Amazon Web Services ブログ
Amazon EKS における Kubernetes ネイティブな開発者のための CloudWatch 中心のオブザーバビリティの実装
訳注 : この記事で出てくる K8s Cloudwatch Adapter プロジェクトは、現在はアーカイブされ、開発されていません。CloudWatch からメトリクスを取得可能なメトリクスサーバーが必要な場合には、代わりに KEDA プロジェクトをご検討ください。KEDA を使用すると、処理待ちのイベント数に基づいて、Kubernetes 上の任意のコンテナをスケーリングできます。KEDA の概要については、An overview of Kubernetes Event-Driven Autoscaling をご参照ください。
この記事は Implementing CloudWatch-centric observability for Kubernetes-native developers in Amazon Elastic Kubernetes Service (記事公開日 : 2021 年 8 月 17 日) の翻訳です。原文は Seth Dobson (サウスウエスト航空)、Paul Ramsey、Sheetal Joshi によって執筆されました。
この記事では、サウスウエスト航空のような大規模な企業組織が Amazon Elastic Kubernetes Service (Amazon EKS) 上で稼働する Kubernetes クラスターで、Kubernetes ネイティブな開発者にとって自然な方法で Amazon CloudWatch を中心としたエンドツーエンドのオブザーバビリティソリューションをどのように実装できるかを示します。Kubernetes マニフェストでの CloudWatch アラームの作成や、CloudWatch メトリクスと Kubernetes Horizontal Pod Autoscaler (HPA) の統合など、CloudWatch と Kubernetes の統合に関する主要な課題を取り上げています。オブザーバビリティの 3 つの柱 (ログ、メトリクス、トレース) を実現する際に CloudWatch を使用することで、開発者は複数のオープンソースツールやオブザーバビリティに関するサードパーティのライセンス製品の設定、運用、更新に費やす時間を減らし、顧客のためのイノベーションに時間を費やすことができます。
導入
サウスウエスト航空では、事業運営に必要なミッションクリティカルなアプリケーションをホストする大規模な Amazon EKS 環境を管理しています。Amazon EKS は、アプリケーション実行のための安全かつ可用性の高い Kubernetes クラスターを提供し、コントロールプレーンの管理という重労働を肩代わりしてくれます。
サウスウエスト航空では、これらのコンテナ化されたワークロードに加えて、AWS Lambda や Amazon Elastic Container Services (Amazon ECS) での AWS Fargate でサーバーレスワークロードを、Amazon Elastic Compute Cloud (Amazon EC2) で従来のサーバーベースワークロードを実行しています。これらのアプリケーションは、それぞれ独自のバックエンドデータストア (Amazon Aurora、Amazon DynamoDB)、メッセージング層 (Amazon Simple Queue Service [Amazon SQS]、Amazon Simple Notification Service [Amazon SNS])、Ingress と API 管理 (Elastic Load Balancing [ELB]、Amazon API Gateway)、その他多くの Amazon サービスを使用しており、顧客のために環境の安全性、可用性、応答性を維持する手助けをしてくれています。
ワークロードに何か問題が発生した場合には、イベントを検知し、適切な担当者にアラートを発行し、ログやトレースといったデータを解釈しやすい形式で公開するオブザーバビリティソリューションが必要です。これにより、運用チームが迅速に問題を特定、解決することが可能となります。
また、エンジニアがビジネスにとって重要な作業に集中できるように、すべてのアプリケーションスタック (コンテナ、サーバーレス、サーバーベース) に対して利用可能なプラットフォームを選択し、かつそのソリューションの管理コストを最小限に抑える必要があります。さらに、選択したプラットフォームが、オブザーバビリティの 3 つの柱 (ログ、メトリクス、トレース) すべてをカバーするエンドツーエンドのソリューションである必要があります。
