Amazon Web Services ブログ
AWS DataSync をスケールアウトしてデータ転送を高速化する方法
このブログは 2023 年 7 月 6 日に Darryl Diosomito (シニアソリューションアーキテクト) によって執筆された内容を日本語化したものです。原文はこちらを参照してください。
データセンターの設置するスペースや、光熱費の増加、ハードウェアの更新サイクルを意識せずに、ストレージ容量を増やしたいという要求に悩んだことはありませんか?お客様は、オンプレミスや他クラウドサービスのストレージにて、容量を自由に確保したいとしばしば考えています。これは、アーカイブ用途やクラウドコンピューティングにて利用するデータ、あるいはその両方であっても構いません。オンラインデータ移行の際に利用できる通信帯域に制限があるお客様は、スクリプトの作成と保守への投資を避けたいかもしれません。また移行の際に、データを検証する方法やネットワークを効率的に利用する方法を探していることもあります。
AWS DataSync は、大規模なデータ転送プロジェクトを支援する AWS サービスです。AWS DataSync は、オンプレミスのストレージ、エッジロケーション、他のクラウドサービスと AWS ストレージサービス間、および AWS ストレージサービス同士における、ファイルやオブジェクトデータの移動を可能にします。
このブログでは、AWS DataSync を用いてデータ転送をスケールアウトさせる方法について説明します。これにより、利用可能なネットワーク帯域幅を最大限に活用することでより高いデータスループットを実現し、移行スケジュールを短縮することができます。データセットのほとんどが小さいファイルで構成されている場合、ファイル数が数百万に達する場合、単一の DataSync タスクでは消費し切れないほどの広いネットワーク帯域幅がある場合は、データ転送をスケールアウトすることも検討が必要です。
ビルディングブロックによるスケールの開始
オンプレミスのデータ転送では、ハイパーバイザー環境にデプロイしローカルストレージシステムに接続する DataSync エージェントを利用します。AWS DataSync は DataSync エージェントを利用して、データ移行をオーケストレーションします。オンプレミスのデータは、Amazon Simple Storage Service (Amazon S3)、Amazon Elastic File System (Amazon EFS)、およびサポートしている Amazon FSx ファイルシステムに転送できます。DataSync エージェントは一度に 1 つのタスクを実行でき、DataSync エージェントが 64 GB の RAM で構成されている場合、タスク毎に最大 5000 万ファイルとディレクトリを転送できます。
