AWS for SAP
Run federated queries to an AWS data lake with SAP HANA
Harpreet Singh is a Solution Architect at Amazon Web Services (AWS).
An Aberdeen survey revealed that organizations who implemented a data lake outperformed similar companies by 9% in organic revenue growth. A data lake gives these companies the capability to get meaningful insights from their data, which helps them to take actions that differentiate them from the competition.
With its durability and cost effectiveness, Amazon Simple Storage Service (Amazon S3) offers a compelling reason for customers to use it as storage layer for a data lake on AWS. Many of these customers are deploying their SAP HANA–based applications on AWS and want to have the option of building analytics with data from SAP HANA and an Amazon S3–based data lake, while still using SAP HANA as the primary source for analytics.
There could be many scenarios for federating queries from SAP HANA to a data lake on AWS. Here are a few specific examples:
- Utilities industry: You can store consumption of electricity-relevant data in a data lake on AWS and federate queries from SAP HANA to predict future energy consumption.
- Retail industry: You can store social media activity about your company in a data lake on AWS, match the activity with customer tickets in SAP CRM for analysis, and improve customer satisfaction. Another example for the retail industry is analyzing data from an e-commerce website and inventory/stock in the SAP system.
- Pharma: You can perform recall analysis using archived inventory data from the data lake on AWS and current inventory data from the SAP system.
This blog provides steps for configuring SAP HANA to run federated queries to an Amazon S3–based data lake by using Amazon Athena.
Let’s look at the architecture first. Say you are using Amazon S3 as storage for a data lake that receives raw data from various data sources (for example, web applications, other databases, streaming data, other non-SAP systems, etc.) in an Amazon S3 bucket. Raw data is transformed via AWS Glue and is then stored in another Amazon S3 bucket in an Athena-supported format. AWS Glue crawlers catalog the transformed data. If you want to learn how to catalog data in AWS Glue, refer to this blog post.
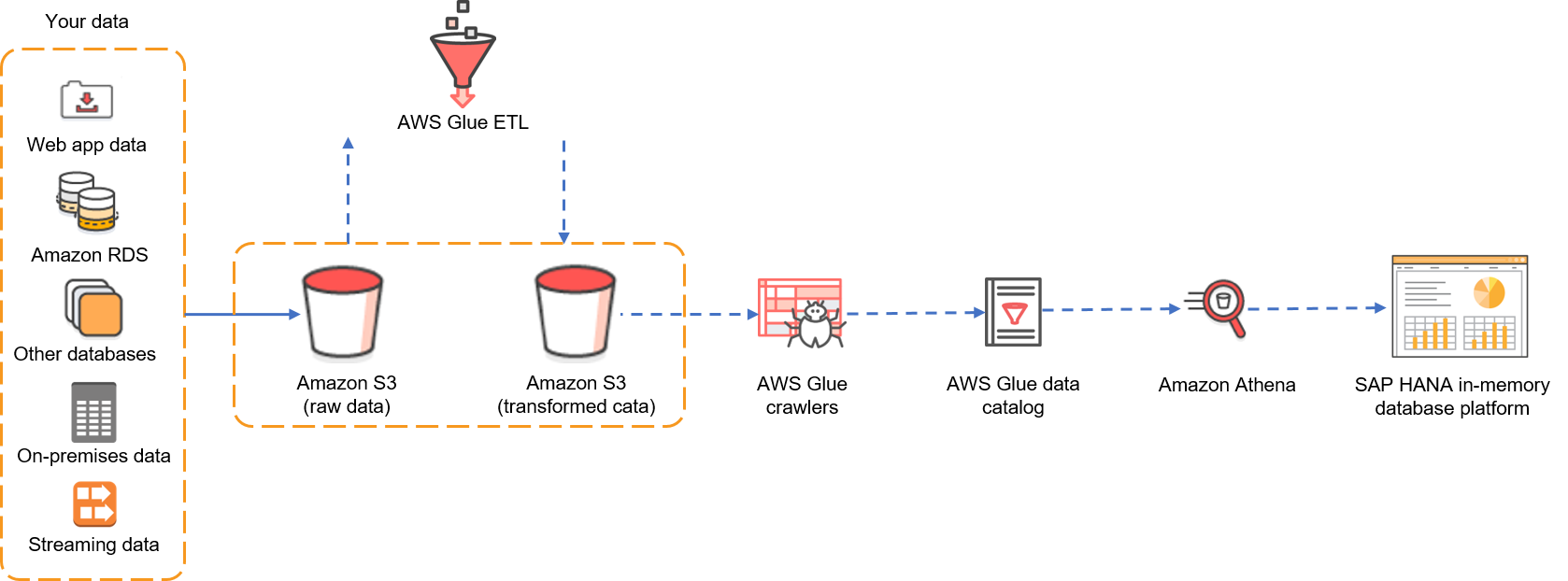
Figure 1: Data from multiple sources is stored in S3 and then returned, by using Athena, in federated queries from SAP HANA.
For this example, we will focus on federating queries from SAP HANA by using Athena. I have already crawled and cataloged a table containing open source e-commerce data. Here are the details:
- A CSV file, eCommerce-Data.csv, that contains sample sales records from an e-commerce site is available in the Transformed Data S3 bucket. This CSV contains sales record of various customers:

- AWS Glue crawls and catalogs the data that is in the Transformed Data S3 bucket and saves it in the ecommerce_data table in the database named ecommerce-database in AWS Glue.

- The database and table are now available in Athena, and we can execute SQL queries on this table by using Athena Query Editor.

Our objective is to federate queries from SAP HANA to this ecommerce_data table in ecommerce-database.
Now that we have set the context, let’s focus on the technical bits that are required for this setup.
- SAP HANA Smart Data Access (SDA), a powerful feature that has been available since HANA 1.0 SPS 6, enables you to perform data manipulation language (DML) statements on external data sources. You can create virtual tables in SAP HANA that point to tables in remote data sources. Refer to the SAP documentation for more details on SAP HANA SDA.
- Athena provides both JDBC and ODBC drivers, which can be used by other applications to query tables in Athena. SAP HANA SDA supports only the ODBC driver, so we will use the ODBC driver in this blog post.
Install and configure the Athena ODBC driver on the SAP HANA system
First, we need to install the Athena ODBC manager and ODBC driver on the SAP HANA System. (Refer to the SAP HANA Quick Start deployment guide for installing SAP HANA on AWS.)
In the steps below, we will assume SUSE Linux as the operating system (the steps are similar for RHEL). Detailed instructions for ODBC driver installation are available in the Symba Technologies ODBC driver installation and configuration guide.
1. Install the ODBC manager
You can install iODBC (version 3.52.7 or later) or unixODBC (version 2.3.0 or later). We will use unixODBC for this setup.
To install unixODBC on the SAP HANA system, execute as root the following command:
zypper install -y unixODBC

2. Install the Athena ODBC driver
Refer to connecting to Amazon Athena with ODBC for the latest RPM package URL. Then on the SAP HANA instance, execute as root the following commands, replacing the URL in the wget command and the file name in the zypper command:
mkdir AthenaODBC cd AthenaODBC wget https://s3.amazonaws.com/athena-downloads/drivers/ODBC/Linux/simbaathena-1.0.2.1003-1.x86_64.rpm zypper --no-gpg-checks install -y simbaathena-1.0.2.1003-1.x86_64.rpm

3. Attach the IAM policy for the SAP HANA instance
Assign the managed IAM policy AmazonAthenaFullAccess to the IAM role that is assigned to the SAP HANA instance. Refer to the Athena documentation for details.
You can copy this policy and customize it to meet your specific needs.

