AWS Big Data Blog
Get started with Apache Hudi using AWS Glue by implementing key design concepts – Part 1
Many organizations build data lakes on Amazon Simple Storage Service (Amazon S3) using a modern architecture for a scalable and cost-effective solution. Open-source storage formats like Parquet and Avro are commonly used, and data is stored in these formats as immutable files. As the data lake is expanded to additional use cases, there are still some use cases that are very difficult with data lakes, such as CDC (change data capture), time travel (querying point-in-time data), privacy regulation requiring deletion of data, concurrent writes, and consistency regarding handling small file problems.
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and streaming data ingestion. However, organizations new to data lakes may struggle to adopt Apache Hudi due to unfamiliarity with the technology and lack of internal expertise.
In this post, we show how to get started with Apache Hudi, focusing on the Hudi CoW (Copy on Write) table type on AWS using AWS Glue, and implementing key design concepts for different use cases. We expect readers to have a basic understanding of data lakes, AWS Glue, and Amazon S3. We walk you through common batch data ingestion use cases with actual test results using a TPC-DS dataset to show how the design decisions can influence the outcome.
Apache Hudi key concepts
Before diving deep into the design concepts, let’s review the key concepts of Apache Hudi, which is important to understand before you make design decisions.
Hudi table and query types
Hudi supports two table types: Copy on Write (CoW) and Merge on Read (MoR). You have to choose the table type in advance, which influences the performance of read and write operations.
The difference in performance depends on the volume of data, operations, file size, and other factors. For more information, refer to Table & Query Types.
When you use the CoW table type, committed data is implicitly compacted, meaning it’s updated to columnar file format during write operation. With the MoR table type, data isn’t compacted with every commit. As a result, for the MoR table type, compacted data lives in columnar storage (Parquet) and deltas are stored in a log (Avro) raw format until compaction merges changes the data to columnar file format. Hudi supports snapshot, incremental, and read-optimized queries for Hudi tables, and the output of the result depends on the query type.
Indexing
Indexing is another key concept for the design. Hudi provides efficient upserts and deletes with fast indexing for both CoW and MoR tables. For CoW tables, indexing enables fast upsert and delete operations by avoiding the need to join against the entire dataset to determine which files to rewrite. For MoR, this design allows Hudi to bound the amount of records any given base file needs to be merged against. Specifically, a given base file needs to be merged only against updates for records that are part of that base file. In contrast, designs without an indexing component could end up having to merge all the base files against all incoming update and delete records.
Solution overview
The following diagram describes the high-level architecture for our solution. We ingest the TPC-DS (store_sales) dataset from the source S3 bucket in CSV format and write it to the target S3 bucket using AWS Glue in Hudi format. We can query the Hudi tables on Amazon S3 using Amazon Athena and AWS Glue Studio Notebooks.

The following diagram illustrates the relationships between our tables.

For our post, we use the following tables from the TPC-DS dataset: one fact table, store_sales, and the dimension tables store, item, and date_dim. The following table summarizes the table row counts.
| Table | Approximate Row Counts |
| store_sales | 2.8 billion |
| store | 1,000 |
| item | 300,000 |
| date_dim | 73,000 |
Set up the environment
After you sign in to your test AWS account, launch the provided AWS CloudFormation template by choosing Launch Stack:
![]()
This template configures the following resources:
- AWS Glue jobs
hudi_bulk_insert,hudi_upsert_cow, andhudi_bulk_insert_dim. We use these jobs for the use cases covered in this post. - An S3 bucket to store the output of the AWS Glue job runs.
- AWS Identity and Access Management (IAM) roles and policies with appropriate permissions.
Before you run the AWS Glue jobs, you need to subscribe to the AWS Glue Apache Hudi Connector (latest version: 0.10.1). The connector is available on AWS Marketplace. Follow the connector installation and activation process from the AWS Marketplace link, or refer to Process Apache Hudi, Delta Lake, Apache Iceberg datasets at scale, part 1: AWS Glue Studio Notebook to set it up.

After you create the Hudi connection, add the connector name to all the AWS Glue scripts under Advanced properties.
Bulk insert job
To run the bulk insert job, choose the job hudi_bulk_insert on the AWS Glue console.
The job parameters as shown in the following screenshot are added as part of the CloudFormation stack setup. You can use different values to create CoW partitioned tables with different bulk insert options.

