AWS Compute Blog
AWS Lambda: Resilience under-the-hood
This post is written by Adrian Hornsby (Principal System Dev Engineer) and Marcia Villalba (Principal Developer Advocate).
AWS Lambda comprises over 80 services working together to provide the serverless compute service that it offers to customers. Under the hood, many of these services are built on top of Amazon Elastic Compute Cloud (Amazon EC2) instances, provisioned within Availability Zones. However, AWS Lambda is a Regional service. This means that customers use Lambda services from the Region level and its services are designed to be resilient to impairments that the underlying Availability Zones might have.
This blog post discusses how a Regional service such as Lambda takes advantage of Availability Zones and static stability to achieve its high availability target, and shows how Lambda teams verify their service’s static stability using AWS Fault Injection Simulator (AWS FIS). It also provides a solution using AWS services and tools to achieve Lambda’s resiliency strategy, using FIS, Amazon CloudWatch, and Amazon Route 53 Application Recovery Controller (Route 53 ARC).
The role of Availability Zones
Availability Zones are physically isolated sections of an AWS Region, designed to operate but also fail independently. They are separated by a meaningful distance from each other, up to 100 kilometers (60 miles), to prevent correlated failures, but close enough to use synchronous replication with single-digit millisecond latency.
Customers and AWS services have been using Availability Zones for years to build highly available, fault tolerant, and scalable applications. In particular, AWS Regional services such as AWS Lambda, Amazon DynamoDB, Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Storage Service (Amazon S3), have achieved their high availability promises by spreading multiple independent replicas of their services across multiple Availability Zones. It uses the principles of independence and redundancy of Availability Zones to maximize the overall availability of that service.
Each replica is called a zonal replica. The system is designed so that any of the replicas can fail at any time. When a replica fails, it can be temporarily removed from the system until everything works as expected again. When that happens, the load is shared between the remaining zonal replicas.
Designing for failures
One lesson we learned at AWS when building services is when there is an Availability Zone impairment, it is better not to rely on control plane operations to remediate the failure. A control plane operation can, for example, be provisioning more capacity in an Availability Zone that is not affected by the impairment.
This principle is called static stability, and it describes the capability for a system to keep its original steady-state (or behavior) even when subjected to disruptive events without having to make any changes. A statically stable service should have as few dependencies as possible for its recovery process.
For a Regional service like AWS Lambda, this means that the remaining capacity in the healthy Availability Zones can absorb the traffic from a potentially impaired Availability Zone without having to scale up. This implies over-provisioning resources in all Availability Zones. Having that extra capacity pre-provisioned helps Lambda achieve its static stability. It is a tradeoff between the cost of over-provisioning resources and service availability. Since AWS Lambda promises high availability to its customers, with a monthly uptime service commitment of 99.95%, that tradeoff falls towards service availability.
How to prepare for failures
Preparing for an Availability Zone impairment is difficult because the symptoms and size of the impact can vary widely. An Availability Zone may be partially accessible or totally unreachable, and everything in between. Causes for the impairment can range from fiber cuts, power issues, overheating, hardware malfunctions, networking problems, capacity issues, and other unexpected situations. While those happen, they happen rarely. The most common categories of failures are bad deployments and bad configurations.
While some of these failures can be difficult to infer or reproduce, common symptoms include disruption of connectivity, increased latency, increased traffic due to retry storms, increased CPU and memory usage, and slow I/O.
At AWS, we learned to expect the unexpected and plan for failure. This means injecting faults in the system to reproduce some of the common symptoms of Availability Zone impairments, then observe how the system responds, and implement improvements. In addition, injecting faults in the system helps uncover potential monitoring and alarming blind spots, and gives an opportunity for teams to practice and improve their response to events with a focus on reducing time to recovery.
How Lambda tests its response to an Availability Zone impairment
Lambda’s approach to being resilient to Availability Zone impairments is to rely on static stability and automated systems. Humans are slower than machines for detecting issues and mitigating them. Therefore, Lambda must ensure that its services can detect issues within a zonal replica and remediate automatically within minutes and with no operator intervention. This auto-remediation is done by shifting customer traffic away from the affected Availability Zone to healthy ones, and it is called Availability Zone evacuation.
