Containers
Application first delivery on Kubernetes with Open Application Model
This post was co-written with Daniel Higuero, CTO, Napptive
Introduction
In the era of cloud-native applications, Kubernetes has emerged as a prominent technology in the container orchestration space. However, using Kubernetes requires users to not only run and manage cluster configurations, cluster-wide add-ons, and auxiliary tooling, but also to understanding application deployment configurations (e.g., Deployments, Service, Ingress, Horizontal Pod Autoscaling [HPA], LimitRanges, and more). While this provides great flexibility for building a platform for running your applications on, it is a non-trivial task to fully understand, maintain, and run in production. What we typically hear from customers is that these types of concerns — building and running an application platform on top of Kubernetes — typically falls on one team. While the name of the team may be different depending on who you ask, we’ll call the people in this team platform engineers in this post. While their operational model and responsibilities (i.e., they build something that they also operate or they build templates that can be re-used by others) can be different, their objective typically is the same, which is building a platform that can be easily consumed by internal customers and application developers.
Application developers on the other hand, are responsible for building the business logic and features that provide value to their end users, but not necessarily understanding the ins and outs of Kubernetes (e.g., how to properly configure an Ingress object in detail). Preferably, these teams would like to provide only the minimal configuration required for their application to run, such as what port it should listen to, which container image to use, or what metrics and thresholds should be used to configure their alarms.
Both of these personas are builders. They build products that’re exposed to their internal or external customers. In a production environment, what they build needs to be stable, and able to evolve to meet customer expectations over time.
Solution overview
Reducing bi-directional organizational dependencies
One way of helping application developers is to introduce organizational standards through abstractions. The tricky part is to get these abstractions right. While Kubernetes itself provides abstractions of some application resources, storage, and compute, we believe this abstraction often is still too low-level for both platform and application developers to be efficient. Let’s expand a bit on that statement by providing an example: imagine a scenario where the platform team exposes raw Kubernetes API’s to their customers (i.e., application teams), and a change needs to be rolled out. Perhaps it’s related to a new Kubernetes version, such as the API group change of the Ingress object in Kubernetes v1.22 outlined in the Kubernetes deprecated API migration guide. If we take Ingress objects as an example, the networking.k8s.io/v1beta1 API Version was deprecated in Kubernetes 1.22, and users needed to change their Ingress definitions to networking.k8s.io/v1. That change introduced a dependency between the platform team and all of their customers, because they would need to change their configuration to align with the new API versions. It also means that before the platform team can upgrade their Kubernetes clusters, with every single one of their customers needing to use the new version of the API.