The parameters are as follows:
- HUDI_DB_NAME – The database in the AWS Glue Data Catalog where the catalog table is created.
- HUDI_INIT_SORT_OPTION – The options for
bulk_insertinclude GLOBAL_SORT, which is the default. Other options include NONE and PARTITION_SORT. - HUDI_TABLE_NAME – The table name prefix that you want to use to identify the table created. In the code, we append the sort option to the name you specify in this parameter.
- OUTPUT_BUCKET – The S3 bucket created through the CloudFormation stack where the Hudi table datasets are written. The bucket name format is <account number><bucket name>. The bucket name is the one given while creating the CloudFormation stack.
- CATEGORY_ID – The default for this parameter is ALL, which processes categories of test data in a single AWS Glue job. To test the parallel on the same table, change the parameter value to one of categories from 3, 5, or 8 for the dataset that we use for each parallel AWS Glue job.
Upsert job for the CoW table
To run the upsert job, choose the job hudi_upsert_cow on the AWS Glue console.
The following job parameters are added as part of the CloudFormation stack setup. You can run upsert and delete operations on CoW partitioned tables with different bulk insert options based on the values provided for these parameters.
- OUTPUT-BUCKET – The same value as the previous job parameter.
- HUDI_TABLE_NAME – The name of the table created in your AWS Glue Data Catalog.
- HUDI_DB_NAME – The same value as the previous job parameter. The default value is Default.

Bulk insert job for the Dimension tables
To test the queries on the CoW tables, the fact table that is created using the bulk insert operation needs supplemental dimensional tables. This AWS Glue job has to be run before you can test the TPC queries provided later in this post. To run this job, choose hudi_bulk_insert_dim on the AWS Glue console and use the parameters shown in the following screenshot.

The parameters are as follows:
- OUTPUT-BUCKET – The same value as the previous job parameter.
- HUDI_INIT_SORT_OPTION – The options for
bulk_insertinclude GLOBAL_SORT, which is the default. Other available options are NONE and PARTITION_SORT. - HUDI_DB_NAME – The Hudi database name. Default is the default value.
Hudi design considerations
In this section, we walk you through a few use cases to demonstrate the difference in the outcome for different settings and operations.
Data migration use case
In Apache Hudi, you ingest the data into CoW or MoR tables types using either insert, upsert, or bulk insert operations. Data migration initiatives often involve one-time initial loads into the target datastore, and we recommend using the bulk insert operation for initial loads.
The bulk insert option provides the same semantics as insert, while implementing a sort-based data writing algorithm, which can scale very well for several hundred TBs of initial load. However, this just does a best-effort job at sizing files vs. guaranteeing file sizes like inserts and upserts do. Also, the primary keys aren’t sorted during the insert, therefore it’s not advised to use insert during the initial data load. By default, a Bloom index is created for the table, which enables faster lookups for upsert and delete operations.
Bulk insert has the following three sort options, which have different outcomes.
- GLOAL_SORT – Sorts the record key for the entire dataset before writing.
- PARTITION_SORT – Applies only to partitioned tables. In this option, the record key is sorted within each partition, and the insert time is faster than the default sort.
- NONE – Doesn’t sort data before writing.
For testing the bulk insert with the three sort options, we use the following AWS Glue job configuration, which is part of the script hudi_bulk_insert:
- AWS Glue version: 3.0
- AWS Glue worker type: G1.X
- Number of AWS Glue workers: 200
- Input file: TPC-DS/2.13/1TB/store_sales
- Input file format: CSV (TPC-DS)
- Number of input files: 1,431
- Number of rows in the input dataset: Approximately 2.8 billion
The following charts illustrate the behavior of the bulk insert operations with GLOBAL_SORT, PARTITION_SORT, and NONE as sort options for a CoW table. The statistics in the charts are created by using an average of 10 bulk insert operation runs for each sort option.

Because bulk insert does a best-effort job to pack the data in files, you see a different number of files created with different sort options.

