AWS Partner Network (APN) Blog
AWS Partner Network (APN) Partner SA Roundup – September 2017
This month, we have three Partner Solutions Architects who will be highlighting four APN Partners they’ve been working with. We will hear from David Potes, Chris Hein, and Pratap Ramamurthy, who will dive deeper into offerings from JFrog, Linkerd, Solodev, and Sparkpost!
JFrog, by David Potes
 A few months ago, I had the opportunity to attend the JFrog Swampup conference in Napa, California. Not only do they have an impressive list of customers, including Amazon, but they also have a few interesting products. The energy and enthusiasm that I felt from the community there really piqued my interest, so I took some time to dive into one of their key offerings. JFrog is all about open source, and the product I’m focusing on today, JFrog Artifactory, has a free open source version. They also offer enhanced versions with enterprise features and a SaaS-delivered version, for customers that would rather leave operations to someone else.
A few months ago, I had the opportunity to attend the JFrog Swampup conference in Napa, California. Not only do they have an impressive list of customers, including Amazon, but they also have a few interesting products. The energy and enthusiasm that I felt from the community there really piqued my interest, so I took some time to dive into one of their key offerings. JFrog is all about open source, and the product I’m focusing on today, JFrog Artifactory, has a free open source version. They also offer enhanced versions with enterprise features and a SaaS-delivered version, for customers that would rather leave operations to someone else.
As companies of all sizes have embraced open source technology, their development processes have evolved from primarily using proprietary in-house coding to an amalgamation of free open source libraries, commercial libraries, as well as their own code. Just as in modern manufacturing, code is often assembled from components rather than developed from scratch. The benefits of this approach are well-documented, but using open source or commercial libraries introduces a few new challenges, too.
The biggest challenge is managing complexity. Often companies have a polyglot of languages they support, packages of various types and system artifacts such as Docker and Vagrant images. Each of these can have its own upstream and downstream dependencies, versions, licenses, and traceability data. The aim of a universal package manager, such as JFrog Artifactory, is to standardize the way that organizations manage all package types used in the software development process.
Just as teams adopted version control systems for source control, many companies are now adopting package management systems for binary artifacts. Below are a few key things to look for as you are evaluating an artifact repository.
Highly available access to remote artifacts. A package control system can act as an intermediate cache for remote repositories. This is known as a remote repository, though the parlance is a bit confusing. By acting as a proxy and a caching system, the tool is designed to provide faster access to binaries, as well as limit the blast radius, when an external repository is temporarily unavailable (or even permanently).
Full integration with your DevOps toolchain. Just as with source control, an artifact repository is at the center of your toolchain processes, so it’s critical for it to integrate with the tools that you use (or ones that you may use in the future). JFrog has a staggering number of integrations; everything from CI servers like Jenkins and Bamboo, remote repositories like Nuget and Github, to provisioning tools like Chef and Puppet and familiar names like Maven, Gradle, and Ivy.
Security and Access Control. Controlling access to entire repositories down to individual artifacts is a key feature, but also look for the ability to integrate existing access controls via LDAP or SAML. JFrog supports this functionality, as well limiting what can be downloaded to the virtual repository via blacklisting/whitelisting.
License governance. With a tool like JFrog Artifactory, you can scan the licensing requirements for any packages you download to the repository and provide immediate feedback on the package and its dependencies. This allows you to make sure you’re compliant early on in the development cycle, and prevent unnecessary delays when it’s time to go to production.
I’ve only scratched the surface on what you can do with JFrog Artifactory, and I plan to revisit this for a deeper dive in the future. In the meantime, if you’d like to give it a try yourself, JFrog offers a free trial for the Pro and SaaS versions, or you can just grab the open source version and see for yourself.
Linkerd, by Chris Hein
 When building a distributed system, you have to deal with the challenges of making reliable/resilient requests from one service to another. While the underlying Transmission Control Protocol (TCP) layer can take care of packet-level reliability, request-level reliability–retries, timeouts, load balancing, circuit breaking, discovery, and so on–is relegated to application code. The advent of containers and automated container orchestration has only amplified these issues by making microservices easier to adopt than ever.