This example of bi-directional dependency between teams is usually a one-to-many relationship between the platform team and application teams that could lead to a scenario where you can’t upgrade Kubernetes. Upgrading Kubernetes could break your customers applications and you end up in a scenario where you are lagging behind on Kubernetes version upgrades, which puts you at risk of falling outside the supported lifecycle (see Amazon EKS Kubernetes release version calendar) and stop receiving critical updates.
Platform as a product
One way of solving challenges like the scenario presented previously is to create your own abstraction layer. You can think of this in the same way as you would think of building an API for a service. You would want that API to be stable, small, and not leak details about which underlying database engine you are using, as that is not of concern to the users of your API. By exposing a smaller set of well-defined configuration options to your application teams through an interface that you own, you no longer leak the details of the underlying implementation (Kubernetes in this case) to your customers, and are able to implement improvements and features faster. To build on the previous example, such platform improvement could be moving from the traditional approach of exposing services using Service and Ingress toward Kubernetes Gateway API to expose your services.
Open Application Model (OAM)
While you can achieve the aforementioned abstractions in different ways, this post discusses the Open Application Model (OAM) as a way to standardize the abstraction the deployment configuration for the application’s components. This might sound a bit like abstractions on top of abstractions, and while it is, bear in mind that these abstractions serve a purpose for the persona consuming the abstraction. Kubernetes serves as an abstraction for consuming underlying infrastructure resources for platform engineers building the platform and OAM serves as an abstraction layer for application developers consuming the platform built by the platform engineering team.
The OAM is an open-source specification for building cloud-native applications. It provides a declarative way to define the components of an application, including its services, configuration, and dependencies. The OAM enables developers to create portable applications that can be easily deployed across different platform versions without the need for significant modifications. It also provides a framework for managing the application’s lifecycle, including deployment, scaling, and updates. The OAM’s flexibility and interoperability make it a powerful tool for modern application development in the cloud. The OAM specification is designed to be extensible, which allows for the addition of new components and features as needed. It is also agnostic in the sense that it can be used with any platform that supports the OAM specification. The model defines an Application as a collection of services that are deployed together to accomplish a functional purpose.
KubeVela
KubeVela is an open-source project, which implements the Open Application Model discussed above. It is defined as a delivery process for building, deploying, and managing applications on Kubernetes. It provides a high-level programming model that enables developers to define the components of an application and their relationships in a declarative way. KubeVela’s model-driven approach removes much of the complexity associated with Kubernetes, which allows developers to focus on writing code rather than managing infrastructure. KubeVela also provides a powerful deployment engine that can orchestrate multiple components of an application and perform rolling updates, rollbacks, and canary releases. KubeVela’s flexibility and ease of use make it a good choice for developers who want to build cloud-native applications with Kubernetes without the need for deep Kubernetes expertise.
An Application in KubeVela is composed of the following elements:
- Components: Describe functional elements of the application, typically associated with a backend micro service. Different component types provide support for both long running processes, such as a backend service listening for incoming requests or short-lived ones such as periodic backup tasks.
- Traits: A trait can be associated with a component to augment or modify the underlying functionality of a component. For example, a trait may be used to export the component logs to another subsystem, create additional elements that expose the component to the Internet, or add configuration options for its execution. A component can be associated with as many traits as required.
- Policies: Similar to traits, they offer a method to apply application-level configuration options that affect all components.
- Workflows: Enable developers to define how the application should be deployed, which makes use of individual workflow steps that enable multiple types of actions from deploying components to communicating with other services.
The following diagram taken from the KubeVela documentation site:
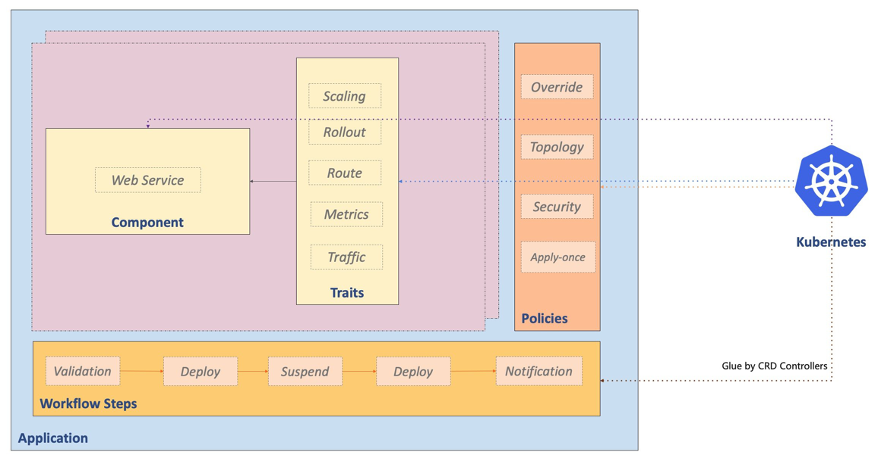
source: https://kubevela.io/docs/getting-started/core-concept
With that approach, the platform team can create the abstraction layer for application team to consume that holds all the low-level configurations of the component, such as: pods, Ingress, infrastructure controllers’ resources (such as AWS Controllers for Kubernetes [ACK] or Crossplane), and more. The application team is responsible for the complete lifecycle of that components, which includes creation, upgrades, and deletion. In its simplest example, this kind of abstraction can be seen in the following diagram:

The Platform team is responsible for domain specific configuration in Kubernetes such as Deployment configuration, Pod Topology Spread Constraints, Ingress or Service definition (based on protocol or other parameters), and other type of Kubernetes objects and configurations. The Application team is responsible for creating a very lightweight configuration that represents the entire application. As a result of using Kubevela Components and Traits abstractions, Application teams don’t need to be highly experienced configuring Kubernetes objects and their configurations.
As you’ll see in the following hands-on example, a single application with minimal configuration results in the following objects: Ingress or Service, HPA (for autoscaling), and Deployment. All of this without even needing to know what a Kubernetes deployment is.
Walkthrough
What are we going to build?
To demonstrate the value of OAM and Kubevela, we’ll use a sample application combined of a frontend component and a backend component. Together, those services represent an application. Application developers don’t need to know about Kubernetes and can instead use the standardized OAM model implemented by KubeVela, so that the Kubernetes Object configuration (Deployment, Ingress, ConfigMap, etc.) are simplified. Application developers use this OAM-based components to deploy their application to Kubernetes clusters.
Prerequisites
Before we begin, you need the following prerequisites:
- Amazon Command Line Interface (AWS CLI)
- Kubectl
- A running Amazon Elastic Kubernetes Service (Amazon EKS) cluster
- AWS Load Balancer Controller installed. See this guide
- vela CLI (for KubeVela user interface (UI))
- A GitHub account to host your application code and configuration files (if using GitOps approach)
In this section, we demonstrate the steps required to implement the OAM using KubeVela on Amazon EKS.
Bootstrap your environment with KubeVela
As a first step, lets deploy KubeVela, the open-source framework for building and deploying cloud-native applications on Kubernetes using the OAM. Install KubeVela on your Amazon EKS cluster as shown in the following commands:
These commands create a new namespace called vela-system and installs the latest version of KubeVela on your Amazon EKS cluster. Once installed, you can use KubeVela to define and deploy OAM applications. The following command can be used if you want to enable the KubeVela Dashboard.
To access the Dashboard, use the following command:
Navigate to the browser and access the following dashboard. Register and set up a user and password for an administrative role.

Deploy applications with KubeVela
As noted above, the application consists of two micro services. To deploy the micro services, application teams no longer have to learn the Kubernetes deployment configuration. This is where the OAM comes in.
Instead of deploying multiple Kubernetes objects, while having the appropriate knowledge level to configure all of them, a developer might define their application high level abstraction as follows:
Let’s cover what our Application manifest consists of. It has two components: frontend and backend. Those components are of type webservice. This is one of the built-in component types that comes with the KubeVela installation. You can create your own implementation of components that’re aligned to your organizational standards and defaults. Within each component, we can see the traits defined. Each trait has its own implementation and for demonstration purposes, we used two different autoscaling and ENV traits. Remember, this way of combining components and traits is so we can later change or extend the underlying implementation of the trait, such as switching the metrics backend to something different, as long as we adhere to the API defined by the trait. This is without changing the way we couple components and traits together.
Since KubeVela adds default labels to all the objects it creates, we can get all of the relevant objects of our web-app Application. Let’s examine what objects were created for our application by running the following command in your terminal:
As you can see, we have two services, two deployments, and one Horizontal Pod Autoscaling.
In simple terms, each object is associated with a particular component based on the value of the app.oam.dev/component label. KubeVela and the Open OAM enable Platform teams to create higher-level concepts and combine them into more advanced structures. These structures can then be used by Application teams.
We can also test that our application is running by setting up port-forwarding our frontend service:
You can then visit http://localhost:3000 in the browser to see that the application is running:

Cleaning up
You can clean up the applications, components, and traits using the following commands:
Optionally, you can delete the Amazon EKS cluster you’ve created by following this documentation page.
Conclusion
In this post, we showed you how to implement the OAM using KubeVela. The OAM provides a standardized approach to building and deploying cloud-native applications on Kubernetes. By using abstractions in the OAM and KubeVela, you can simplify the process of building and deploying cloud-native applications on Kubernetes for developers, which gives them the freedom to focus on delivering value to customers.
If you’re interested in the concepts introduced in this blog post, please feel free to reach out using social media (LinkedIn or Twitter)

Daniel Higuero, Napptive
Daniel Higuero is CTO at Napptive and his work is focused on facilitating the deployment of complex applications in Kubernetes clusters using OAM. He is a maintainer of Kubevela and OAM specification and participates actively in the community. He has experience leading product architecture in several companies and a background in distributed systems.