Amazon Web Services ブログ
AWSでの疎結合データセットの適合、検索、分析
あなたは刺激的な仮説を思いつきました。そして今、あなたは、それを証明する(あるいは反論する)ためにできるだけ多くのデータを見つけて分析したいと思っています。適用可能な多くのデータセットがありますが、それらは異なる人によって異なる時間に作成され、共通の標準形式に準拠していません。異なるものを意味する変数に対して同じ名前を、同じものを意味する変数に対して異なる名前を使用しています。異なる測定単位と異なるカテゴリを使用しています。あるものは他のものより多くの変数を持っています。そして、それらはすべてデータ品質の問題を抱えています(例えば、日時が間違っている、地理座標が間違っているなど)。
最初に、これらのデータセットを適合させ、同じことを意味する変数を識別し、これらの変数が同じ名前と単位を持つことを確認する方法が必要です。無効なデータでレコードをクリーンアップまたは削除する必要もあります。
データセットが適合したら、データを検索して、興味のあるデータセットを見つける必要があります。それらのすべてにあなたの仮説に関連するレコードがあるわけではありませんので、いくつかの重要な変数に絞り込んでデータセットを絞り込み、十分に一致するレコードが含まれていることを確認する必要があります。
関心のあるデータセットを特定したら、そのデータにカスタム分析を実行して仮説を証明し、美しいビジュアライゼーションを作成して世界と共有することができます。
このブログ記事では、これらの問題を解決する方法を示すサンプルアプリケーションについて説明します。サンプルアプリケーションをインストールすると、次のようになります。
- 異なる3つのデータセットを適合させて索引付けし、検索可能にします。
- 事前分析を行い、関連するデータセットを見つけるために、データセットを検索するための、データ駆動のカスタマイズ可能なUIを提示します。
- Amazon AthenaやAmazon QuickSightとの統合により、カスタム解析やビジュアライゼーションが可能です
データの例
Police Data Initiativeは、警察活動に関連するデータの公開を通じ、コミュニティと法執行機関の関係を改善することを目指しています。 Public Safety Open Data Portalから入手できる参加都市のデータセットには、今説明した問題の多くがあります。 犯罪と場所のメタデータの共通性にもかかわらず、標準的な命名または値の体系はありません。 データセットは、さまざまな場所やさまざまな形式で格納されます。 中央検索エンジンはありません。 このデータから洞察と価値を得るためには、都市別のデータセットを分析する必要があります。
この記事の焦点は警察の事件データですが、IoT、パーソナライズド・メディカル、ニュース、天気、財務など、他のドメインのデータセットに対しても同じアプローチを使用できます。
アーキテクチャ
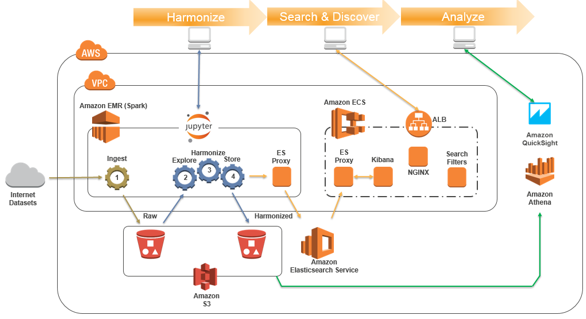
私たちのアーキテクチャは、以下のAWSサービスを使用します。
- Amazon EMR(Apache SparkとJupyterノートブック付)は、疎結合の複数のデータセットを探索、クリーニング、適合(変換)、記述、保存することができます。
- Amazon S3は、生データセットと適合データセットの両方を格納します。
- Amazon Elasticsearch Service(Amazon ES)は、選択したデータセット変数の安全で検索可能なインデックスと、検索Webページで検索を可能にする関連する辞書/メタデータをホストします。
- Amazon EC2 Container Service(ECS):Webベースの検索UIをホストします。
- Amazon AthenaおよびAmazon QuickSightを使用して分析およびレポートを提供します。
- AWS CodeBuildとAWS CodePipelineを使用して、ECS上で検索UIアプリケーションを構築して提供します。
- AWS Identity and Access Management(IAM)ポリシーとインスタンスの役割により、UIコンテナーやEMRクラスターからのAmazon ESへのアクセスが最小限に抑えられます。
- AWS CloudFormationは、環境のプロビジョニングを調整します。
次の図は、ソリューションアーキテクチャを示しています。
サンプルソリューションのインストールと構成
このCloudFormationボタンを使用して、サンプルアプリケーションの独自のコピーをAWSリージョンus-east-1で起動します。
![]()
ソースコードはGitHubリポジトリから利用できます。
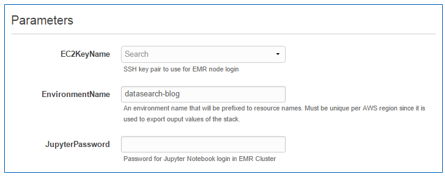
新しいEMRクラスター上のJupyterノートブックにアクセスする際に使用するEC2キーペアとパスワードを入力します。 (EC2コンソールでキーペアを作成できます)。
マスターCloudFormationスタックは、複数のネストされたスタックを使用して、AWSアカウントに以下のリソースを作成します。
- 2つのアベイラビリティゾーンにあるパブリックサブネットとプライベートサブネットを持つVPC。
- インデックスを保存して検索クエリを処理するためのAmazon ESドメイン(2 x t2.smallマスターノード、2 x t2.smallデータノード)費用約$0.12/hr。
- データセットとEMRログを格納するためのS3バケット。
- Elasticsearch Serviceリクエストに署名するためのaws-es-kibanaプロキシサーバ(santthosh提供)と、Apache Spark、Jupyterノートブックを使用するためのEMRクラスタ(1 x m4.2xlargeマスターノード、2 x m4.2xlargeコアノード)費用約$1.80/hr。
- ECSクラスタ(2 x t2.largeノード)、検索を実行してWebサービスコンテナを検出し、aws-es-kibanaプロキシサーバがAmazon ESリクエストに署名するタスク。費用約$0.20/hr。
- ECSおよびEMRインスタンスで使用されるインスタンスロールに最小権限を適用するポリシーを持つIAMロール。
これらのリソースを実行中の間、課金されます。 us-east-1リージョンでは、1時間に2ドルを少し上回ると予想しています。
EMRクラスタは、計算コストの最も重要な要因です。適合のためにのみ使用されるため、データセットを適合させた後は、EMRクラスタを終了することができます。後で新しいデータを適合させる必要があるときに、新しいクラスタを作成することができます。
CloudFormationがリソースを設定するには30〜60分かかります。 CREATE_COMPLETEがメインスタックのStatus列に表示されたら、スタックのOutputsタブを調べます。ここでは、適合のためのJupyterノートブックとデータセット検索ページのUIにアクセスするために必要なリンクが表示されます。