To do this, Lambda built a tool that detects failures and performs the Availability Zone evacuation when needed. This tool does a statistical comparison of metrics between different Availability Zones and EC2 instances in order to identify unhealthy Availability Zones. If an Availability Zone is found to have issues, the tool starts the evacuation out of the unhealthy Availability Zone automatically. This automation cuts the time to the first action from 30 minutes to less than 3 minutes.
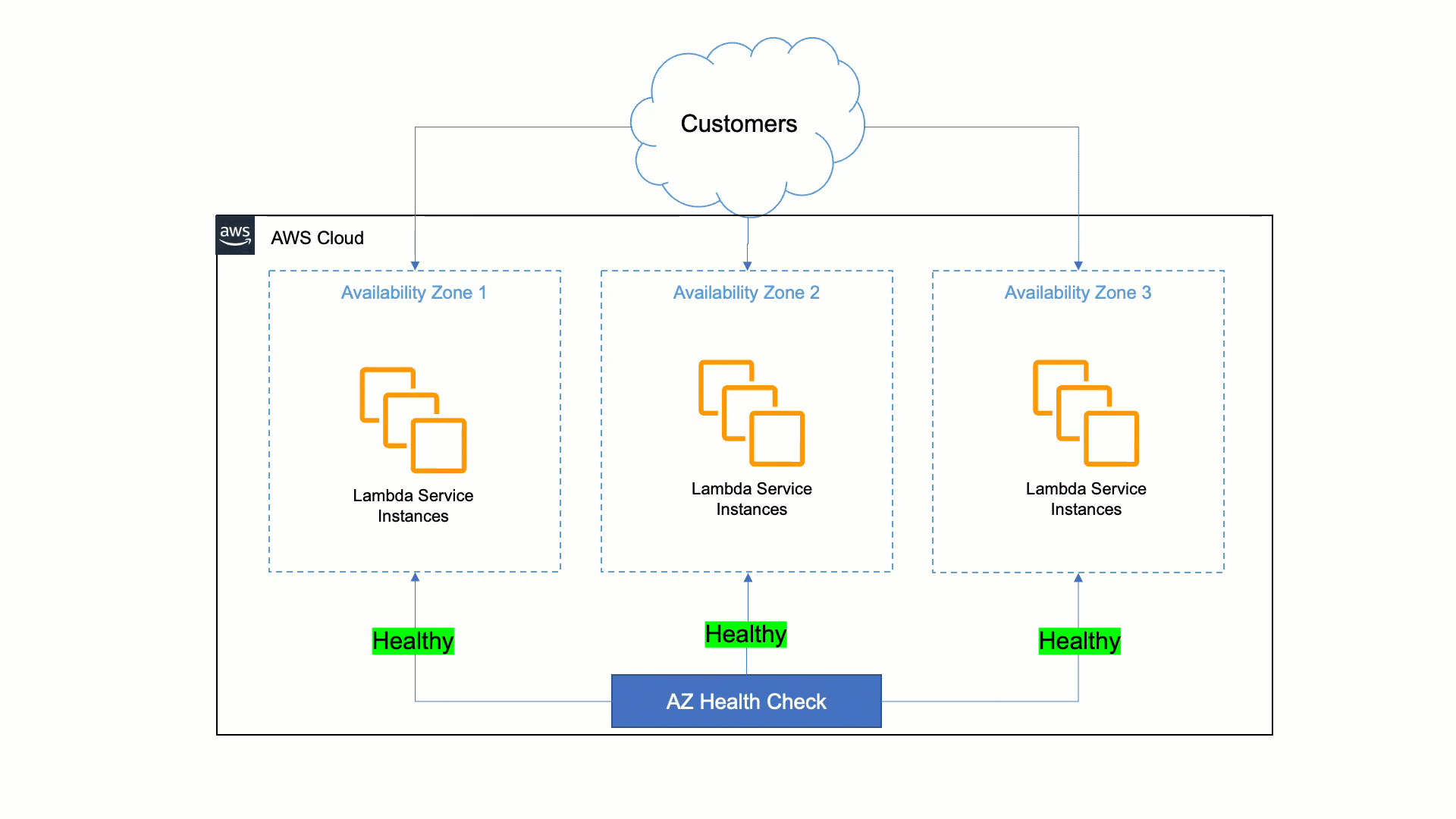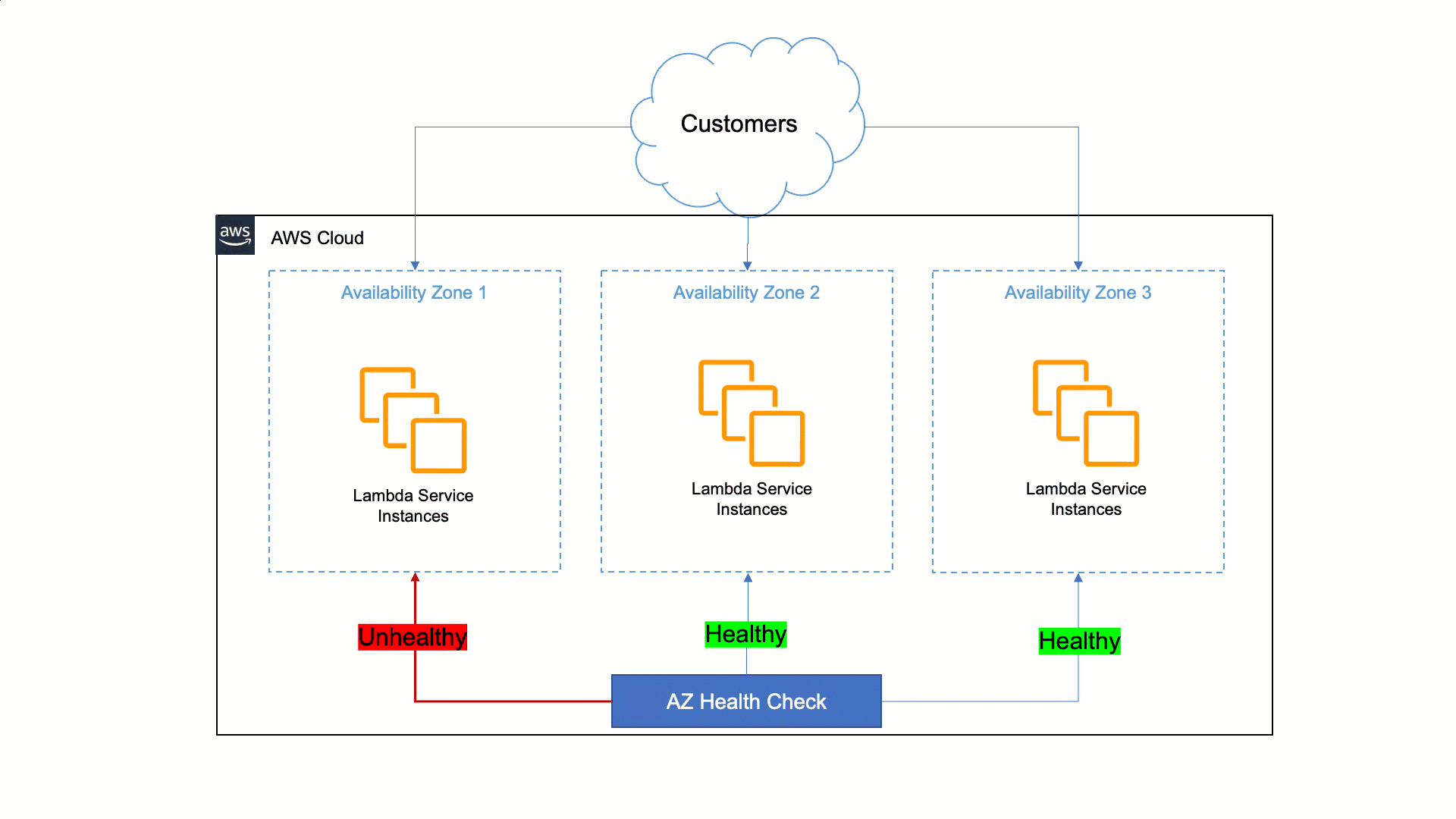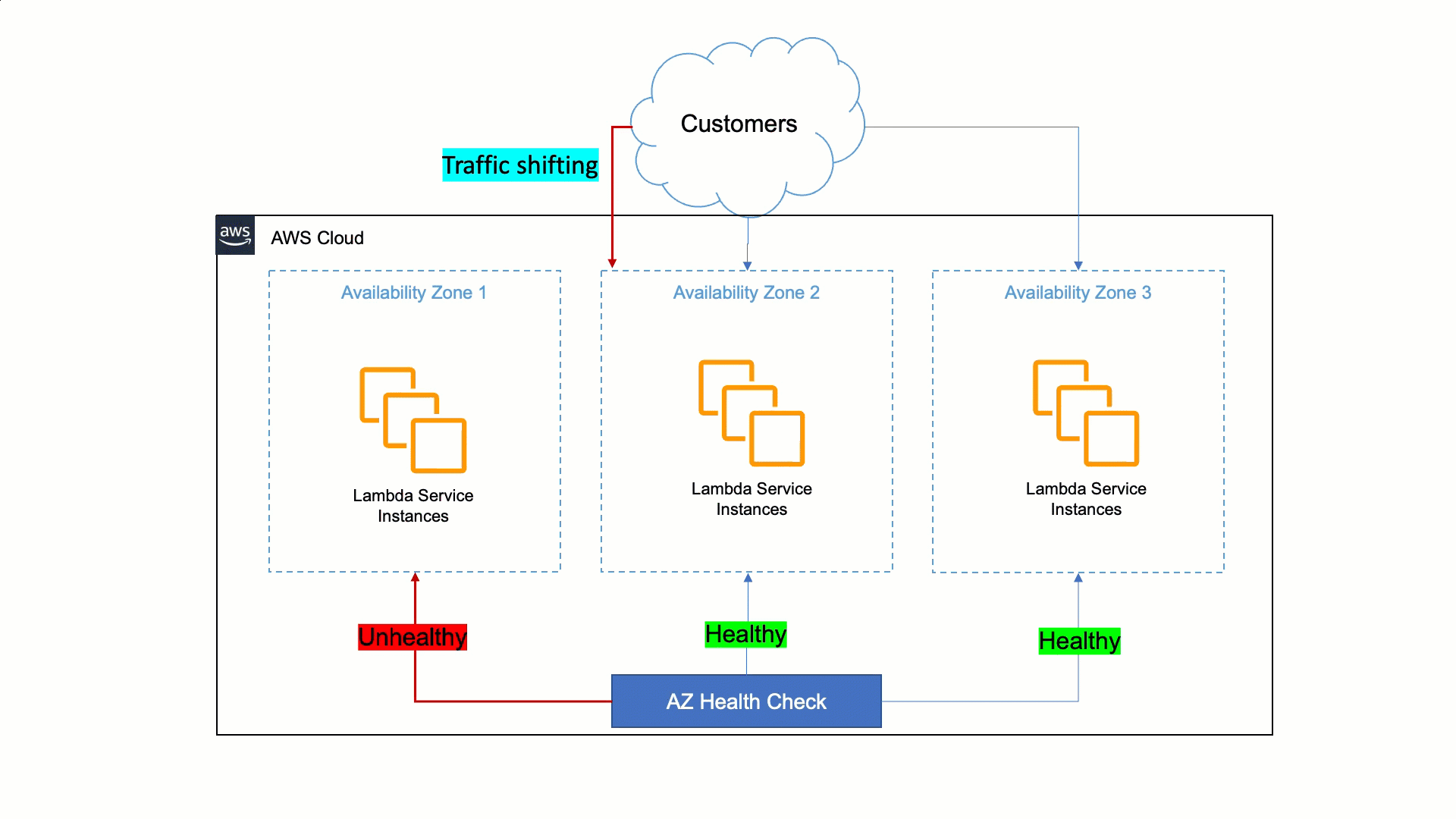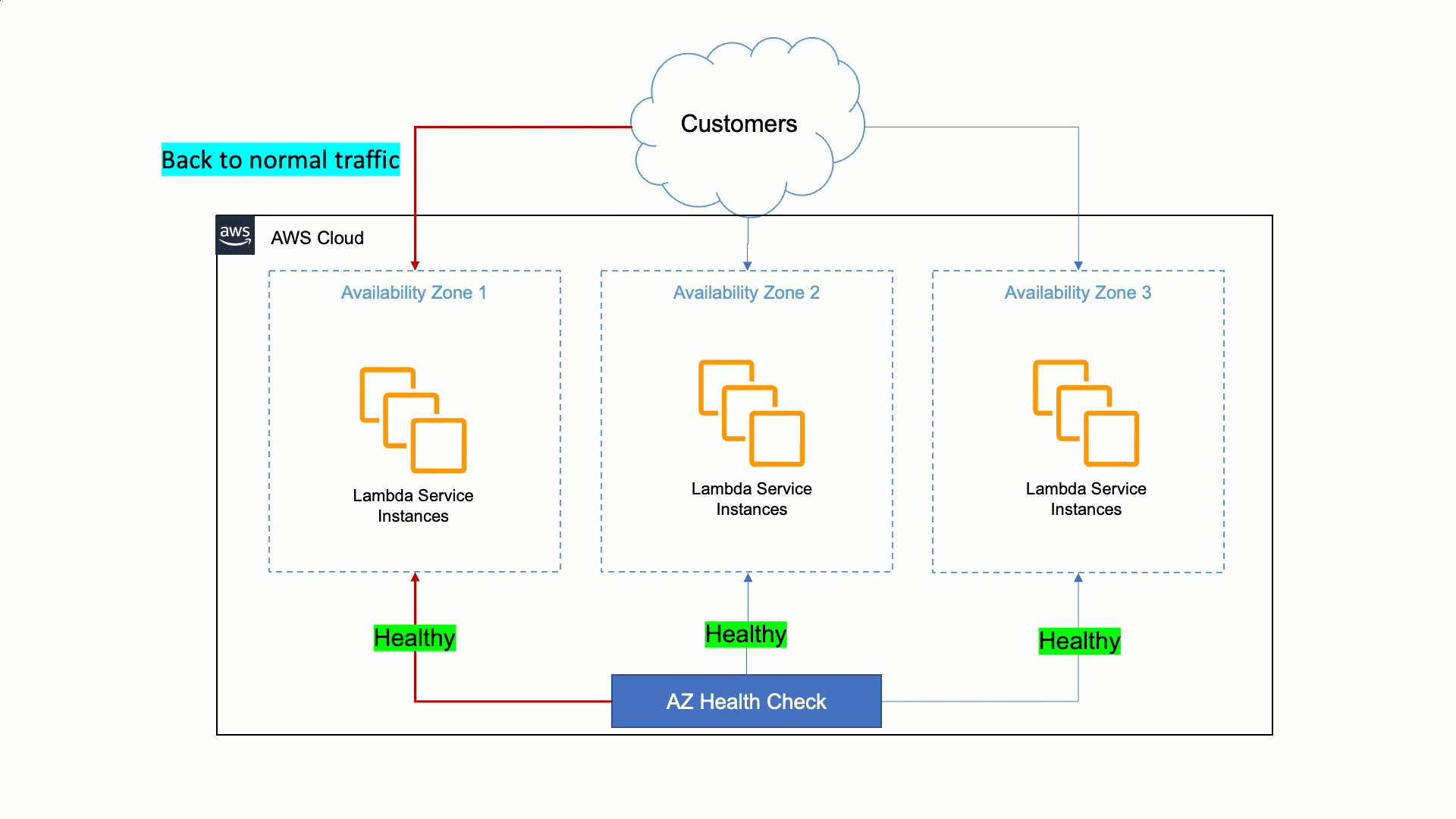
How AWS Lambda uses AWS FIS
To verify the automation continuously works as expected, Lambda performs a wide variety of tests, which includes Availability Zone failure testing in their pre-production environment. The main objective of these tests is to verify the services are statically stable in the presence of Availability Zone impairments, and to verify that the Availability Zone evacuation can be successfully initiated. The benefit of having an automated test is that teams can repeat it regularly and don’t need to have special skills. One click is all it takes to launch the test.