We can observe the following:
- Bulk insert with
GLOBAL_SORThas the least number of files, because Hudi tried to create the optimal sized files. However, it takes the most time. - Bulk insert with
NONEas the sort option has the fastest write time, but resulted in a greater number of files. - Bulk insert with
PARTITION_SORTalso has a faster write time compared to GLOBAL SORT, but also results in a greater number of files.
Based on these results, although GLOBAL_SORT takes more time to ingest the data, it creates a smaller number of files, which has better upsert and read performance.
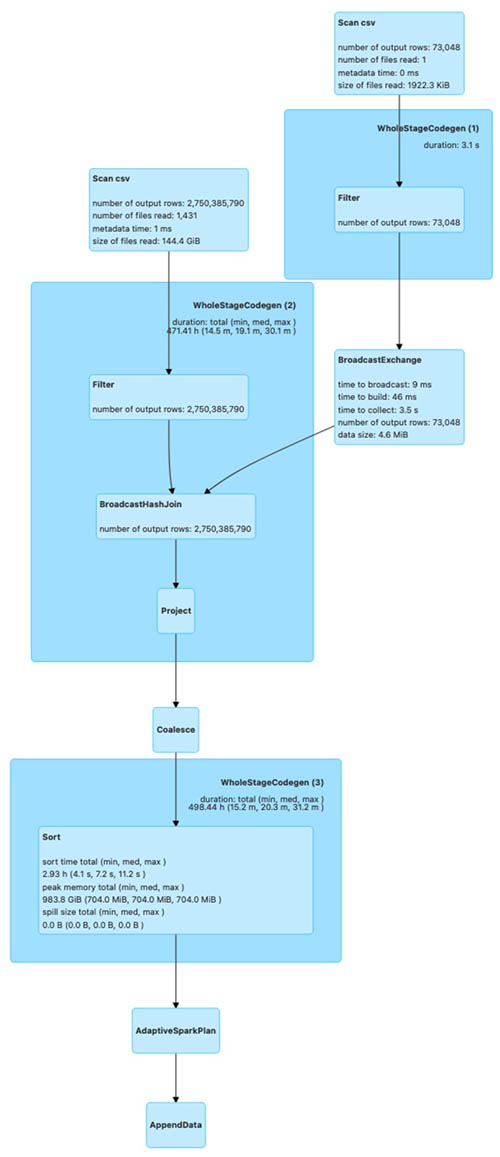
The following diagrams illustrate the Spark run plans for the bulk_insert operation using various sort options.
The first shows the Spark run plan for bulk_insert when the sort option is PARTITION_SORT.
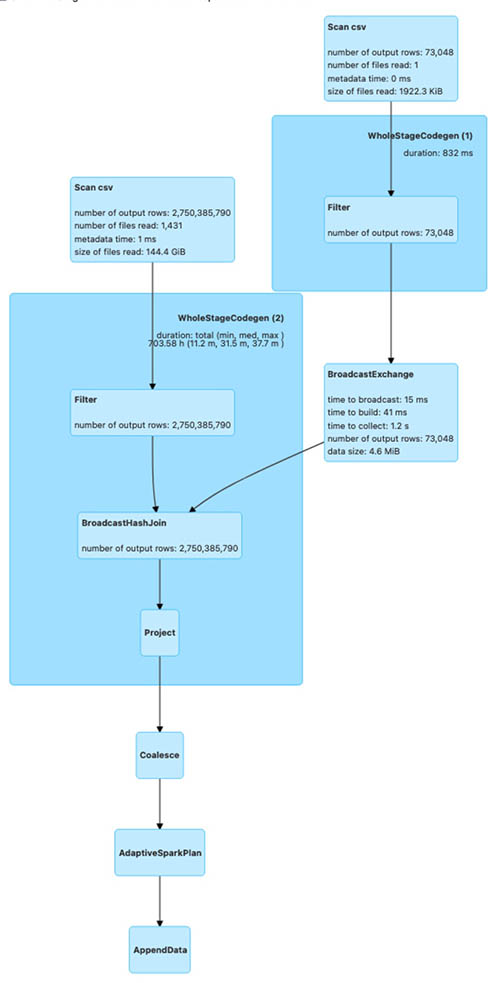
The next is the Spark run plan for bulk_insert when the sort option is NONE.
The last is the Spark run plan for bulk_insert when the sort option is GLOBAL_SORT.

