AWS News Blog
Now Available – Global Secondary Indexes for Amazon DynamoDB
As I promised a few weeks ago, Amazon DynamoDB now supports Global Secondary Indexes. You can now create indexes and perform lookups using attributes other than the item’s primary key. With this change, DynamoDB goes beyond the functionality traditionally provided by a key/value store, while retaining the scalability and performance benefits that have made it so popular with our customers.
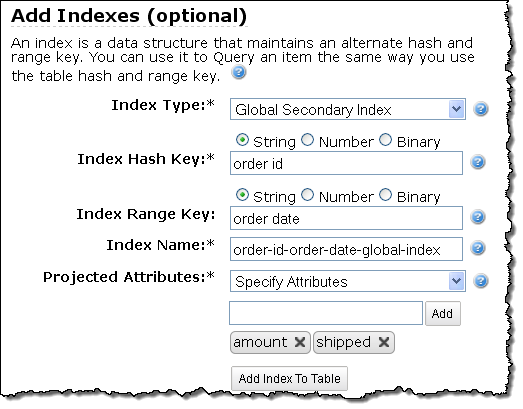
You can now create up to five Global Secondary Indexes when you create a table, each referencing either a hash key or a hash key and a range key. You can also create up to five Local Secondary Indexes, and you can choose to project some or all of the table’s attributes into each of the tables indexes.
Creating Global Secondary Indexes
The AWS Management Console now allows you to specify any desired Global Secondary Indexes when you create the table:
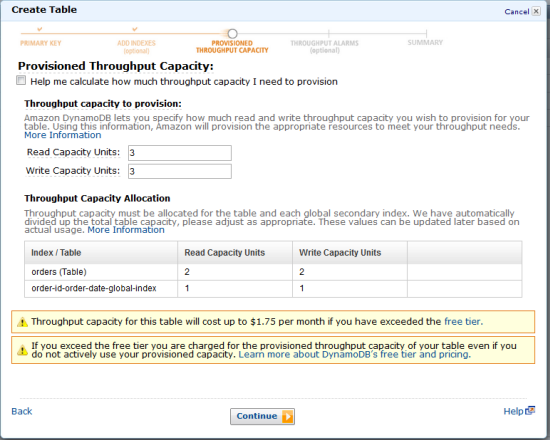
As part of the table creation process you can also provision throughput for the table and for each of the Global Secondary Indexes:
You can also create tables and the associated indexes using the AWS CLI or the DynamoDB APIs.
Local or Global
If you have been following the continued development of DynamoDB, you may recall that we launched Local Secondary Indexes earlier this year. You may be wondering why we support both models while also trying to decide where each one is appropriate.
 Let’s quickly review the DynamoDB table model before diving in. Each table has a specified attribute called a hash key. An additional range key attribute can also be specified for the table. The hash key and optional range key attribute(s) define the primary index for the table, and each item is uniquely identified by its hash key and range key (if defined). Items contain an arbitrary number of attribute name-value pairs, constrained only by the maximum item size limit. In the absence of indexes, item lookups require the hash key of the primary index to be specified.
Let’s quickly review the DynamoDB table model before diving in. Each table has a specified attribute called a hash key. An additional range key attribute can also be specified for the table. The hash key and optional range key attribute(s) define the primary index for the table, and each item is uniquely identified by its hash key and range key (if defined). Items contain an arbitrary number of attribute name-value pairs, constrained only by the maximum item size limit. In the absence of indexes, item lookups require the hash key of the primary index to be specified.
The Local and Global Index models extend the basic indexing functionality provided by DynamoDB. Lets consider some use cases for each model:
- Local Secondary Indexes are always queried with respect to the table’s hash key, combined with the range key specified for that index. In effect (as commenter Stuart Marshall made clear on the preannouncement post), Local Secondary Indexes provide alternate range keys. For example, you could have an Order History table with a hash key of customer id, a primary range key of order date, and a secondary index range key on order destination city. You can use a Local Secondary Index to find all orders delivered to a particular city using a simple query for a given customer id.
- Global Secondary Indexes can be created with a hash key different from the primary index; a single Global Secondary Index hash key can contain items with different primary index hash keys. In the Order History table example, you can create a global index on zip code, so that you can find all orders delivered to a particular zip code across all customers. Global Secondary Indexes allow you to retrieve items based on any desired attribute.
Both Global and Local Secondary Indexes allow multiple items for the same secondary key value.
Local Secondary Indexes support strongly consistent reads, allow projected and non-projected attributes to be retrieved via queries and share provisioned throughput capacity with the associated table. Local Secondary Indexes also have the additional constraint that the total size of data for a single hash key is currently limited to 10 gigabytes.
Global Secondary Indexes are eventually consistent, allow only projected attributes to be retrieved via queries, and have their own provisioned throughput specified separately from the associated table.
As I noted earlier, each Global Secondary Index has its own provisioned throughput capacity. By combining this feature with the ability to project selected attributes into an index, you can design your table and its indexes to support your application’s unique access patterns, while also tuning your costs. If your table is “wide” (lots of attributes) and an interesting and frequently used query requires a small subset of the attributes, consider projecting those attributes into a Global Secondary Index. This will allow the frequently accessed attributes to be fetched without expending read throughput on unnecessary attributes.
This feature is available now and you can start using it today!
— Jeff;