サンプルデータセットを適合させる
-
- Outputsタブに表示されているJupyterURLを使ってJupyter Notebook UIを起動します。
- スタックを起動したときに使用したパスワードを入力します。
- datasearch-blogフォルダを開きます。
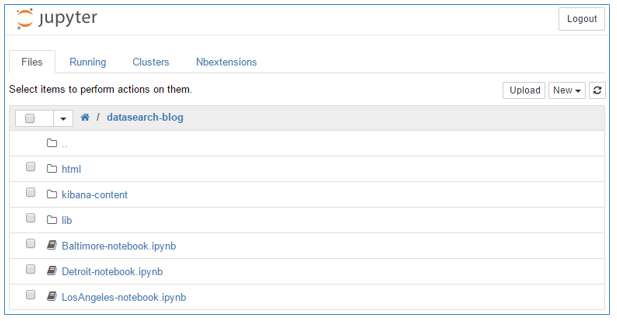
サンプルアプリケーションを説明するために使用する3つの都市(Baltimore、Detroit、Los Angeles)の適合用のノートブックが表示されます。 libフォルダには、適合用のノートブックで使用される共通の索引付け方法と適合方法を抽象化するために使用されるPythonクラスが含まれています。 htmlフォルダには、ノートブックの実行中に作成および公開される各ノートブックの読み取り専用HTMLコピーが含まれています。 kibana-contentフォルダには、デフォルトの検索ダッシュボードペインの定義と、ダッシュボードをAmazon Elasticsearch Serviceとの間でインポートおよびエクスポートするためのスクリプトが格納されています。
これで、適合用のノートブックを実行する準備が整いました。
-
- Baltimore-notebook.ipynbをクリックして、Baltimoreノートブックを開きます。異なるデータセットを使用するようにサンプルを変更するか、追加機能を実装するには、これらのファイルの仕組みを理解する必要があります。今回は、3つのサンプルノートブックを実行して、一部のデータセットをダウンロードして適合させます。
Show/Hide Codeを使用して、Pythonコードを含むセルの表示を切り替えることができます。
-
- Cellメニューから、Run Allを選択してノートブックを実行します。
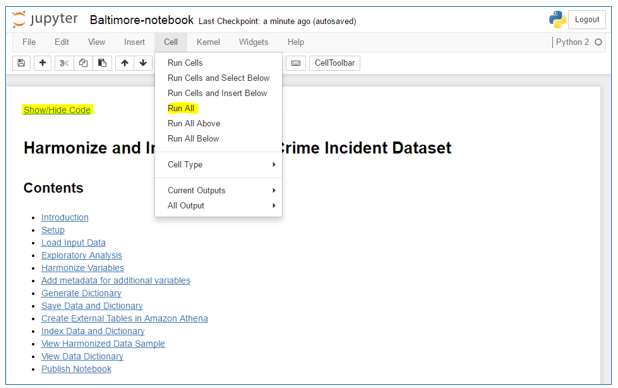
ノートブックのセルを監視することで実行の進行状況を確認できます。 各セルの実行が完了すると、セルの下に出力が表示されます。 ノートブックの実行完了メッセージがノートブックの一番下に表示されます。