When building a distributed system, you have to deal with the challenges of making reliable/resilient requests from one service to another. While the underlying Transmission Control Protocol (TCP) layer can take care of packet-level reliability, request-level reliability–retries, timeouts, load balancing, circuit breaking, discovery, and so on–is relegated to application code. The advent of containers and automated container orchestration has only amplified these issues by making microservices easier to adopt than ever.
In the past, large scale companies developed OSS toolchains like SmartStack and Prana to offload this logic from the application and into a dedicated network proxy which handles requests going from one service to another. Although these solutions work, they’re tied to specific technology choices such as ZooKeeper or Eureka.
Enter Linkerd by APN Partner Buoyant. Linkerd is an open source, transparent layer 5/7 network proxy that is deployed as a “service mesh” to automatically add reliability and instrumentation to service requests. Linkerd integrates with a wide variety of environments including Consul, Kubernetes, and DC/OS. In Amazon EC2 Container Service (Amazon ECS), Linkerd only requires you to run a service discovery framework to be effective.
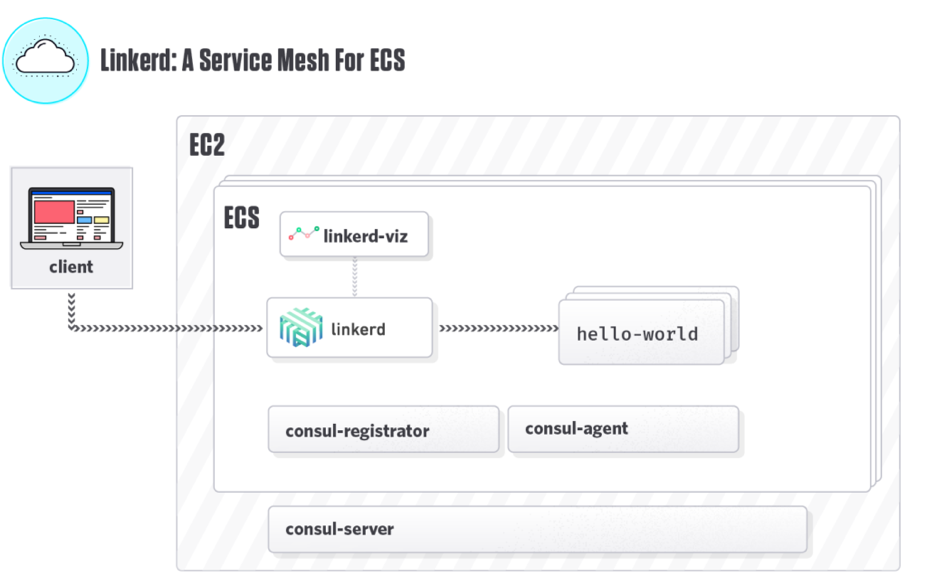
Buoyant has recently been working with various ECS customers to document the best practices from the field. With these best practices, ECS customers can deploy Linkerd as a service mesh using Consul by Hashicorp for service discovery, allowing you to monitor all internal request traffic (including top-line service metrics such as success rates and latency distributions), automatically retry requests when a service fails, or even dynamically route requests. For more information check out their blog post: A Service Mesh for ECS
Solodev Web Experience Platform, by Pratap Ramamurthy

When OneBlood, a non-profit organization that provides blood donation services, experienced a sudden 2700% increase in traffic on their website in one hour, the website did not go down. This is because they run on the Web Experience Platform, which was created and is managed by Solodev, an APN Advanced Technology Partner.
The Solodev Web Experience Platform is an advanced Web Content Management System (CMS) that helps customers deploy, host and manage enterprise-level websites as well as integrate their web content. It is architected based on best practices for security, high availability, and scalability as defined by the AWS Well-Architected Framework. Solodev uses the Elastic Load Balancing service to distribute traffic to application servers that reside in multiple Availability Zones, to provide high availability. When there are spikes in traffic, Solodev scales horizontally by using AWS OpsWorks to provision more instances.
