AWS News Blog
Copy DynamoDB Data Between Regions Using the AWS Data Pipeline
If you use Amazon DynamoDB, you may already be using AWS Data Pipeline to make regular backups to Amazon S3, or to load backup data from S3 to DynamoDB.
Today we are releasing a new feature that enables periodic copying of the data in a DynamoDB table to another table in the region of your choice. You can use the copy for disaster recovery (DR) in the event that an error in your code damages the original table, or to federate DynamoDB data across regions to support a multi-region application.
You can access this feature by using a new template that you can access through the AWS Data Pipeline:
Select the template and then set up the parameters for the copy:
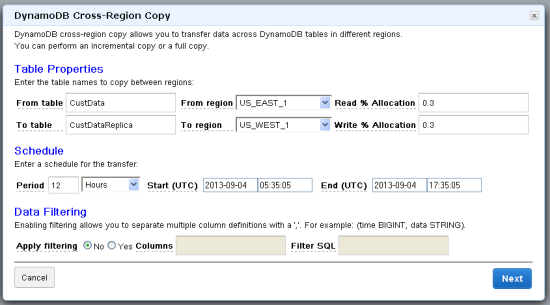
Enter the table names for the source and destination, along with their respective regions. The Read and Write Percentage Allocation is the percentage of the table’s total capacity units allocated to this copy. Then, set up the frequency of this copy, the start time for the first copy, and optionally the end time.
You can use the Data Filtering option to choose between four different copy operations:
Full Table Copy – If you do not set any of the Data Filtering parameters, the entire table — all items and all of their attributes — will be copied on every execution of the pipeline.
Incremental Copy – If each of the items in the table has a timestamp attribute, you can specify it in the Filter SQL field along with the timestamp value to select against. Note that this will not delete any items in the destination table. If you need this functionality, you can implement a logical delete (usig an attribute to indicate that an item has been deleted) instead of a physical deletion.
Selected Attribute Copy – If you would like to copy only a subset of the attributes of each item, specify the desired attributes in the Columns field.
Incremental Selected Attribute Copy – You can combine Incremental and Selected Attribute Copy operations and incrementally copy a subset of the attributes of each item.
Once you have filled out the form, you will see a confirmation window that summarizes how the copy is going to be accomplished. Data Pipeline uses Amazon Elastic Map Reduce (EMR) to perform a parallel copy of data directly from one DynamoDB table to the other, with no intermediate staging involved:
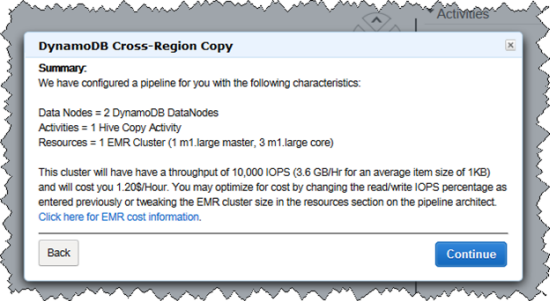
The usual AWS data transfer charges apply when you use this facility to copy data between DynamoDB tables.
Note that the AWS Data Pipeline is currently available in the US East (Northern Virginia) Region and you’ll have to launch it from there. It can, however, copy data between tables located in any of the public AWS Regions.
This feature is available now and you can start using it today!
— Jeff;