この時点で、Baltimoreのデータセットがダウンロードされ、S3に保存されています。 データが適合し、辞書が生成されました。 データセットと辞書は、Elasticsearchインデックスに格納されて検索ページでの検索を可能にし、S3で後で詳細な分析を容易にしました。
-
- ノートブックのセクションをスクロールし、埋め込みドキュメントを読み、それが何をしているのかを理解してください。 サンプルコードはPySparkモジュールを使用してPythonで記述され、基盤となるEMRクラスタ上で動作するApache Sparkの能力を活用します。
PySparkを使用すると、大規模なデータセットを処理するための手法を簡単に拡張できます。 Tom Zengの優れたブログ記事、Run Jupyter Notebook and JupyterHub on Amazon EMRで説明されているように、R、Scalaなどの言語もサポートされています。
- サンプルのデータセットの適合プロセスを完了するには、他の2つの市のノートブック、Detroit-notebook.ipynbとLosAngeles-notebook.ipynbを開いて実行します。
注:サンプルの適合用のノートブックを、アプリケーションをインストールせずに調べたい場合は、ここで、Baltimore-notebook、Detroit-notebook、LosAngeles-notebookをブラウズできます。
検索と発見
警察の事件データセットがAmazon Elasticsearch Serviceに統合され、索引付けされたので、ソリューションの検索および検出UIを使用して、結合されたデータの完全なセットを可視化して調べることができます。
ページレイアウト
CloudFormationスタックのOutputsタブのSearchPageURLを使用して検索UIを起動します。
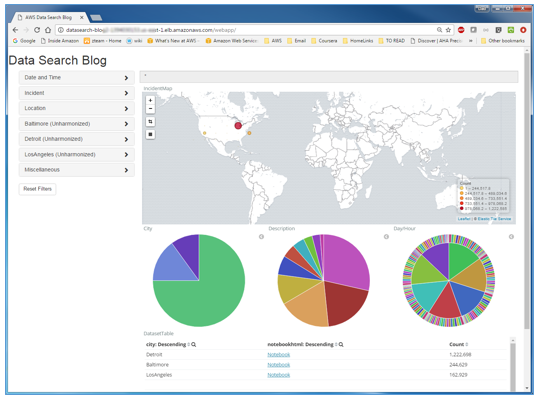
検索ページには2つのコンポーネントがあります。
- 埋め込まれたKibanaダッシュボードを使用すると、フィルタを適用する際にデータセットから集計情報を可視化できます。
- サンプルダッシュボードは、適合した警察の事件データセット用に設計されていますが、独自のダッシュボードを簡単に実装して置き換えることで、別のデータセットや変数をサポートするためのまた別の可視化を提供できます。
- ダッシュボード要素と対話して、マップビューを拡大し、ビジュアライゼーションから地理的領域または値を選択してフィルタを適用することができます。
- アコーディオン要素を含むフィルタサイドバーには、フィルタをダッシュボードに適用するために使用できる変数のグループが表示されます。
- フィルタサイドバーは、Amazon Elasticsearch Serviceで適合プロセスによって索引付けされたディクショナリメタデータから動的に構築されます。
- Jupyterを使用してlib/harmonizeCrimeIncidents.pyファイルを調べて、各適合された変数が、関連する変数をUIのアコーディオンフォルダにグループ化するために使用されるvargroupにどのように関連付けられているかを確認します。明示的に割り当てられていない変数は、デフォルトのvargroupに暗黙的に割り当てられます。例えば、Baltimore(Unharmonized)と表記されたアコーディオンは、Baltimoreデータセットのデフォルトグループです。元のデータセット変数が含まれています。
フィルタサイドバーコンポーネント
フィルタサイドバーコードは、辞書メタデータに基づいて各変数に使用するUIコンポーネントタイプを動的に選択します。 lib/harmonizeCrimeIncidents.pyのコードをもう一度見ると、各適合変数にUIコンポーネントタイプを決定するタイプが割り当てられていることがわかります。適合コードによって明示的に型指定されていない変数には、データセット辞書の作成時(変数に文字列または数値が含まれているかどうかに基づいて)および値の分布に暗黙的に割り当てられます。
フィルタサイドバーで、Date and Timeのアコーディオンを開きます。datetimeチェックボックスを選択し、FromまたはToフィールドをクリックして、日付/時刻カレンダーコンポーネントを開きます。
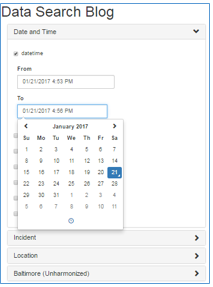
dayofweekのチェックボックスをオンにすると、複数の値のピックリストが表示されます。

