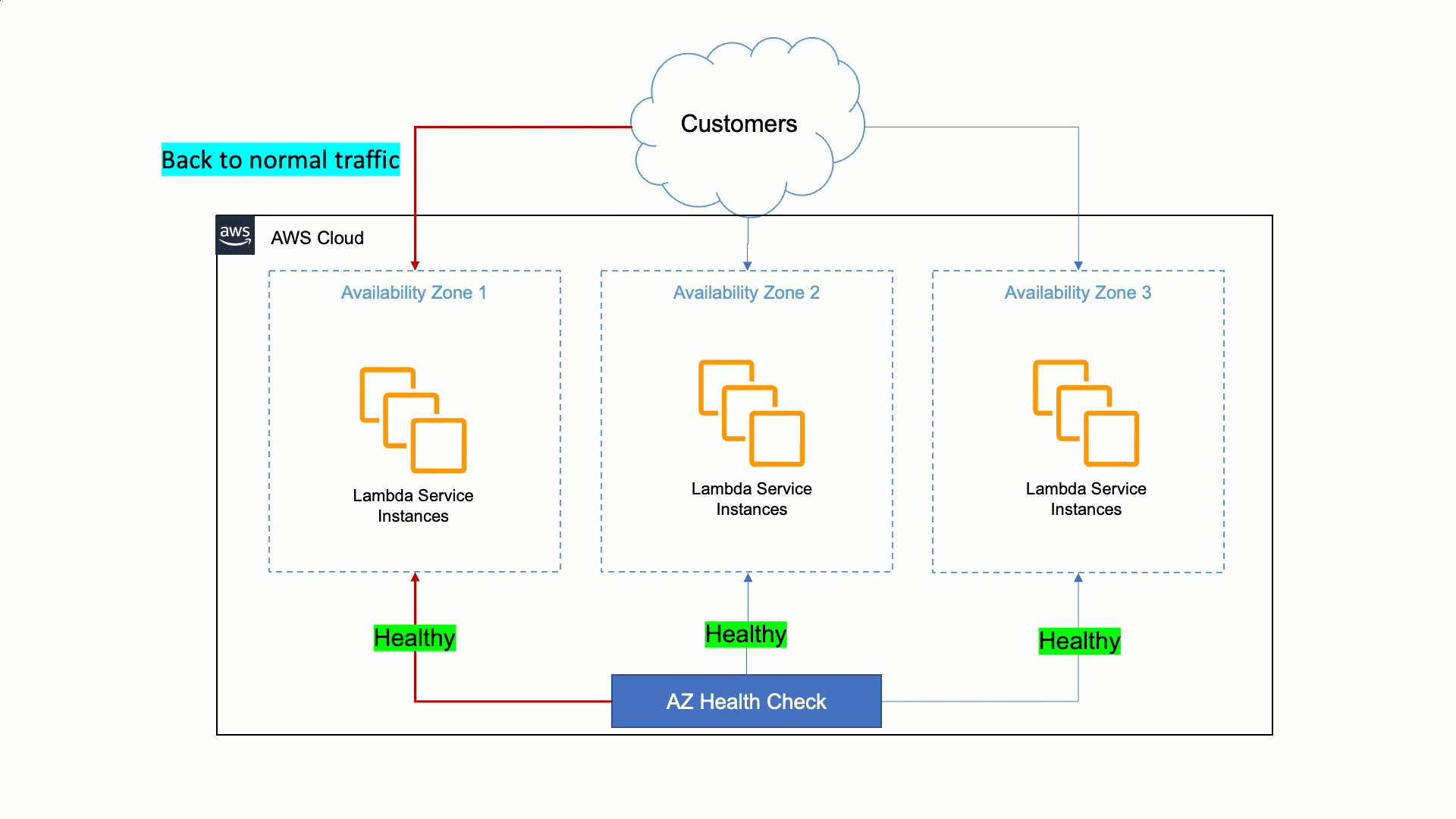
アベイラビリティーゾーンの障害に対するレジリエンスを高めるための Lambda のアプローチは、静的安定性と自動化されたシステムに頼ることです。人間は機械よりも問題の検出と軽減に時間がかかります。そのため、Lambda では、サービスがゾーンレプリカ内の問題を検出し、オペレーターの介入なしに数分以内に自動的に修正できるようにする必要があります。この自動修復は、顧客のトラフィックを、影響を受けるアベイラビリティーゾーンから正常なアベイラビリティーゾーンに移すことで行われ、アベイラビリティーゾーン退避と呼ばれます。
そのために、Lambda は障害を検出し、必要に応じてアベイラビリティーゾーンの退避を実行するツールを構築しました。このツールは、さまざまなアベイラビリティーゾーンと EC2 インスタンス間のメトリクスを統計的に比較して、異常のあるアベイラビリティーゾーンを特定します。アベイラビリティーゾーンに問題があることが判明した場合、ツールは異常のあるアベイラビリティーゾーンからの退避を自動的に開始します。この自動化により、最初のアクションまでの時間が 30 分から 3 分未満に短縮されます。
AWS Lambda が AWS FIS を使用する方法
自動化が期待通りに継続的に機能することを確認するために、Lambda では実稼働前の環境でのアベイラビリティーゾーンの障害テストなど、さまざまなテストを実施しています。これらのテストの主な目的は、アベイラビリティーゾーンに障害が発生してもサービスが静的に安定していることを確認し、アベイラビリティーゾーンからの退避を正常に開始できることを確認することです。自動テストの利点は、チームが定期的にテストを繰り返すことができるため、特別なスキルがなくても済むことです。ワンクリックでテストを開始できます。
これらのテストでは、Lambda は AWS FIS を使用して大規模な EC2 インスタンス群に障害を発生させます。AWS FIS を使用して、AWS System Manager (SSM) エージェントとリソースフィルターとの連携により、特定のアベイラビリティーゾーンにある EC2 インスタンス群をターゲットにします。これは、CPU やメモリの枯渇などのリソース障害や、パケット遅延、損失、ドロップなどのネットワーク障害を挿入できる汎用性の高いアプローチです。
これらの症状はアプリケーションやネットワークのパフォーマンスに重大な影響を与える可能性があるため、パケット損失や遅延を発生させることは非常に重要です。実際、レイテンシーと損失は、たとえ少量であっても非効率性を生み出し、アプリケーションを最高のパフォーマンスで実行できなくなる可能性があります。Lambda にとって、レイテンシーの増加や損失が顧客に影響を与える前に検出できることは非常に重要です。
アベイラビリティーゾーンの障害からアプリケーションを迅速に復旧する方法
Lambda と同様のソリューションを構築して、ゾーン障害からアプリケーションを迅速に回復できます。ソリューションには、障害が発生したアベイラビリティーゾーンから退避させるメカニズム、ゾーンレプリカに障害が発生したことを検出できる監視システム、およびシステムの静的安定性をテストする方法が必要です。AWS は、このソリューションを構築して Lambda のレジリエンス戦略を実現するのに役立つ多くのツールとサービスを提供しています。
アベイラビリティーゾーン退避には、Route 53 ARC の新しいゾーンシフト機能を使用できます。ゾーンシフトにより、Elastic Load Balancing を使用するアプリケーションをアベイラビリティーゾーンから退避させることができます。ゾーンレプリカに障害があるか、異常があることが分かった場合は、問題が修正されるまでの間、ゾーンシフトを使用してアベイラビリティーゾーンから一定期間退避できます。