For these tests, Lambda uses AWS FIS to inject faults into their large fleet of EC2 instances. They use AWS FIS with support of the AWS System Manager (SSM) agent and resource filters to target their fleet of EC2 instances in a particular Availability Zone. This is a versatile approach that can inject resource faults, such as CPU and memory exhaustion, and networking faults, such as packet latency, loss, or drop.
Injecting packet loss or latency is very important, since these symptoms can have a serious impact on application and network performance. Indeed, latency and loss, even in small quantities, can create inefficiencies and prevent applications from running at their peak performance. For Lambda, being able to detect increased latency or loss before it affects customers is critical.
How to recover your applications rapidly from Availability Zones failures
You can build a similar solution to rapidly recover your applications from a zonal failure. The solution must have a mechanism to evacuate an impaired Availability Zone, a monitoring system that allows you to detect when a zonal replica is impaired, and a way to test the static stability of your system. AWS provides many tools and services that can help you build this solution to achieve Lambda’s resiliency strategy.
For performing Availability Zone evacuation, you can use the new zonal shift capability from Route 53 ARC, which at the time of writing is in preview. Zonal shift lets you evacuate an Availability Zone for applications that uses Elastic Load Balancing. If you find out that a zonal replica is impaired or unhealthy, you can use zonal shift to evacuate the Availability Zone for a period of time, while the issue gets fixed.
For performing the zonal shift, you must detect when a zonal replica is unhealthy. Your application must provide a signal of its health per Availability Zone. There are two common ways to capture this signal. First, passively, you can check your metrics, like response times, HTTP status codes, and other metrics that can help track fatal errors in your applications. Or actively, using synthetic monitoring, which allows you to create synthetic requests against your production application to provide a more complete view of the customer experience.
Amazon CloudWatch Synthetics provides canaries, which are scripts that run on a schedule and perform synthetic requests in your application endpoints and APIs. Canaries perform the same actions as customers and continuously verify the customer experience. You can create a canary for each zonal replica of your application and monitor the results independently.
With this information, if the user experience diminishes in one of the replicas, you can start an Availability Zone evacuation using zonal shift and minimize the bad experience for the user while you find and fix the sources of the failure.
To ensure that you can successfully recover from a failure, you must test the solution in advance. Without testing, it is just an assumption. To prove or disprove your assumptions about your system’s capability to handle disruptive events such as issues within an Availability Zones, you can use FIS.
With FIS, you can inject faults simultaneously in multiple resources within the same failure domain, such as Availability Zones. FIS currently integrates with several AWS services including EC2, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), Amazon Relational Database Service (Amazon RDS), AWS Networking, and CloudWatch.
Typical use cases for testing a workload’s resilience to Availability Zones impairment are, for example, terminating all compute resources and databases within a particular Availability Zone, injecting latency or packet loss, increasing resource consumption (CPU, memory, and I/O) in compute resources in a particular Availability Zone, or impacting network communication within or between Availability Zones.
For more information and a step-by-step example of how to recover rapidly from application failures in a single Availability Zone and testing it with AWS FIS, read this blog post.
Conclusion
This article discusses static stability, a mechanism that is used by AWS services such as Lambda to build resilient Regional services. It also discusses how AWS takes advantage of the same services and infrastructure as customers. It shows how Lambda uses multiple Availability Zones and services like AWS FIS to build highly available services and improve its recovery time from unexpected failures to only a few minutes without human intervention. Finally, it shows a solution that you can implement for your applications to achieve Lambda’s resilience strategy.
To learn more about AWS FIS, there are many tutorials and a workshop you can check out.
For more serverless learning resources, visit Serverless Land.