その他の変数タイプは次のとおりです。
範囲:

ブール値:

テキスト(タイピングに応じた自動サジェスト付き):

フィルターを試してみてください。フィルタを適用したり削除したりすると、ダッシュボードビューは動的に更新されます。 各データセットに表示される数は、フィルタ条件に一致するレコードの数に応じて変更されます。 現在のフィルタの概要が、ダッシュボードの上部にあるクエリバーに表示されます。
データセットドキュメント/透明性
ダッシュボードの例では、各データセットのNotebookリンクを提供しています。

BaltimoreのNotebookリンクをクリックして、Baltimoreノートブックの読み取り専用コピーを表示するブラウザタブを開きます。 目次に記載されているセクションを調べます。
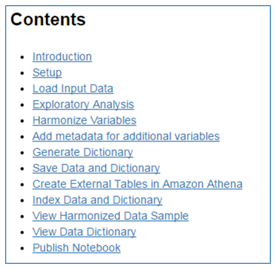
このメカニズムを使用して、データセットを文書化し、データセット文書、適合コード、および出力を1つのアクセス可能な成果物にカプセル化することにより、透過性と再現性を提供します。
検索の例
あなたの仮説が、2007〜2015年の週末に発生した殺人事件に特に関連しているとしましょう。
dayofweek、year、およびdescriptionに検索フィルタを適用するには、検索UIを使用します。

