AWS News Blog
Amazon S3 – Object Size Limit Now 5 TB
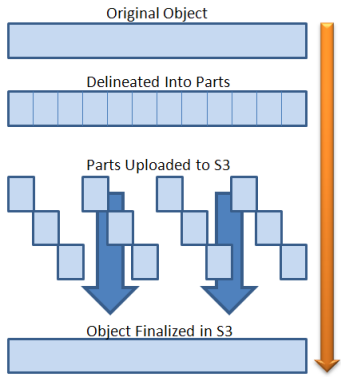 A number of our customers want to store very large files in Amazon S3 — scientific or medical data, high resolution video content, backup files, and so forth. Until now, they have had to store and reference the files as separate chunks of 5 gigabytes (GB) or less. So, when a customer wanted to access a large file or share it with others, they would either have to use several URIs in Amazon S3 or stitch the file back together using an intermediate server or within an application.
A number of our customers want to store very large files in Amazon S3 — scientific or medical data, high resolution video content, backup files, and so forth. Until now, they have had to store and reference the files as separate chunks of 5 gigabytes (GB) or less. So, when a customer wanted to access a large file or share it with others, they would either have to use several URIs in Amazon S3 or stitch the file back together using an intermediate server or within an application.
No more.
We’ve raised the limit by three orders of magnitude. Individual Amazon S3 objects can now range in size from 1 byte all the way to 5 terabytes (TB). Now customers can store extremely large files as single objects, which greatly simplifies their storage experience. Amazon S3 does the bookkeeping behind the scenes for our customers, so you can now GET that large object just like you would any other Amazon S3 object.
In order to store larger objects you would use the new Multipart Upload API that I blogged about last month to upload the object in parts. This opens up some really interesting use cases. For example, you could stream terabytes of data off of a genomic sequencer as it is being created, store the final data set as a single object and then analyze any subset of the data in EC2 using a ranged GET. You could also use a cluster of EC2 Cluster GPU instances to render a number of frames of a movie in parallel, accumulating the frames in a single S3 object even though each one is of variable (and unknown at the start of rendering) size.
The limit has already been raised, so the race is on to upload the first 5 terabyte object!
— Jeff;