The platform comes with several features that set it apart from a simple CMS. When you create new web content, A/B testing is arguably the most important tool you can use to find out what is working and what is not, especially before you release changes to production. With the Solodev platform, users can conduct A/B testing using Solodev Experiments, rapidly iterate through changes in their web content, and make informed decisions based on experimentation and testing.
Web content is a key part of an enterprise’s marketing effort. When web content, mobile content, CRM, and other marketing campaigns come together, the user gets a seamless experience. Solodev integrates with popular CRM software like Salesforce and SugarCRM, so you can import new leads from web forms into your CRM system. When you run an email campaign, having a web content manager that is aware of the campaign helps increase its success by making it seamless for the recipients. With this goal, Solodev has integrated with popular marketing automation tools like Pardot, Marketo, Eloqua and many more. These features and integration points turn the platform into a truly advanced Web Content Management System.
About the Solodev solution running on the AWS platform, OneBlood states, “While we were happy to have an uptime of 95% previously, we now see an uptime of 99.97%.” You can read about the OneBlood customer case study and try out the platform, which is available as a SaaS subscription.
SparkPost, by Pratap Ramamurthy
 In my first job, I was tasked to send out a newsletter to around 10,000 recipients. I wrote a quick test program using open source libraries, and successfully tested by sending a few emails. Later, when I started sending all 10,000 emails, everything started to fall apart. In hindsight, I should have used an email delivery service like SparkPost. Sending email at scale is a very specialized function that requires domain expertise. SparkPost abstracts this complexity by providing a managed service that customers can integrate with.
In my first job, I was tasked to send out a newsletter to around 10,000 recipients. I wrote a quick test program using open source libraries, and successfully tested by sending a few emails. Later, when I started sending all 10,000 emails, everything started to fall apart. In hindsight, I should have used an email delivery service like SparkPost. Sending email at scale is a very specialized function that requires domain expertise. SparkPost abstracts this complexity by providing a managed service that customers can integrate with.
There are two kinds of emails that enterprises usually send. The first is called “bulk email”, this usually includes announcements about new product launches, newsletters, and other similar items. Sending bulk email is an inherently “bursty” workload that could lead to scaling problems if self-managed. This need for elastic scalability is one of the problems that SparkPost solves by running on AWS.
The second kind of email is called “triggered email,” and it’s the kind that app developers most often want to send. Emails of this kind usually are API-driven and include common service and app use cases such as password changes and other security notifications, new registration and onboarding emails, and transactional receipts.
Relying on an email delivery service to send both bulk and triggered email is an effective way to reduce operational overhead and increase the success of email delivery. As a SparkPost customer you can leverage the SparkPost libraries to trigger emails from your application. See the figure below for a code sample in Python:
 Image used with permission
Image used with permission
An email delivery system cannot be a fire-and-forget system because the senders will not be able to measure success. SparkPost provides a near real time monitoring dashboard for the emails that were sent. This helps the sender measure the success, as well as fine tune the email strategy in future. The way email works today, the sender has no control or visibility beyond the first hop, so how does SparkPost measure success? SparkPost includes tracking info in the email that is triggered when the user opens a message or clicks on a link. This is combined with other relevant data and shown to the sender in a dashboard. Additionally, SparkPost takes it further by optionally enabling Webhooks to call your own endpoints for further analysis.
When you start measuring your email marketing campaigns, one of the first challenges you will notice is the delivery to success ratio. You may be sending emails, but your Internet Service Provider (ISP) might not be delivering them because of low email sender reputation. The email sender reputation is a score assigned by the ISP, and if it’s low, the ISP might be sending your emails to a Junk folder or even reject the emails outright. Several factors determine the score, like the number of emails sent by the organization, how often emails hit the spam trap, number of email bounces and so on. SparkPost helps you improve your email reputation by warming the IP address, managing feedback loops, and by following to best practices listed here.
Inbox delivery success criteria, security and many more aspects of email delivery are detailed in SparkPost documentation. Once you are ready, you can get started with a range of cost-effective plans. SparkPost also offers a free developer account that provides access to all SparkPost features and up to 15,000 free emails per month.