あなたは、Detroitがあなたの基準に合致した事件の数が最も多いことがわかります。Baltimoreにも一致するレコードがいくつかあるので、それら2つのデータセットを絞り込むことができます。
分析する
検索UIを使用してデータセットを検索した後は、さらに検討して、貴重な分析やカスタムビジュアライゼーションを作成して仮説を立証し、提示する必要があります。
あなたの分析に使用できるツールはたくさんあります。
1つの選択肢は、Kibanaを使用して新しい仮説、可視化、およびダッシュボードを構築し、仮説を支持するデータパターンおよび傾向を示すことです。
あるいは、あなたの研究用の新しいJupyterノートブックを作成し、PythonまたはRの知識を活用して、S3に格納された適合したデータセットの深い統計的および予測的分析を行う適合(Jupyter on EMR/Spark)環境を再利用することもできます。 matplotlibやggplot2のようなライブラリを使用して見事なインライン可視化を生成し、文書やコードを含む美しいノートブックを作成することもできます。
最近発表された2つのAWS分析サービスであるAmazon AthenaとAmazon QuickSightは、多くの研究や分析タスクに魅力的でサーバレスなオプションを提供します。これらのサービスを使って、例の警察の事件データを分析する方法を探してみましょう。
Amazon Athena
us-east-1リージョンのAmazon Athenaコンソールを開きます。 DATABASEからincidentsを選択します。データセット用のテーブルがAthenaカタログに既にロードされていることがわかります。これらのテーブルのプレビューアイコンを選択して、いくつかのレコードを表示します。

データセットのテーブルはどのようにAthenaカタログにロードされましたか? 適合用のノートブックを調べた場合、その答えを知ることができます。 私たちのサンプル適合ノートブックは、適合したデータセットと辞書をS3にパーケットファイルとして保存し、AthenaのJDBCドライバ(例)を使用してAmazon Athenaサービスでこれらのデータセットを外部テーブルとして登録します。
Amazon QuickSight
Amazon QuickSightはAthenaをデータソースとして使用して、美しいインタラクティブなビジュアライゼーションを構築できます。 これをするためには:
-
- QuickSightコンソールを開いてサインインします。 クイックサイトを初めて使用する場合は、アカウントを作成してください。
注:QuickSightアカウントには、Amazon Athenaと適合したデータセットが格納されているS3バケットにアクセスするためのアクセス許可が必要です。
-
- コンソールの手順に従って、Athenaデータソースを作成します。
- データソースを作成したら、インシデントデータベースを選択し、Edit/Preview dataを選択します。

-
- 個別の適合都市データセットを単一のデータセットに結合して分析するためのカスタムクエリを作成します。 Tablesアコーディオンを開き、Switch to Custom SQL toolをクリックします。

-
- 次の例では、3つのサンプル・データセットの適合変数datetime、cityおよびdescriptionを結合しています。

-
- データのプレビューを確認し、分析ラベルを変更して、Save and Visualizeを選択してデータセットを保存し、ビジュアライゼーションエディタを開きます。

-
- インシデントの説明ごとにインシデント数を時間とともに表示するデフォルトのビジュアライゼーションを表示するには、datetimeとdescriptionを選択します。