The Spark run plan for bulk_insert with GLOBAL_SORT involves shuffling of data to create optimal sized files. For the other two sort options, data shuffling isn’t involved. As a result, bulk_insert with GLOBAL_SORT takes more time compared to the other sort options.
To test the bulk insert with various bulk insert sort data options on a partitioned table, modify the Hudi AWS Glue job (hudi_bulk_insert) parameter --HUDI_INIT_SORT_OPTION.

We change the parameter --HUDI_INIT_SORT_OPTION to PARTITION_SORT or NONE to test the bulk insert with different data sort options. You need to run the job hudi_bulk_insert_dim, which loads the rest of the tables needed to test the SQL queries.
Now, look at the query performance difference between these three options. For query runtime, we ran two TPC-DS queries (q52.sql and q53.sql, as shown in the following query snippets) using interactive session with AWS Glue Studio Notebook with the following notebook configuration to compare the results.
- AWS Glue version: 3.0
- AWS Glue worker type: G1.X
- Number of AWS Glue workers: 50
Before executing the following queries, replace the table names in the queries with the tables you generate in your account.
q52
SELECT
dt.d_year,
item.i_brand_id brand_id,
item.i_brand brand,
sum(ss_ext_sales_price) ext_price
FROM date_dim dt, store_sales, item
WHERE dt.d_date_sk = store_sales.ss_sold_date_sk
AND store_sales.ss_item_sk = item.i_item_sk
AND item.i_manager_id = 1
AND dt.d_moy = 11
AND dt.d_year = 2000
GROUP BY dt.d_year, item.i_brand, item.i_brand_id
ORDER BY dt.d_year, ext_price DESC, brand_id
LIMIT 100
SELECT *
FROM
(SELECT
i_manufact_id,
sum(ss_sales_price) sum_sales,
avg(sum(ss_sales_price))
OVER (PARTITION BY i_manufact_id) avg_quarterly_sales
FROM item, store_sales, date_dim, store
WHERE ss_item_sk = i_item_sk AND
ss_sold_date_sk = d_date_sk AND
ss_store_sk = s_store_sk AND
d_month_seq IN (1200, 1200 + 1, 1200 + 2, 1200 + 3, 1200 + 4, 1200 + 5, 1200 + 6,
1200 + 7, 1200 + 8, 1200 + 9, 1200 + 10, 1200 + 11) AND
((i_category IN ('Books', 'Children', 'Electronics') AND
As you can see in the following chart, the performance of the GLOBAL_SORT table outperforms NONE and PARTITION_SORT due to a smaller number of files created in the bulk insert operation.

Ongoing replication use case
For ongoing replication, updates and deletes usually come from transactional databases. As you saw in the previous section, the bulk operation with GLOBAL_SORT took the most time and the operation with NONE took the least time. When you anticipate a higher volume of updates and deletes on an ongoing basis, the sort option is critical for your write performance.
To illustrate the ongoing replication using Apache Hudi upsert and delete operations, we tested using the following configuration:
- AWS Glue version: 3.0
- AWS Glue worker type: G1.X
- Number of AWS Glue workers: 100
To test the upsert and delete operations, we use the store_sales CoW table, which was created using the bulk insert operation in the previous section with all three sort options. We make the following changes:
- Insert data into a new partition (month 1 and year 2004) using the existing data from month 1 of year 2002 with a new primary key; total of 32,164,890 records
- Update the
ss_list_pricecolumn by $1 for the existing partition (month 1 and year 2003); total of 5,997,571 records - Delete month 5 data for year 2001; total of 26,997,957 records
-
The following chart illustrates the runtimes for the upsert operation for the CoW table with different sort options used during the bulk insert.

As you can see from the test run, the runtime of the upsert is higher for NONE and PARTITION_SORT CoW tables. The Bloom index, which is created by default during the bulk insert operation, enables faster lookup for upsert and delete operations.
To test the upsert and delete operations on a CoW table for tables with different data sort options, modify the AWS Glue job (hudi_upsert_cow) parameter HUDI_TABLE_NAME to the desired table, as shown in the following screenshot.