様々なオープンソースやサードパーティのオブザーバビリティツールを検討した結果、私たちは標準のオブザーバビリティソリューションとして Amazon CloudWatch を選択しました。なぜなら、私たちが持つすべてのアプリケーションアーキテクチャを一元的に可視化できるからです。CloudWatch は、インフラストラクチャやライセンスが不要で、すべての Amazon Web Services (AWS) サービスとネイティブに統合しており、AWS のお客様はデフォルトで利用可能です。
CloudWatch はサーバーレスなので、バージョンの更新やインスタンスのサイジングを気にする必要はありません。さらに、Amazon EKS 上で動作するコンテナ化されたアプリケーションのメトリクスの取得と可視化を実現する CloudWatch Container Insights を利用できます。
しかし、EKS に Amazon CloudWatch を導入する際に、私たちには CloudWatch のメトリクスとアラームに関する以下のような課題がありました。
- CloudWatch メトリクスと Kubernetes メトリクスサーバーの間にネイティブな統合がないため、アプリケーションは Kubernetes の Horizontal Pod Autoscaler (HPA) を使用して、CloudWatch のメトリクスに基づいたスケーリングを実行できません。
- 開発者は CloudWatch API を Kubernetes API 経由で利用できないため、Kubernetes マニフェストでの CloudWatch アラームなどのリソースの定義はサポートされていません。代わりに、AWS CloudFormation やその他の自動化ツールを介して、マニフェストの外でアラームを定義する必要があります。しかし、これは理想的な Kubernetes ネイティブな開発体験とはいえません。
この記事では、サウスウエスト航空でこれら 2 つの課題をどのように解決したかを説明します。また、それらのソリューションを、どのように Kubernetes ネイティブな方法で、CloudWatch を中心としたオブザーバビリティソリューションに当てはめたかを紹介します。
アーキテクチャ
このソリューションを実現するアーキテクチャは、以下の要素で構成されています。(図 1)
- Kubernetes 開発者が、Kubernetes マニフェストで CloudWatch アラームを定義できるようにするための Kubernetes の CustomResourceDefinition と Operator。
- CloudWatch から Kubernetes メトリクスサーバーにメトリクスを取り込むための K8s-CloudWatch-Adapter。これを使用することで、Kubernetes の Horizontal Pod Autoscaler (HPA) を介して、CloudWatch メトリクスに基づいた Pod のスケーリングがネイティブに実現できます。(訳注 : K8s-Cloudwatch-Adapter プロジェクトは、現在はアーカイブされ、開発されていません。CloudWatch からメトリクスサーバーにメトリクスを取り込む必要がある場合には、代わりに KEDA プロジェクトをご検討ください。)
- Amazon EKS から CloudWatch にログを転送するための Fluent Bit DaemonSet。これにより、CloudWatch Logs Insights でログを検索、可視化できるようになります。
- トレースを AWS X-Ray に転送し、メトリクスを CloudWatch メトリクスに転送するための AWS Distro for Open Telemetry (OTEL) Collector DaemonSet。この例では、Prometheus メトリクス、StatsD メトリクス、開発者が Kubernetes マニフェストで作成するカスタムメトリクスを、OTEL を使用して転送します。これらのトレースやメトリクスをすべて CloudWatch に集約することで、CloudWatch ServiceLens を通じて、エンドツーエンドのアプリケーションの健全性を監視、可視化できるようになります。
- CloudWatch Container Insights メトリクスを収集するための CloudWatch エージェント。