ビジュアライゼーション、ストーリー、ダッシュボードを作成して、QuickSightの機能を調べてください。チュートリアルとサンプルは、QuickSight UIやその他のブログ記事で見つけることができます。
カスタマイズ
この記事と付属のサンプルアプリケーションは、概念を説明し、カスタマイズ可能なフレームワークを提供することを目的としています。
コード・リポジトリと継続的なビルドとデプロイ
サンプルソリューションでは、AWS CodePipelineにアカウントのパイプラインがインストールされます。パイプラインは、aws-big-data-blogというS3バケット(s3://aws-bigdata-blog/artifacts/harmonize-search-analyze/src.zip)のソースコードアーカイブを監視します。このソースアーカイブを変更すると、AWS CodePipelineが自動的にアカウントのUI Webアプリケーションを再構築して再デプロイします。
私たちのGitHubリポジトリをフォークし、README.mdファイルを参照して、ソリューションテンプレートとソースコードを作成して独自のS3アーティファクトバケットを公開する方法を学んでください。
CloudFormationを使用して、新しいS3バケットからソリューションマスタースタックを起動し、パイプラインがバケットのソースコードアーカイブを監視することを確認します。
ソリューションのカスタマイズを開始する準備が整いました。
適合をカスタマイズする
これらの例を参考にして、独自のJupyterノートブックを作成して、独自のデータセットを適合させ、索引付けしてください。私たちのサンプルノートブックとPythonクラスには、変更を加えたときにあなたを導くための埋め込みノートとコメントが含まれています。適合プロセスを使用して以下を制御します。
- 変数名
- 変数値、カテゴリ、測定単位
- 検索可能なデータセットタグを作成するための新しい変数
- データを充実させる新しい変数
- データ品質チェックとフィルタ・補正
- 索引付けされ、検索可能にされる変数のサブセット
- 変数がグループ化されて検索UIに表示される仕組み
- 変数を記述し、データ系統を保存するために使用されるデータ・ディクショナリ
- データセット文書、検索UIからの公開およびアクセス可能
検索UIのカスタマイズ
Web検索UIダッシュボードをカスタマイズして、自分のデータセットの変数を反映させ、ダッシュボードページを自分のWebサイトに埋め込み/リンクします。
メインの検索ページパネルは、組み込みのKibanaダッシュボードです。 Kibanaを使用してカスタマイズしたダッシュボードを作成できます。このダッシュボードは、./services/webapp/src/config.jsを編集してdashboardEmbedUrlの値を置き換えて検索ページにリンクすることができます。
フィルタサイドバーは、ブートストラップJavascriptアプリケーションです。適合をする時にAmazon Elasticsearch Serviceに保存されたデータセット辞書インデックスから完全にデータ駆動されるため、新しいデータセットまたは変数を処理するためにサイドバーコードを変更する必要はありません。
Web UIを構築してテストする方法の詳細については、GitHubリポジトリのREADME.mdファイルを参照してください。
他のAWSサービスとの統合
最近発表されたData Lake Solution on AWSを使用して、S3でデータセットを整理して管理するためのデータレイクを作成することを検討してください。 APIを使用して、適合したデータセットを登録および追跡することができます。ソリューションのコンソールを使用して、データセットのライフサイクルとアクセス制御を管理できます。
Amazon CloudWatch(ログ、メトリック、アラーム)を使用して、Web UIコンテナログ、ECSクラスタ、Elasticsearchドメイン、およびEMRクラスタを監視します。
適合したデータセットをAmazon Redshiftデータウェアハウスに保存したり、Amazon Machine Learningを使用して適合変数に関する予測分析を実行したりすることもできます。ぜひ新しい可能性を探ってください!
掃除
リソースが稼動している間は1時間ごとの料金が請求されるので、完了したらリソースを削除することを忘れないでください!
- マスターdatasearch-blog CloudFormationスタックを削除する。
- S3コンソールを使用してS3バケット、datasearch-blog-jupytersparkを削除する。
- Athenaコンソールを使用してインシデントデータベースを手動で削除する。
- 最後に、QuickSightコンソールを使用して、これらのデータセットを分析するために作成したデータソースとビジュアライゼーションを削除する。
まとめ
このブログ記事では、AWSサービスを活用して、複数の疎結合のデータセットにまたがって検索と分析を統合するという課題の多くに取り組むアプローチについて説明しました。我々は、簡易な仮説検証に使用できるサンプルアプリケーションを提供しました。独自のニーズに合わせてアプローチをカスタマイズしてみてください。
ご質問やご提案がありましたら、コメントにご意見をお寄せください。私たちは皆様からのお声を心待ちにしております!
原文:Harmonize, Search, and Analyze Loosely Coupled Datasets on AWS(翻訳:半場 光晴)