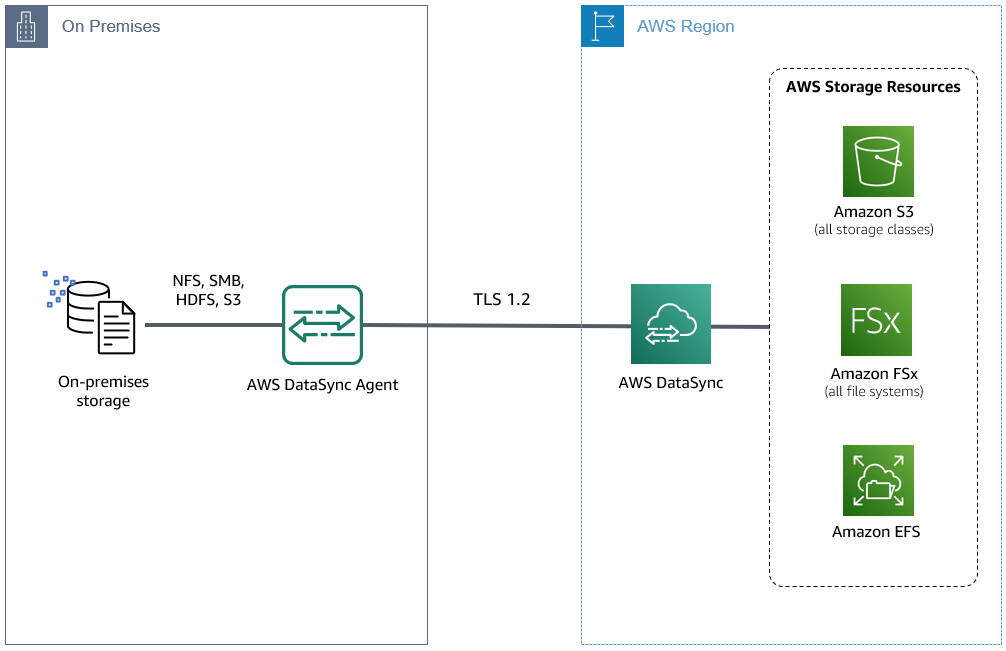
図 1: 1 つの DataSync エージェントをオンプレミスにデプロイ
AWS ストレージサービス間のデータ転送では、サービスによって処理されるため、DataSync エージェントは不要です。
![]()
図 2: AWS DataSync によるエージェントレスなデータ移行
DataSync ロケーションはデータ移行の転送元、もしくは転送先を示します。ロケーションの種類には、NAS サーバー (NFS、SMB)、Hadoop クラスター (HDFS)、自己管理のオブジェクトストレージ、その他クラウドサービス、AWS ストレージサービスなどがあります。NAS サーバー (NFS、SMB)、Hadoop クラスター (HDFS)、オブジェクトストレージをロケーションとして設定する場合は、DataSync エージェントが必要になります。
データは手動、もしくはスケジュールに従って実行される DataSync タスクによって転送されます。タスクは転送元や転送先ロケーションに加えて、データ転送に関する様々なオプション設定で構成されています。タスクは転送元から全てのデータを送信するだけでなく、include/exclude フィルターを設定して必要なデータのみを送信することもできます。
アーカイブ用途等でデータが変更されないユースケースでは、1 回のタスク実行だけでデータセット全体を転送できます。転送元でデータが頻繁に変更されるシナリオでは、タスクを複数回実行しても AWS DataSync は変更されたデータのみを転送します。タスクをスケジューリングにより定期的に実行することで、カットオーバーの準備が整うまで転送先を最新の状態に保てます。
DataSync エージェント、DataSync ロケーション、および DataSync タスクは、AWS DataSync を使用したデータ転送の構成要素です。これらのコンポーネントは、データ転送を高速化するスケーラブルなアーキテクチャを実現します。スケールアウトを実現するには、異なる転送元から複数のタスクを同時に実行します。
DataSync タスクの詳細