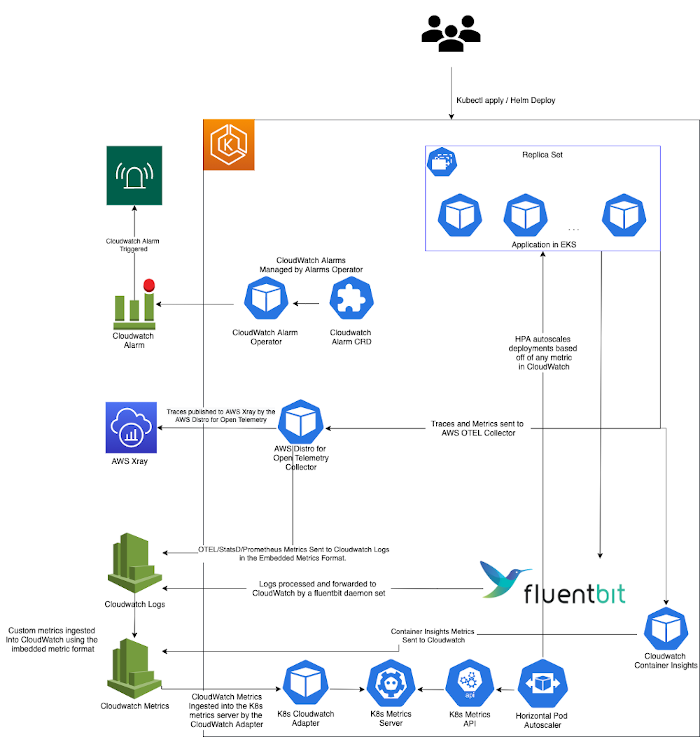
図 1 : ソリューションアーキテクチャ
Kubernetes マニフェストでアラームを定義する
サウスウエスト航空の Kubernetes 開発者は、アプリケーションの健全性を把握するためのメトリクスやアラームを含め、アプリケーション全体を単一のマニフェストで定義したいと考えています。これは Prometheus を使用すれば簡単に実現できますが、Prometheus を用いてアラームを作成するには、Prometheus 環境をプロビジョニング、実行、維持する必要があり、複雑で時間がかかる可能性があります。また、これは Prometheus メトリクスを 2 つの場所 (Prometheus サーバーと CloudWatch) に保存することを意味します。なぜなら、すべてのメトリクスを CloudWatch に集約し、エンドツーエンドで可視化したいと考えているからです。
もう 1 つの選択肢として、CloudFormation でアラームを定義する方法がありました。しかし、この方法では、メトリクスをある場所 (マニフェスト) で、アラームをまた別の場所 (CloudFormation テンプレート) で定義する必要があるため、Kubernetes 開発者にとって直感的な方法ではありませんでした。
私たちは、Prometheus Server のデプロイに伴う複雑さやコスト、管理の手間を増やすことなく、Kubernetes ネイティブな開発環境を提供したいと考えていました。そこで、Kubernetes マニフェストで直接 CloudWatch アラームを作成、更新、削除するための Kubernetes の CustomResourceDefinition (CRD) と Operator を作成しました。
この後、サンプルアプリケーションを作成していく中でデプロイされる Helm チャートの一部には、コントローラと、それを動作させるのに必要な Kubernetes の設定がすべて含まれています。このコントローラーによって定義された CloudWatch メトリクスのアラームの設定例を以下に示します。アラームアクションを使用して、HPA の設定が Pod の最大数に近づいた場合など、人の介入が必要なアラーム状況をチケットシステムに通知します。
---
apiVersion: cw.aws.com/v1
kind: cloudwatchmetricalarm
metadata:
namespace: default
name: otlp-consumer-alarm
spec:
MetricName: service_number_of_running_pods
CloudwatchMetricNamespace: ContainerInsights
Statistic: Maximum
Dimensions:
- Name: ClusterName
Value: cloudwatch-example-cluster
- Name: Service
Value: otlp-consumer
- Name: Namespace
Value: default
Period: 300
EvaluationPeriods: 1
DatapointsToAlarm: 1
AlarmActions: [Some ARN of A Lambda, or SNS topic]
Threshold: 8
ComparisonOperator: GreaterThanThreshold
TreatMissingData: missingCloudWatch メトリクスを用いて Pod をスケールさせる
CloudWatch メトリクスに基づいた Kubernetes の Pod のスケーリングに関する課題は新しいものではなく、これまでにも少なくとも 2 つの異なるアプローチが Amazon ブログ記事で紹介されています。”Autoscaling Amazon EKS services based on custom Prometheus metrics using CloudWatch Container Insights” で紹介されている 1 つ目の選択肢は、メトリクスが定義された閾値を超えた際に、Amazon EKS クラスターに対してスケーリング命令を実行する Lambda 関数を呼び出すことです。このアプローチの欠点は、スケーリングポリシーを Kubernetes マニフェスト内で宣言的に定義できないことです。さらに、Amazon EKS クラスターの外からスケーリング命令を実行するため、複雑さを増加させることになります。