4. Configure the Athena ODBC driver
On your SAP HANA instance, log in as <sid>adm and switch to the home directory. Create .odbc.ini with the following content, replacing the highlighted values with your specific settings, where MyDSN is the name of the data source. (You can change it to any name you like.)
[Data Sources] MyDSN=Simba Athena ODBC Driver 64-bit [MyDSN] Driver=/opt/simba/athenaodbc/lib/64/libathenaodbc_sb64.so AuthenticationType=Instance Profile AwsRegion=<AWS Region where you want to use Athena> S3OutputLocation=s3://<tempbucket>/<folder>/
Here is an example:

I am using the AWS Sydney region, so I have used ap-southeast-2 as AwsRegion. I have already created an Amazon S3 bucket that contains the TempForSAPAthenaIntegration folder, which I have used as S3OutputLocation. Change these values to reflect your setup.
5. Configure the environment variable
As <sid>adm, create .customer.sh with the following content and change the permissions on this file to 700.
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/opt/simba/athenaodbc/lib/64/
export ODBCINI=$HOME/.odbc.ini

Exit from <sid>adm and log in again to check that the environment variable set in .customer.sh are effective (i.e., you can see the ODBCINI variable and changes to LD_LIBRARY_PATH):

Test Amazon Athena ODBC Driver
Now it’s time to test connectivity to Athena by using the ODBC driver that you installed in previous step. On your SAP HANA instance, as <sid>adm, execute the following command, replacing the highlighted text with the name of your data source.
isql <Data Source Name> -c -d,
In our example, we defined the data source name as MyDSN in odbc.ini, so we use that data source name here:

If you get an SQL prompt without any error, your ODBC driver has been configured successfully. However, let’s execute a query against the ecommerce_data table that I have in my environment to check that we are able to execute queries and get the results from Athena.

That’s great—all looks fine.
Configure SAP HANA
As mentioned previously, we will use SAP HANA SDA to connect to the Athena remote data source. We will configure the SAP HANA SDA Generic ODBC adapter for this connectivity.
1. Create the Athena property file
The SAP HANA SDA Generic ODBC adapter requires a configuration file that lists the capabilities of the remote data source. This property file needs to be created as root user in /usr/sap/<SID>/SYS/exe/hdb/config. We will call this file Property_Athena.ini (you can change this name), and we will create it with following content.
CAP_SUBQUERY : true CAP_ORDERBY : true CAP_JOINS : true CAP_GROUPBY : true CAP_AND : true CAP_OR : true CAP_TOP : false CAP_LIMIT : true CAP_SUBQUERY : true CAP_SUBQUERY_GROUPBY : true FUNC_ABS : true FUNC_ADD : true FUNC_ADD_DAYS : DATE_ADD(DAY,$2,$1) FUNC_ADD_MONTHS : DATE_ADD(MONTH,$2,$1) FUNC_ADD_SECONDS : DATE_ADD(SECOND,$2,$1) FUNC_ADD_YEARS : DATE_ADD(YEAR,$2,$1) FUNC_ASCII : true FUNC_ACOS : true FUNC_ASIN : true FUNC_ATAN : true FUNC_TO_VARBINARY : false FUNC_TO_VARCHAR : false FUNC_TRIM_BOTH : TRIM($1) FUNC_TRIM_LEADING : LTRIM($1) FUNC_TRIM_TRAILING : RTRIM($1) FUNC_UMINUS : false FUNC_UPPER : true FUNC_WEEKDAY : false TYPE_TINYINT : TINYINT TYPE_LONGBINARY : VARBINARY TYPE_LONGCHAR : VARBINARY TYPE_DATE : DATE TYPE_TIME : TIME TYPE_DATETIME : TIMESTAMP TYPE_REAL : REAL TYPE_SMALLINT : SMALLINT TYPE_INT : INTEGER TYPE_INTEGER : INTEGER TYPE_FLOAT : DOUBLE TYPE_CHAR : CHAR($PRECISION) TYPE_BIGINT : DECIMAL(19,0) TYPE_DECIMAL : DECIMAL($PRECISION,$SCALE) TYPE_VARCHAR : VARCHAR($PRECISION) TYPE_BINARY : VARBINARY TYPE_VARBINARY : VARBINARY PROP_USE_UNIX_DRIVER_MANAGER : true
2. Change the properties of Proprty_Athena.ini
After the file has been created, update its ownership to <sid>adm:sapsys, and change the permissions to 444:

3. Restart SAP HANA
We need to restart SAP HANA so that it starts with the environment variable that we previously set in .customer.sh.
4. Create the remote data source
Use SAP HANA studio to log in to SAP HANA, and follow the menu path to create a remote data source.