For workloads where updates are performed on the most recent partitions, a Bloom index works fine. For workloads where the update volume is less but the updates are spread across partitions, a simple index is more efficient. You can specify the index type while creating the Hudi table by using the parameter hoodie.index.type. Both the Bloom index and simple index enforce uniqueness of table keys within a partition. If you need uniqueness of keys for the entire table, you must create a global Bloom index or global simple index based on the update workloads.
Multi-tenant partitioned design use case
In this section, we cover Hudi optimistic concurrency using a multi-tenant table design, where each tenant data is stored in a separate table partition. In a real-world scenario, you may encounter a business need to process different tenant data simultaneously, such as a strict SLA to make the data available for downstream consumption as quickly as possible. Without Hudi optimistic concurrency, you can’t have concurrent writes to the same Hudi table. In such a scenario, you can speed up the data writes using Hudi optimistic concurrency when each job operates on a different table dataset. In our multi-tenant table design using Hudi optimistic concurrency, you can run concurrent jobs, where each job writes data to a separate table partition.
For AWS Glue, you can implement Hudi optimistic concurrency using an Amazon DynamoDB lock provider, which was introduced with Apache Hudi 0.10.0. The initial bulk insert script has all the configurations needed to allow multiple writes. The role being used for AWS Glue needs to have DynamoDB permissions added to make it work. For more information about concurrency control and alternatives for lock providers, refer to Concurrency Control.
To simulate concurrent writes, we presume your tenant is based on the category field from the TPC DC test dataset and accordingly partitioned based on the category id field (i_category_id). Let’s modify the script hudi_bulk_insert to run an initial load for different categories. You need to configure your AWS Glue job to run concurrently based on the Maximum concurrency parameter, located under the advanced properties. We describe the Hudi configuration parameters that are needed in the appendix at the end of this post.

The TPC-DS dataset includes data from years 1998–2003. We use i_catagory_id as the tenant ID. The following screenshot shows the distribution of data for multiple tenants (i_category_id). In our testing, we load the data for i_category_id values 3, 5, and 8.

The AWS Glue job hudi_bulk_insert is designed to insert data into specific partitions based on the parameter CATEGORY_ID. If bulk insert job for dimension tables is not run before you need to run the job hudi_bulk_insert_dim, which loads the rest of the tables needed to test the SQL queries.
Now we run three concurrent jobs, each with respective values 3, 5, and 8 to simulate concurrent writes for multiple tenants. The following screenshot illustrates the AWS Glue job parameter to modify for CATEGORY_ID.

We used the following AWS Glue job configuration for each of the three parallel AWS Glue jobs:
- AWS Glue version: 3.0
- AWS Glue worker type: G1.X
- Number of AWS Glue workers: 100
- Input file: TPC-DS/2.13/1TB/store_sales
- Input file format: CSV (TPC-DS)
The following screenshot shows all three concurrent jobs started around the same time for three categories, which loaded 867 million rows (50.1 GB of data) into the store_sales table. We used the GLOBAL_SORT option for all three concurrent AWS Glue jobs.

The following screenshot shows the data from the Hudi table where all three concurrent writers inserted data into different partitions, which is illustrated by different colors. All the AWS Glue jobs were run in US Central Time zone (UTC -5). The _hoodie_commit_time is in UTC.