“Scaling Kubernetes deployments with Amazon CloudWatch metrics“ で紹介されている 2 つ目の選択肢は、K8s CloudWatch Adapter を使用することです。私たちがこのソリューションを選択した理由は、すぐに利用可能な Kubernetes の機能である HPA を使用して、より Kubernetes ネイティブなアプローチを実現できるからです。このアダプターは、CloudWatch メトリクスを Kubernetes メトリクスサーバーに提供することで、HPA がスケーリングポリシーで利用できるようにします。このアプローチは、スケーリング機能の起動を Lambda のような外部リソースに依存するのではなく、アプリケーション全体を Kubernetes マニフェストで定義したいという私たちの要望を満たしています。
サンプルアプリケーション
私たちは、これらのピースを組み合わせ、Kubernetes マニフェストでアプリケーションを定義し、CloudWatch を介してエンドツーエンドのオブザーバビリティを実現する方法を示すために、サンプルアプリケーションを用意しました。これには、カスタムメトリクスやアラーム、CloudWatch メトリクスに基づいたスケーリングポリシーが含まれます。(図 2)
プロデューサープロセスは毎秒 1 つのメッセージを Amazon SQS キューに書き込み、コンシューマープロセスは 5 秒ごとに 1 つのメッセージを消費します。HPA ポリシーは、SQS キューの深さが 30 メッセージを超えたときにアプリケーションをスケールさせるように設定され、CloudWatch アラームは、アプリケーションが、定義された Pod の最大数 10 のうち 8 Pod に達したときに担当者にアラートを発行します。
アプリケーションは、Prometheus メトリクス (標準、カスタムの両方) と、プロデューサーが送信したメッセージ数に関するカスタム StatsD メトリクスを送信します。アプリケーションは、OTEL Collector を使用して、プロデューサーとコンシューマー両方のトレースを AWS X-Ray に転送します。また、すべてのログを Amazon CloudWatch Logs に送信します。

図 2 : サンプルアプリケーション
前提条件
この例では、以下のものがインストールされ、最新バージョンにアップグレードされている必要があります。
セットアップ
1.リポジトリ amazon-cloudwatch-alarms-controller-for-kubernetes をクローンします。
git clone https://github.com/aws-samples/amazon-cloudwatch-alarms-controller-for-kubernetes.git2.EKS クラスターを作成します。
cd amazon-cloudwatch-alarms-controller-for-kubernetes/
eksctl create cluster -f deployment/eksctl/cluster.yaml3.Docker ファイルをビルド、公開します。(備考 : Docker の匿名セッションのレート制限を避けるために、まず Docker にログインする必要があるかもしれません。)
source ./build.sh4.ビルドスクリプトが、後続のステップに必要な環境変数を設定しているかを確認します。
echo $CW_ALARM_OPERATOR
echo $OTLP_TEST_PRODUCER
echo $OTLP_TEST_CONSUMER5.Helm チャートをデプロイします。
helm upgrade --install --set cloudwatch-alarms-operator.image=$CW_ALARM_OPERATOR amazon-cloudwatch deployment/helm/6.サンプルアプリケーションをデプロイします。
./deployment/sample_application/deploy_sample.shメトリクス
サンプルアプリケーションがデプロイされ、CloudWatch にカスタムメトリクスが生成されるようになったので、CloudWatch メトリクスのカスタム名前空間 EKS/AWSOTel/Application で可視化できます。
1.AWS マネージメントコンソールで、CloudWatch サービスを選択します。