5. Define the properties of the remote source
Fill in the values for Source Name, Adapter Name, Connection Mode, Configuration file, Data Source Name, DML Mode, and your user name and password. For the user name and password, fill in any dummy values as this is not relevant because access is based on the Athena Role that is assigned to the Amazon Elastic Compute Cloud (Amazon EC2) instance. Ensure that the Configuration file name matches the name of the configuration file that you created (in our example, Property_Athena.ini) and that the data source name matches what you defined in .odbc.ini (in our example, MyDSN).
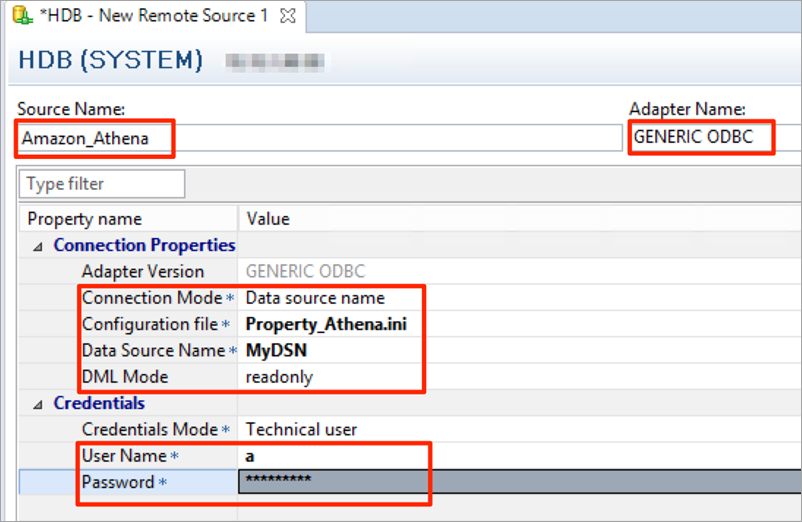
Then save (Ctrl+S), and confirm that the connection test completes successfully.
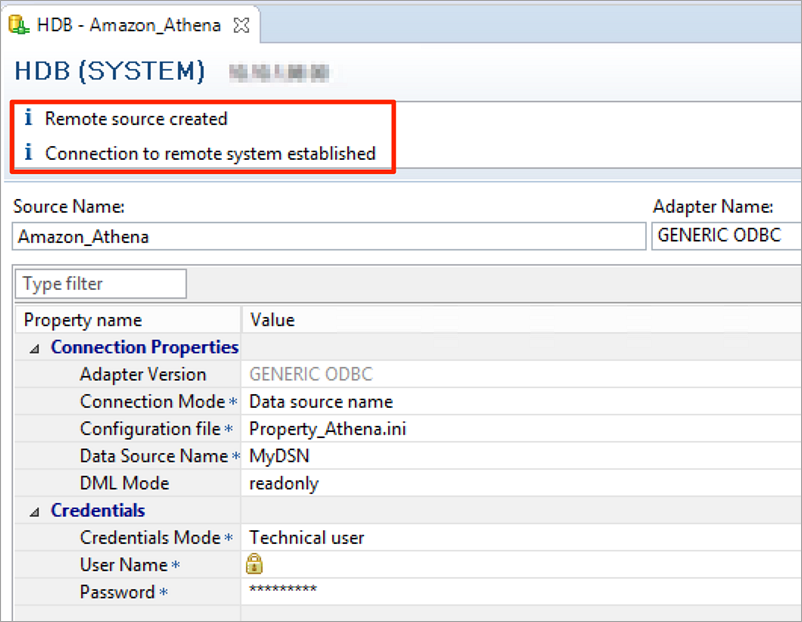
You can see that an Amazon_Athena remote data source has been created in SAP HANA, and you can expand it to see the database and table (ecommerce-database and ecommerce_data in my example).