DataSync タスクは、起動、準備、転送、および検証の各フェーズを経て進みます。タスクが開始されると、データ転送を調整するために、AWS DataSync を初期化する起動フェーズに入ります。次に、タスクは準備フェーズに進みます。準備フェーズは主にメタデータ操作で構成され、転送元と転送先のロケーションをスキャンして、どのデータを転送する必要があるのか判断します。転送するデータセットのファイル数によっては、準備フェーズにて転送インベントリを構成するのに数分から数時間かかります。その後は、転送元ロケーションから転送先ロケーションへデータをコピーする転送フェーズに進みます。そして最後に検証フェーズです。選択した検証オプションに応じて、転送されたデータのみを検証する、ロケーションに存在するすべてのデータを検証する、もしくは検証自体をスキップします。検証オプションに関係なくすべてのデータは転送中に検証されていますが、推奨されるオプションは転送されたデータのみを検証することです。
DataSync タスクのパフォーマンスは、使用可能なネットワーク帯域幅、転送元と転送先ストレージの性能、平均ファイルサイズなど様々な要因に左右されます。平均ファイルサイズが MB から TB のオーダーになると、タスクのデータスループットは大きくなります。一方で、平均サイズが KB オーダーの小さなファイルを転送するタスクでは、より大きいファイルスループットが求められます。
複数タスクによるデータ転送のスケールアウト
このブログの読者は、次のようなことを考えているかもしれません。「今回のケースでは、複数のディレクトリ、あるいは複数のストレージシステムにまたがる、何百万のファイルで構成されています。この大規模なデータセットを効率的に転送するには、どのようなアプローチを取ればよいのでしょうか?」大規模なデータセットの場合は、マルチタスクおよびマルチエージェントアーキテクチャによるデータ転送のスケーリングを推奨します。複数のタスクを並列して実行することで、ワークロードを複数のエージェントに分散し、転送フェーズを高速化できます。このアプローチは、タスクごとに処理するファイルとディレクトリ数を削減できます。つまり、大規模なデータセット全体で、ファイル差分を同時に計算することができます。これにより、移行とカットオーバーを計画する際の、準備フェーズと移行フェーズにかかる時間を短縮できます。
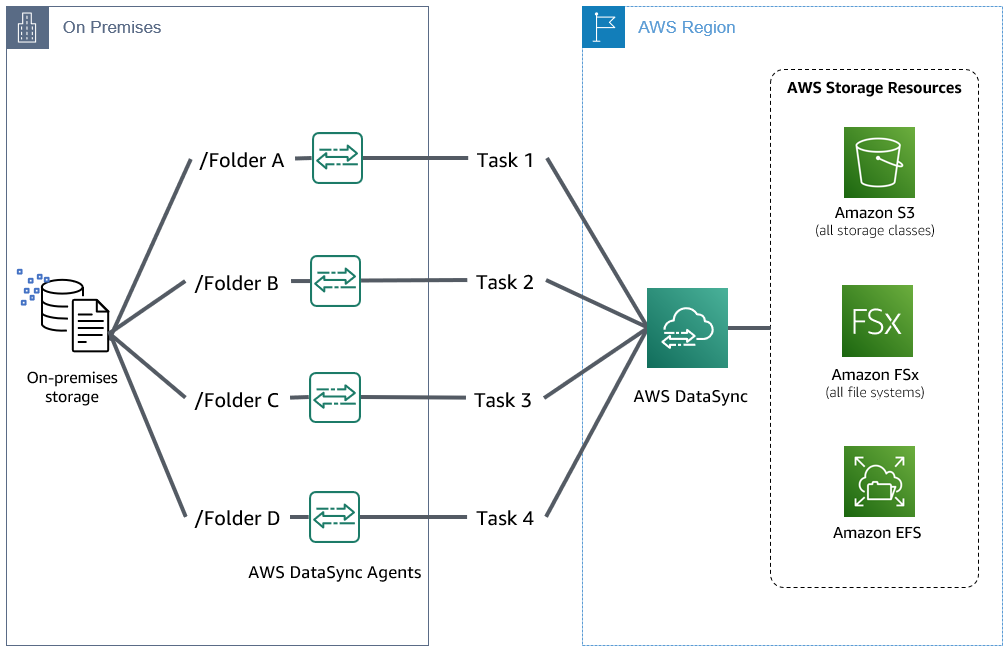
図 3: 複数の DataSync エージェントをオンプレミスに配置し、単一ストレージに並列でタスクを実行する
並列アプローチを使用するために、転送元ロケーションにおいてターゲットパスを指定する、タスクフィルターによる特定のデータを対象とする、もしくは除外する、あるいはこれらを組み合わせることで異なるデータセットを読み取るように各タスクを構成します。
