AWS Big Data Blog
Category: Amazon EMR

Improve query performance using AWS Glue partition indexes
While creating data lakes on the cloud, the data catalog is crucial to centralize metadata and make the data visible, searchable, and queryable for users. With the recent exponential growth of data volume, it becomes much more important to optimize data layout and maintain the metadata on cloud storage to keep the value of data […]

Manage and process your big data workflows with Amazon MWAA and Amazon EMR on Amazon EKS
Many customers are gathering large amount of data, generated from different sources such as IoT devices, clickstream events from websites, and more. To efficiently extract insights from the data, you have to perform various transformations and apply different business logic on your data. These processes require complex workflow management to schedule jobs and manage dependencies […]

Amazon EMR introduces EMR runtime for Presto, providing a 2.6 times speedup
Presto is an open-source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto was designed and written from the ground up for interactive analytics, and approaches the speed of commercial data warehouses while scaling to the size of organizations like Facebook. Running Presto […]
Amazon EMR announces general availability of EMR Studio
At AWS re:Invent 2020, we announced the preview of Amazon EMR Studio, an integrated development environment (IDE) that makes it easy for data scientists and data engineers to develop, visualize, and debug applications written in R, Python, Scala, and PySpark. Today, we’re excited to announce the general availability of EMR Studio and new features we’ve […]
Build Slowly Changing Dimensions Type 2 (SCD2) with Apache Spark and Apache Hudi on Amazon EMR
April 2024: This post was reviewed for accuracy. Organizations across the globe are striving to improve the scalability and cost efficiency of the data warehouse. Offloading data and data processing from a data warehouse to a data lake empowers companies to introduce new use cases like ad hoc data analysis and AI and machine learning […]
Orchestrate an Amazon EMR on Amazon EKS Spark job with AWS Step Functions
At re:Invent 2020, we announced the general availability of Amazon EMR on Amazon EKS, a new deployment option for Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With Amazon EMR on EKS, you can now run Spark applications alongside other […]

Amazon EMR 6.2.0 adds persistent HFile tracking to improve performance with HBase on Amazon S3
Apache HBase is an open-source, NoSQL database that you can use to achieve low latency random access to billions of rows. Starting with Amazon EMR 5.2.0, you can enable HBase on Amazon Simple Storage Service (Amazon S3). With HBase on Amazon S3, the HBase data files (HFiles) are written to Amazon S3, enabling data lake […]
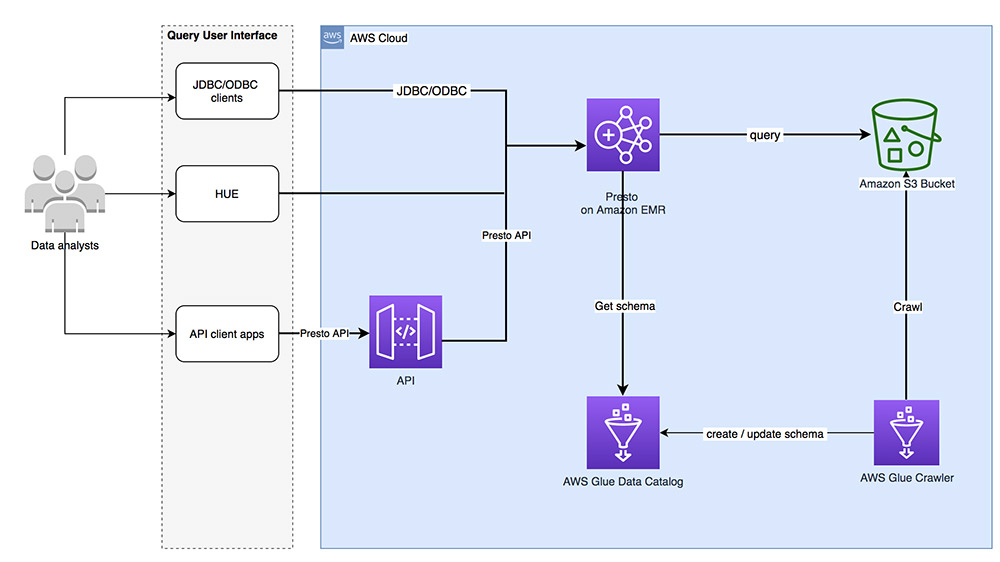
Top 9 performance tuning tips for PrestoDB on Amazon EMR
Presto is a popular distributed SQL query engine for interactive data analytics. With its massively parallel processing (MPP) architecture, it’s capable of directly querying large datasets without the need of time-consuming and costly ETL processes. With a properly tuned Presto cluster you can run fast queries against big data with response times ranging from subsecond […]
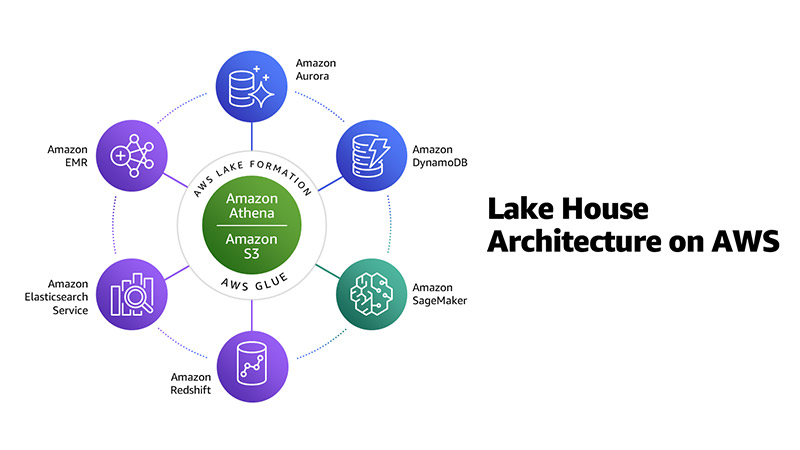
Amazon EMR 2020 year in review
Tens of thousands of customers use Amazon EMR to run big data analytics applications on Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto at scale. Amazon EMR automates the provisioning and scaling of these frameworks, and delivers high performance at low cost with optimized runtimes and support for a wide range […]

Orchestrating analytics jobs on Amazon EMR Notebooks using Amazon MWAA
May 2024: This post was reviewed and updated with a new dataset. In a previous post, we introduced the Amazon EMR notebook APIs, which allow you to programmatically run a notebook on Amazon EMR Studio (preview) without accessing the AWS web console. With the APIs, you can schedule running EMR notebooks with cron scripts, chain multiple notebooks, […]