2.左側のナビゲーションパネルから、Metrics > All Metrics を選択します。
3.名前空間 EKS/AWSOTel/Application を選択します。
4.Metrics with no dimensions を選択します。
5.messages メトリクスの隣にあるボックスにチェックを入れます。
6.ここまで完了すると、図 3 のようなグラフが表示され、サンプルアプリケーションが生成したメッセージ数が表示されます。これは StatsD が送信したカスタムメトリクスで、OTEL Collector を介して CloudWatch に転送されたものです。
 図 3 : 生成されたメッセージ数
図 3 : 生成されたメッセージ数
Helm チャートと一緒にデプロイされた Amazon OTEL Collector は、Prometheus メトリクスを収集するために Pod と Service をスクレイピングするようにも設定されています。サンプルアプリケーションは、StatsD メトリクスと同じメトリクス名前空間 EKS/AWSOTel/Application CloudWatch で可視化可能な、カスタム Prometheus メトリクスも送信します。
7. CloudWatch で、左のナビゲーションパネルから Metrics > All Metrics を選択します。
8. 名前空間 EKS/AWSOTel/Application を選択します。
9. Service ディメンションを選択します。
10. message_producing_seconds メトリクスの隣にあるボックスにチェックを入れます。
11. ここまで完了すると、図 4 のようなグラフが表示され、キューに入れたメッセージを生成するのにかかった時間が表示されます。
 図 4 : メッセージの生成にかかった時間
図 4 : メッセージの生成にかかった時間
スケーリング
このサンプルアプリケーションは、コンシューマーが消費するよりも速く SQS キューにメッセージを生成します。したがって、キューは指数関数的に増大していきます。キューの深さは Amazon SQS メトリクスで監視されており、Helm チャート K8s CloudWatch Adapter を利用することで、このメトリクスに基づいてアプリケーションを自動でスケールさせることが可能です。
1.アプリケーションを約 15 分間実行します。
2.以下のコマンドを実行して、HPA の設定を表示します。この設定では、キュー内の可視性のあるメッセージの増加数に基づいて、追加のコンシューマー Pod をスケールアウトさせていることが分かります。
kubectl describe hpa
図 5 : HPA が Deployment を 5 Pod にまでスケールさせている様子
 図 6 : HPA が Deployment を設定した最大 Pod 数 10 までスケールさせている様子
図 6 : HPA が Deployment を設定した最大 Pod 数 10 までスケールさせている様子
アラーム
この時点では、メッセージ急増の原因を調査するためには、多くの場合、人の介入が不可欠です。そして、 私たちは HPA の最大許容 Pod 数を増加させるか、メッセージ急増の根本的な原因を解決する必要があります。
この例では、8 個以上のコンシューマーの Pod が起動した際にアラートを発行する CloudWatch アラームを設定します。先程作成した CloudWatch アラームの CRD のおかげで、アプリケーション定義や HPA の設定と同じマニフェスト内で、カスタムメトリクス ( service_number_of_running_pods ) とそのメトリクスに関するアラームの両方を定義できます。
1.CloudWatch で Alarms > All alarms を選択し、マニフェストで定義したカスタムアラームを見てみましょう。見るタイミングによって、アラームが In Alarm になっていたり、そうでなかったりするでしょう。これは、キューがアラームを作動させる深さになるまでに時間がかかるためです。
 図 7 : Kubernetes マニフェストで設定されたカスタムアラーム
図 7 : Kubernetes マニフェストで設定されたカスタムアラーム
このアラームに対応するために、担当者にページングしたり、Lambda を使用して自動対応したり、その他の任意のアクションを実行できます。一度アラームが発生すると、CloudWatch Container Insights のタブからもアラームを確認できます。
