AWS News Blog
AWS For High Performance Cloud Computing – NASA, MATLAB
It is great to see our customers putting EC2’s new Cluster Compute instance type to use in High Performance Computing (HPC) scenarios. Here are two example applications:
MathWorks / MATLAB
![]() The MATLAB team at MathWorks tested performance scaling of the backslash (“\”) matrix division operator to solve for x in the equation A*x = b. In their testing, matrix A occupies far more memory (290 GB) than is available in a single high-end desktop machinetypically a quad core processor with 4-8 GB of RAM, supplying approximately 20 Gigaflops.
The MATLAB team at MathWorks tested performance scaling of the backslash (“\”) matrix division operator to solve for x in the equation A*x = b. In their testing, matrix A occupies far more memory (290 GB) than is available in a single high-end desktop machinetypically a quad core processor with 4-8 GB of RAM, supplying approximately 20 Gigaflops.
Therefore, they spread the calculation across machines. In order to solve linear systems of equations they need to be able to access all of the elements of the array even when the array is spread across multiple machines. This problem requires significant amounts of network communication, memory access, and CPU power. They scaled up to a cluster in EC2, giving them the ability to work with larger arrays and to perform calculations at up to 1.3 Teraflops, a 60X improvement. They were able to do this without making any changes to the application code.
Here’s a graph showing the near-linear scalability of an EC2 cluster across a range of matrix sizes with corresponding increases in cluster size for MATLAB’s parallel backslash operator:
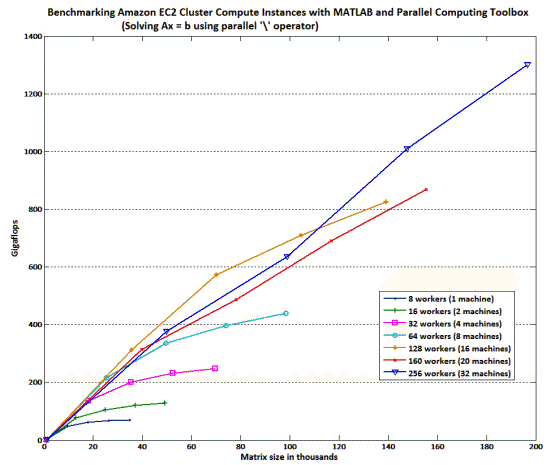
Each Cluster Compute instance runs 8 workers (one per processor core on 8 cores per instance). Each doubling of the worker count corresponds to a doubling of the number of Cluster Computer instances used (scaling from 1 up to 32 instances). They saw near-linear overall throughput (measured in Gigaflops on the y axis) while increasing the matrix size (the x axis) as they successively doubled the number of instances.
NASA JPL
![]() A team at NASA’s Jet Propulsion Laboratory developed the ATHLETE robot. Each year they put the robot through autonomous field tests as part of the D-RATS (Desert Research and Training Studies) along with autonomous robots from other NASA centers. The operators rely on high-resolution satellite imagery for situational awareness while driving the robots. JPL engineers recently developed and deployed an application designed to streamline the processing of large (giga-pixel) images by leveraging the massively parallel nature of the workflow. The application is built on Polyphony, a versatile and modular workflow framework based on Amazon SQS and Eclipse Equinox. In the past, JPL has used Polyphony to validate the utility of cloud computing for processing hundreds of thousands of small images in an EC2-based compute environment. JPLers have now adopted the cluster compute environments for processing of very large monolithic images. Recently, JPLers processed a 3.2 giga-pixel image of the field site (provided courtesy of USGS) in less than two hours on a cluster of 30 Cluster Compute Instances. This demonstrates a significant improvement (an order of magnitude) over previous implementations, on non-HPC environments.
A team at NASA’s Jet Propulsion Laboratory developed the ATHLETE robot. Each year they put the robot through autonomous field tests as part of the D-RATS (Desert Research and Training Studies) along with autonomous robots from other NASA centers. The operators rely on high-resolution satellite imagery for situational awareness while driving the robots. JPL engineers recently developed and deployed an application designed to streamline the processing of large (giga-pixel) images by leveraging the massively parallel nature of the workflow. The application is built on Polyphony, a versatile and modular workflow framework based on Amazon SQS and Eclipse Equinox. In the past, JPL has used Polyphony to validate the utility of cloud computing for processing hundreds of thousands of small images in an EC2-based compute environment. JPLers have now adopted the cluster compute environments for processing of very large monolithic images. Recently, JPLers processed a 3.2 giga-pixel image of the field site (provided courtesy of USGS) in less than two hours on a cluster of 30 Cluster Compute Instances. This demonstrates a significant improvement (an order of magnitude) over previous implementations, on non-HPC environments.
We’re happy to see MathWorks and JPL deploying Cluster Compute Instances with great results. It’s also exciting to see other customers scaling up to 128-node (1024 core) clusters with full bisection bandwidth. I’ll be writing up more of these stories in the near future, so stay tuned. If you have a story of your own, drop me an email or leave a comment.
— Jeff;