エージェントが必要な DataSync ロケーションを作成する場合、エージェントと共にマウントパスや共有名、フォルダを指定して、タスクの範囲を特定のフォルダに絞り込みます。
タスクフィルターを使用すると、転送元の特定のフォルダ、もしくは特定のファイルセットからの読み取りを制限できます。これは、最上位のエクスポートパスから複数のフォルダを含める場合や、指定した転送元ロケーションをさらに絞り込みたい場合に便利です。include フィルターにより DataSync タスクごとに固有のフォルダパスを指定することができ、各タスクを並列して実行できます。
例として、最上位フォルダ「customers」を含むファイル共有があり、その中には A-Z の範囲で始まる固有アカウント名のフォルダが含まれていることを考えます。この場合、「/customer/a*」「/customer/b*」のように各タスク毎に固有の include フィルターを使用することで、複数の DataSync タスクにデータ転送を分散することができます。「*」はワイルドカードとして使用され、タスクには特定の文字で始まるすべての顧客が含まれます。フィルターは大文字と小文字を区別するため、フォルダーの命名規則によっては、「/customer/a*」と「/customer/A*」を含める必要があることに注意してください。また、include フィルターと exclude フィルターを組み合わせることで、転送時に特定のデータセットをスキップすることもできます。
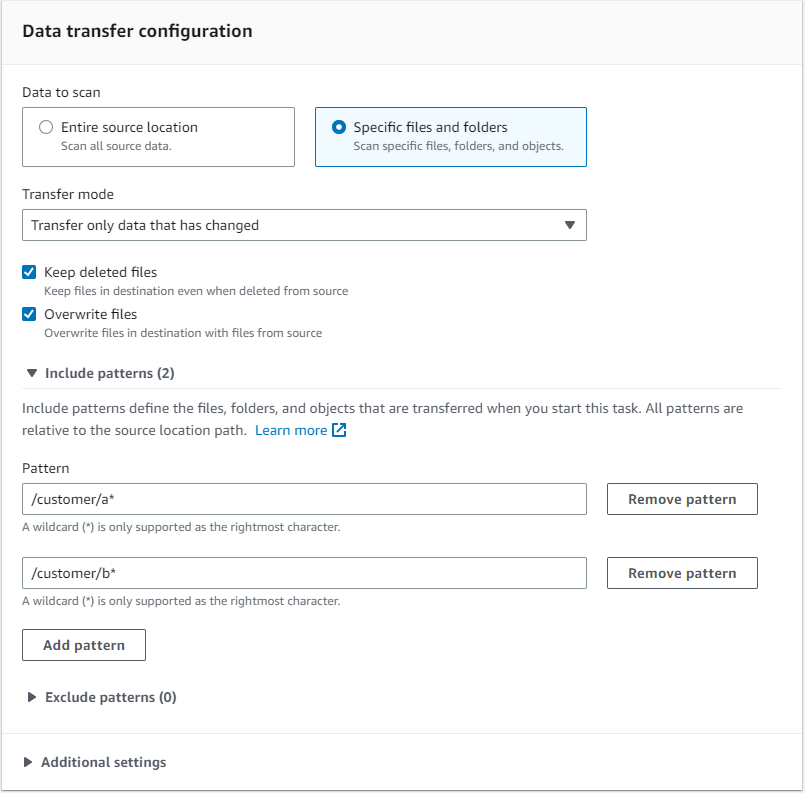
図 4: include フィルターを使用してフォルダパスを特定するタスクのフィルターオプション
インフラストラクチャ内の他ワークロードに注意する
DataSync タスクを並列で実行する場合、転送元と転送先におけるストレージシステムのパフォーマンス特性と利用可能なネットワーク帯域幅に注意してください。タスクを同時に実行すると、転送元と転送先の両方で I/O 操作が増加します。大規模な転送を開始する前に、ストレージチームと協力して I/O ワークロードを計画してください。
Amazon EFS と Amazon FSx においても、IOPS とスループットのサイジングを考慮する必要があります。Amazon EFS の場合、DataSync タスクの実行中にスループットパフォーマンスを自動でスケーリングする Elastic スループットモードの利用を検討してください。