2.CloudWatch で Insights > Container Insights を選択します。Container Insights は、コンテナ化されたアプリケーションとマイクロサービスから、メトリクスとログを収集、集約、要約します。以下に示すグラフと可視化は、クラスター上でこの機能を有効にすることで利用できます。
 図 8 : CloudWatch Container Insights ダッシュボード
図 8 : CloudWatch Container Insights ダッシュボード
ログ
ログが CloudWatch Logs に転送され、解析され、インデックス化されると、Amazon CloudWatch Logs Insights でログを用いた検索、可視化、メトリクスの作成、ダッシュボードの作成が可能です。サンプルアプリケーションは、メッセージを送信、もしくは SQS キューからメッセージを処理する度に、ログエントリを書き込んでいます。アプリケーションログは、/aws/containerinsights/cloudwatch-example-cluster/application ロググループ書き込まれます。
1.CloudWatch で Logs > Log Insights を選択します。
2.以下のサンプルクエリを実行し、キューからのメッセージを消費するすべての Pod のログを見てみましょう。
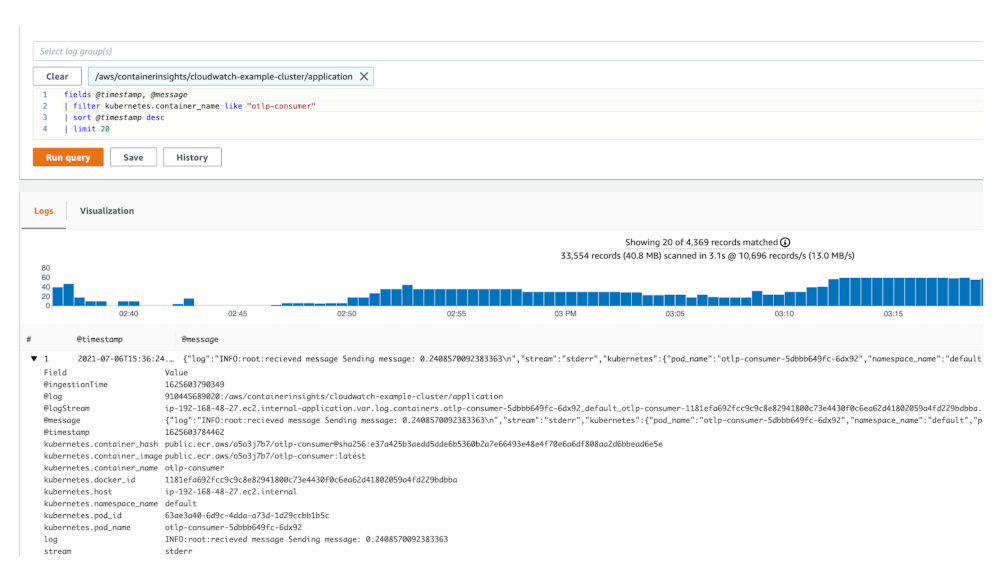 図 9 : CloudWatch Logs Insights のクエリ結果
図 9 : CloudWatch Logs Insights のクエリ結果
トレース
最後に、CloudWatch の ServiceLens のタブで、サンプルアプリケーションに関するエンドツーエンドのアプリケーションの健全性を確認できます。ServiceLens は、トレース、メトリクス、ログ、アラーム、その他のリソースの状態に関する情報を一箇所に統合することで、より効率的に性能のボトルネックを見つけ出し、影響を受けたユーザーを特定できます。 1. CloudWatch で Application monitoring > ServiceLens map を選択します。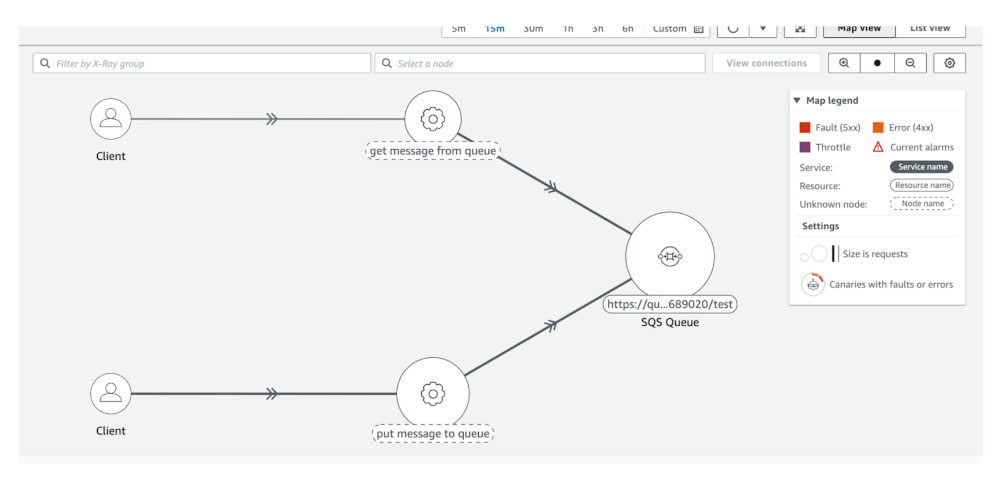 図 10 : サンプルアプリケーションのトレースを可視化する CloudWatch ServiceLens 2.特定のアプリケーションのトレースを確認するために、プロデューサーまたはコンシューマーに絞り込みます。
図 10 : サンプルアプリケーションのトレースを可視化する CloudWatch ServiceLens 2.特定のアプリケーションのトレースを確認するために、プロデューサーまたはコンシューマーに絞り込みます。  図 11 : トレースの詳細
図 11 : トレースの詳細
後片付け
アカウントへの継続的な課金を避けるため、以下のコマンドを実行することで、作成したオブジェクトを削除できます。./deployment/sample_application/destroy_sample.sh
helm delete amazon-cloudwatch
eksctl delete cluster -f deployment/eksctl/cluster.yamlまた、先程ビルドしたイメージをホストするために作成した Amazon ECR リポジトリを削除します。
- AWS コンソールで Elastic Container Registry サービスを開きます。
- Public タブを選択します。
- 作成したリポジトリ (
cw-alarm-operator、operator,otlp-test-consumer、otlp-test-producer) を削除します。
まとめ
AWS 上にエンドツーエンドの CloudWatch 中心のオブザーバビリティソリューションを構築することで、複数のオープンソースツールを設定、運用せず、追加のライセンス製品を購入せず、オブザーバビリティプラットフォームのバージョンを更新する必要無しで、オブザーバビリティの 3 つの柱を実現できます。
このソリューションにより、プラットフォーム開発者は、ツールの更新や保守よりも、ビジネス価値の提供に集中できます。CloudWatch のメトリクスやアラームと Kubernetes の統合に関していくつかの課題がありますが、この記事で紹介した例では、サウスウエスト航空のような大規模な組織がそれらの課題を解決する現実的な 1 つの方法を示しています。