ゾーンシフトを実行するには、ゾーンレプリカが正常でないことを検出する必要があります。アプリケーションは、アベイラビリティーゾーンごとにヘルスシグナルを提供する必要があります。この信号をキャプチャする一般的な方法は 2 つあります。まず、レスポンスタイムや HTTP ステータスコードなど、アプリケーションの致命的なエラーの追跡に役立つメトリクスを受信してチェックできます。または、能動的にシンセティックモニタリングを使用することもできます。これにより、本番アプリケーションに対して合成リクエストを作成し、顧客体験をより包括的に把握できます。
Amazon CloudWatch Synthetics にはカナリアが用意されています。カナリアはスケジュールに従って実行され、アプリケーションのエンドポイントと API に対して合成リクエストを実行するスクリプトです。カナリアは顧客と同じ行動をとり、顧客体験を継続的に検証します。アプリケーションのゾーンレプリカごとにカナリアを作成し、結果を個別に監視できます。
この情報があれば、いずれかのレプリカで顧客体験が低下した場合でも、ゾーンシフトを使用してアベイラビリティーゾーン退避を開始し、障害の原因を見つけて修正する間、ユーザーへの悪影響を最小限に抑えることができます。
障害から正常に回復できるようにするには、事前にソリューションをテストする必要があります。テストなしでは、これは単なる仮説に過ぎません。アベイラビリティーゾーン内の問題などの破壊的イベントを処理するシステムの能力に関する仮説を証明または反証するには、FIS を使用できます。
FIS を使用すると、アベイラビリティーゾーンなど、同じ障害ドメイン内の複数のリソースに同時に障害を注入できます。FISは現在、EC2、Amazon Elastic Kubernetes Service (Amazon EKS)、 Amazon Elastic Container Service (Amazon ECS)、 Amazon Relational Database Service (Amazon RDS)、AWSネットワーク、CloudWatchなど、いくつかのAWSサービスと統合されています。
アベイラビリティーゾーンの障害に対するワークロードの耐障害性をテストする一般的な使用例としては、特定のアベイラビリティーゾーン内のすべてのコンピューティングリソースとデータベースを停止する、レイテンシーまたはパケットロスを発生させる、特定のアベイラビリティーゾーンのコンピュートリソースのリソース消費量 (CPU、メモリ、I/O) を増やす、アベイラビリティーゾーン内またはアベイラビリティーゾーン間のネットワーク通信に影響を与えるなどがあります。
単一のアベイラビリティーゾーンでアプリケーション障害から迅速に復旧し、AWS FIS でテストする方法の詳細とステップバイステップの例については、このブログ記事をお読みください。
結論
本記事では、静的安定性について解説しました。静的安定性は、Lambda などの AWS サービスがレジリエントなリージョンサービスを構築するために使用するメカニズムです。また、AWS が顧客と同じサービスとインフラストラクチャをどのように活用しているかについても解説しました。Lambda が複数のアベイラビリティーゾーンと AWS FIS などのサービスを使用して可用性の高いサービスを構築し、予期しない障害からの復旧時間を人間の介入なしにわずか数分に短縮する方法を示しました。最後に、お客様のアプリケーションで、Lambda のレジリエンス戦略と同等の内容を実現するためのアプリケーション例も示しました。
AWS FIS の詳細については、多数のチュートリアルとワークショップ をご覧ください。
その他のサーバーレス学習リソースについては、 Serverless Land をご覧ください。
翻訳はソリューションアーキテクトの松本が担当しました。原文はこちらです。