6. Create a virtual table
The next step is to create a virtual table in SAP HANA that points to the table in the remote data source. Open the table name context (right-click) menu in the remote source, and choose Add as Virtual Table.
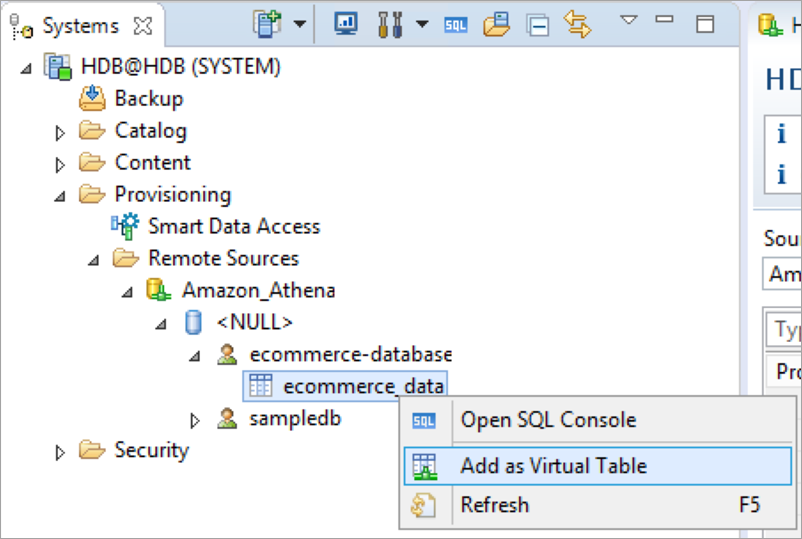
Enter a name for the virtual table and the schema in which virtual table needs to be defined. For example, I am creating the vir_ecommerce_data virtual table in the SYSTEM schema.

You can see the virtual table in the SYSTEM schema.
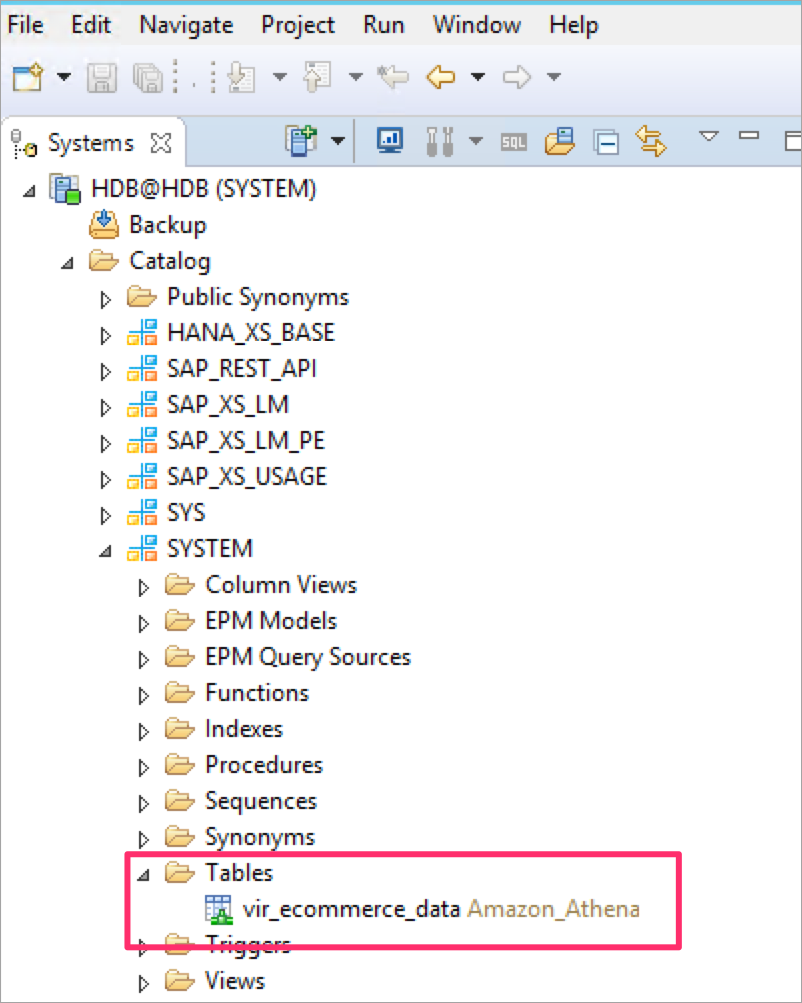
7. Execute queries on the virtual table
Open the SQL console and execute SQL queries on the virtual table. You should be able to get results.