Amazon FSx ファイルシステムにもパフォーマンスを左右する様々なチューニング機能があります。ファイルシステムは、スループットキャパシティや用意する IOPS の設定だけでなく、異なるディスクスループットパフォーマンスを提供する HDD または SSD ストレージから選択できます。高スループットのデータ転送を可能にするようファイルシステムの設定を調整し、転送中はパフォーマンスの監視を検討してください。パフォーマンスを監視することは、データ転送前、および転送中のストレージリソース使用状況を把握するために重要です。
Amazon CloudWatch と AWS マネジメントコンソールを使用して、AWS のファイルシステムを監視することができます。これらは、スループットと IOPS を監視するためのメトリクスを提供します。モニタリングとパフォーマンスの詳細については、以下の表に記載の AWS ドキュメントを参照してください。
DataSync タスクを並列して実行することにより、ネットワーク帯域幅の使用量も増加します。1 つのタスクからビルディングブロックアプローチを検証し、データセットに対するスループットパフォーマンスを推定しましょう。各タスクのパフォーマンスが 300 MiB/s を超えている場合、10 Gb の AWS Direct Connect 回線やインターネット回線の帯域ををすぐに上限まで使用してしまう可能性があります。ネットワークチームと協力して予想される使用率を計画することも、重要な事前ステップです。この並列アプローチは、図 3 のような単一ストレージシステムから転送する場合、図 5 のように複数のストレージシステムから転送する場合、AWS ストレージサービスから転送する場合、いずれの場合でも採用することができます。
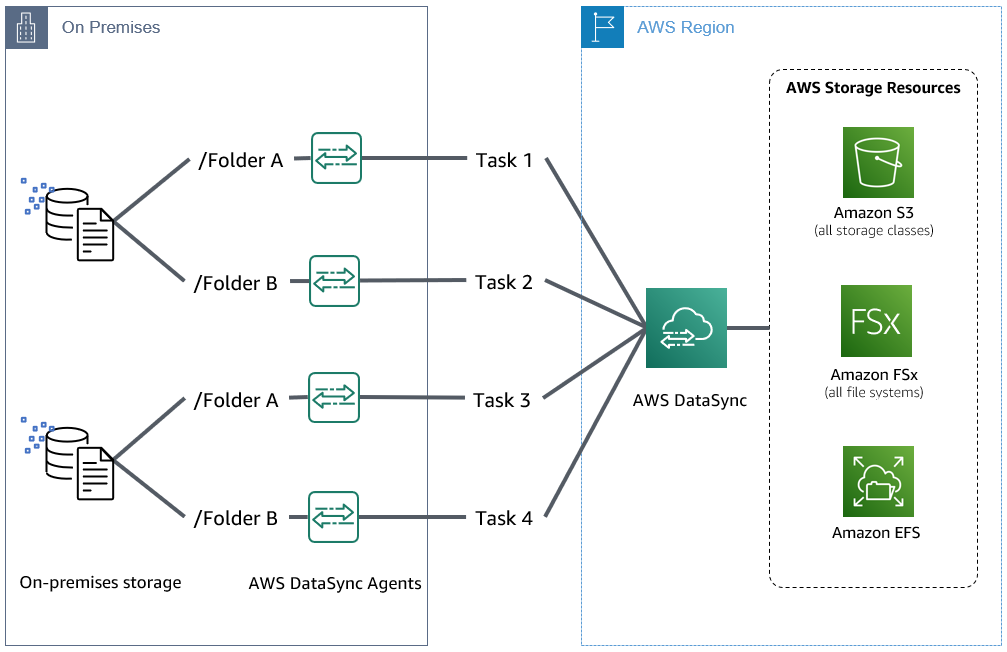
図 5: 複数のストレージシステムから複数のタスクを並列で実行する複数の DataSync エージェント
単一の DataSync タスクを複数の DataSync エージェントでスケールアウトする方法
データ転送を高速化するもう一つの方法は、図 6 に示すように 1 つのタスクとロケーションに、複数の DataSync エージェントを設定することです。転送するデータが数百万の小さなファイルで構成される場合、複数のエージェントを使用するようにロケーションを設定することで、追加の並列化が可能になります。結果としてこのアーキテクチャはスループットを向上させることに役立ちます。一方で、タスクの準備フェーズは短縮されません。加えて、1 つのロケーションに複数のエージェントを割り当てても高可用性は得られないことに注意が必要です。タスクを実行するには、すべてのエージェントがオンラインである必要があるからです。