The first two results highlighted in blue corresponds to the AWS Glue job CATEGORY_ID = 3, which had the start time of 09/27/2022 21:23:39 US CST (09/28/2022 02:23:39 UTC).
The next two results highlighted in green correspond to the AWS Glue job CATEGORY_ID = 8, which had the start time of 09/27/2022 21:23:50 US CST (09/28/2022 02:23:50 UTC).
The last two results highlighted in green correspond to the AWS Glue job CATEGORY_ID = 5, which had the start time of 09/27/2022 21:23:44 US CST (09/28/2022 02:23:44 UTC).
The sample data from the Hudi table has _hoodie_commit_time values corresponding to the AWS Glue job run times.
As you can see, we were able to load data into multiple partitions of the same Hudi table concurrently using Hudi optimistic concurrency.
Key findings
As the results show, bulk_insert with GLOBAL_SORT scales well for loading TBs of data in the initial load process. This option is recommended for use cases that require frequent changes after a large migration. Also, when query performance is critical in your use case, we recommend the GLOBAL_SORT option because of the smaller number of files being created with this option.
PARTITION_SORT has better performance for data load compared to GLOBAL_SORT, but it generates a significantly larger number of files, which negatively impacts query performance. You can use this option when the query involves a lot of joins between partitioned tables on record key columns.
The NONE option doesn’t sort the data, but it’s useful when you need the fastest initial load time and requires minimal updates, with the added capability of supporting record changes.
Clean up
When you’re done with this exercise, complete the following steps to delete your resources and stop incurring costs:
- On the Amazon S3 console, empty the buckets created by the CloudFormation stack.
- On the CloudFormation console, select your stack and choose Delete.
This cleans up all the resources created by the stack.
Conclusion
In this post, we covered some of the Hudi concepts that are important for design decisions. We used AWS Glue and the TPC-DS dataset to collect the results of different use cases for comparison. You can learn from the use cases covered in this post to make the key design decisions, particularly when you’re at the early stage of Apache Hudi adoption. You can go through the steps in this post to start a proof of concept using AWS Glue and Apache Hudi.
References
- Build a serverless pipeline to analyze streaming data using AWS Glue, Apache Hudi, and Amazon S3
- Writing to Apache Hudi tables using AWS Glue Custom Connector
- Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi
Appendix
The following table summarizes the Hudi configuration parameters that are needed.
| Configuration | Value | Description | Required |
| hoodie.write.
concurrency.mode |
optimistic_concurrency_control |
Property to turn on optimistic concurrency control. | Yes |
| hoodie.cleaner.
policy.failed.writes |
LAZY |
Property to turn on optimistic concurrency control. | Yes |
| hoodie.write.
lock.provider |
org.apache.
|
Lock provider implementation to use. | Yes |
| hoodie.write.
lock.dynamodb.table |
<String> |
The DynamoDB table name to use for acquiring locks. If the table doesn’t exist, it will be created. You can use the same table across all your Hudi jobs operating on the same or different tables. | Yes |
| hoodie.write.
lock.dynamodb.partition_key |
<String> |
The string value to be used for the locks table partition key attribute. It must be a string that uniquely identifies a Hudi table, such as the Hudi table name. | Yes: ‘tablename’ |
| hoodie.write.
lock.dynamodb.region |
<String> |
The AWS Region in which the DynamoDB locks table exists, or must be created. | Yes:
Default: us-east-1 |
| hoodie.write.
lock.dynamodb.billing_mode |
<String> |
The DynamoDB billing mode to be used for the locks table while creating. If the table already exists, then this doesn’t have an effect. | Yes: Default
PAY_PER_REQUEST |
| hoodie.write.
lock.dynamodb.endpoint_url |
<String> |
The DynamoDB URL for the Region where you’re creating the table. | Yes: dynamodb.us-east-1.amazonaws.com |
| hoodie.write.
lock.dynamodb.read_capacity |
<Integer> |
The DynamoDB read capacity to be used for the locks table while creating. If the table already exists, then this doesn’t have an effect. | No: Default 20 |
| hoodie.write.
lock.dynamodb. write_capacity |
<Integer> |
The DynamoDB write capacity to be used for the locks table while creating. If the table already exists, then this doesn’t have an effect. | No: Default 10 |
About the Authors
 Amit Maindola is a Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
 Srinivas Kandi is a Data Architect with focus on data lake and analytics at Amazon Web Services. He helps customers to deploy data analytics solutions in AWS to enable them with prescriptive and predictive analytics.
Srinivas Kandi is a Data Architect with focus on data lake and analytics at Amazon Web Services. He helps customers to deploy data analytics solutions in AWS to enable them with prescriptive and predictive analytics.
 Mitesh Patel is a Principal Solutions Architect at AWS. His main area of depth is application and data modernization. He helps customers to build scalable, secure and cost effective solutions in AWS.
Mitesh Patel is a Principal Solutions Architect at AWS. His main area of depth is application and data modernization. He helps customers to build scalable, secure and cost effective solutions in AWS.