8. Execute a query on the local and virtual tables
In SAP HANA, I have created a local table by the name of CUSTOMERMASTER that contains customer details.

We will filter a list of rows from the virtual table where CustomerID is listed in the CUSTOMERMASTER table:
select distinct C."FNAME", C."LNAME",V."customerid", V."country" from "CUSTOMERMASTER" as C, "vir_ecommerce_data" as "V" where V."customerid" = C."CUSTOMERID"
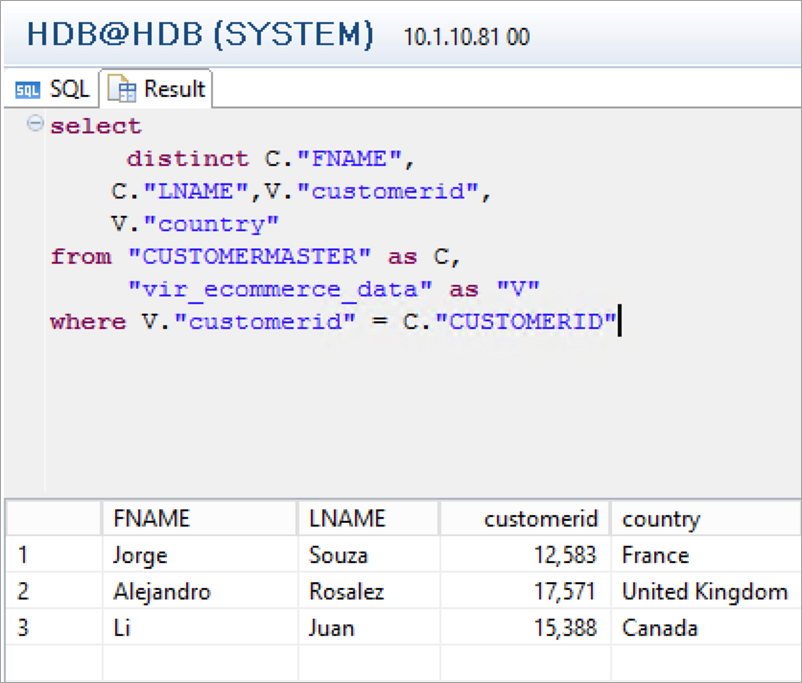
That’s all, we have successfully federated queries from SAP HANA to an Amazon S3–based data lake by using Athena.
Summary
We used the SAP HANA SDA feature and ODBC drivers from Amazon Athena to federate queries from SAP HANA to Athena. You can now combine data from SAP HANA with data that is available in an Amazon S3 data lake without needing to copy this data to SAP HANA first. Queries are executed by Athena and results are sent to SAP HANA.
Share with us how you have used Athena with SAP HANA or reach out to us with any questions. You can use AWS promotional credits to migrate your SAP systems to AWS. Contact us to find out how and to apply for credits.