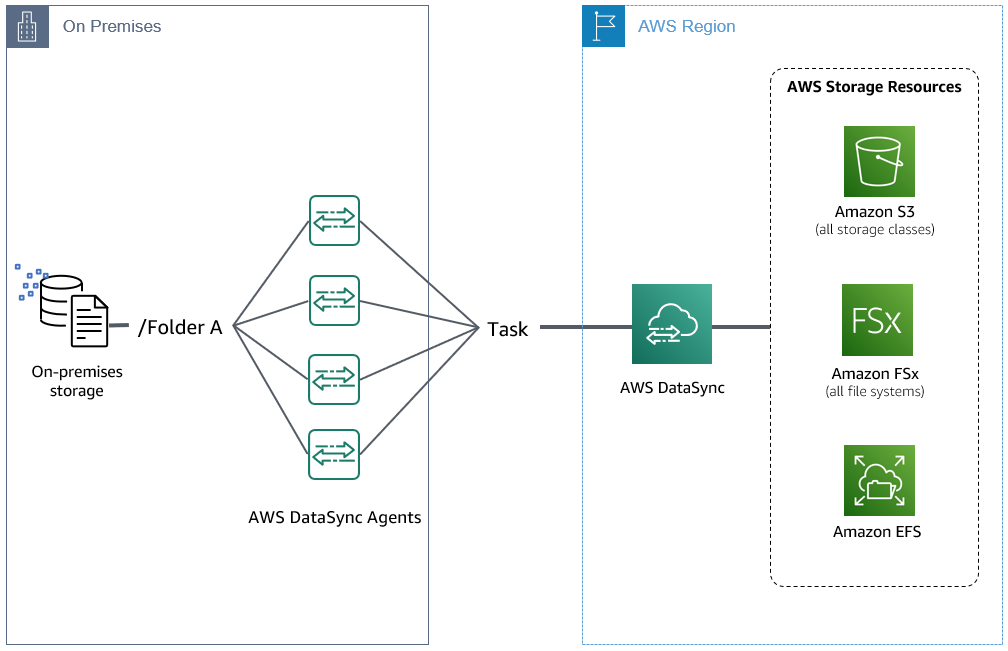
図 6: 1 つのロケーションに関連づけられた複数の DataSync エージェント
AWS DataSync のスケールアウト手法を組み合わせる
複数の DataSync タスクによるスケールアウト手法と各タスクに複数の DataSync エージェントを配置する手法を組み合わせて、より大規模なデータ転送を行うことも可能です。つまり各タスクに複数のエージェントを指定し、複数のタスクが並列して実行されるように設定できます。これにより、アーカイブデータの移行と変更されるデータについて差分データの転送を実施するなど、さまざまなユースケースに対応することができます。これらのスケールアウト手法により、用意できるインフラストラクチャを限界まで活用することができます。
まとめ
このブログでは、AWS DataSync におけるビルディングブロックアプローチの構成要素と、複数の DataSync エージェントと複数の DataSync タスクを用いたデータ転送のスケール方法について説明しました。まず、データ転送を並列化するために、複数のタスクに 1 つのエージェントを配置するマルチタスクアプローチを紹介しました。次に、利用可能なネットワーク帯域幅の分析や、転送元と転送先のストレージ性能評価を考慮してプランを立てる必要性を強調しました。さらに、複数のエージェントを単一のタスクに割り当てることで、個々のタスクをスケールアウトする方法を紹介しました。
以上のような並列化手法は、データ転送のスケールアウトに役立ちます。今回は主にオンプレミスとのデータ転送に焦点を当てましたが、複数のタスクを用いたスケールアウト手法は転送元を AWS ストレージサービスや他パブリッククラウドとする場合でも適用できます。
これらの方法により、データセンターのストレージシステムから AWS ストレージサービスへデータを移行する場合、AWS ストレージサービス間でデータ移行する場合、データ処理のためにクラウドへデータを移行するような場合に、所要時間を短縮することができます。
AWS DataSync を使うことで、今すぐにデータ転送計画を開始できます。Globe Telecom 社が AWS DataSync におけるスケールアウト手法を組み合わせて、ペタバイト規模の HDFS データを移行した方法については、こちらの記事をご覧ください。また、追加で AWS DataSync について学習したい場合は、AWS DataSync の開始方法を参照してください。
翻訳はソリューションアーキテクトの吉澤巧が担当しました。