Containers
Graceful shutdowns with ECS
February 2023: Parts of this blog are no longer accurate. Following enhancements to the ELB integration for ECS services, tasks running on Fargate Spot will be deregistered from a target group if it receives a spot termination notice before a SIGTERM is issued to the Task.
Introduction
Amazon Elastic Container Service (Amazon ECS) gives customers the flexibility to scale their containerized deployments in a variety of different ways. Tasks can be scaled-out to react to an influx of requests or they can be scaled-in to reduce cost. ECS also supports different deployment options, including rolling deployments, blue/green deployments, and canary-style deployments. Additionally, ECS provides customers with flexible compute options, including on-demand and spot capacity via Amazon EC2 and managed serverless compute via AWS Fargate.
When you take advantage of the dynamic compute options Amazon ECS offers, tasks may experience periodic terminations. For example, deployments result in the termination of a previous version of an application. Scale-in events can result in the termination of one or more task replicas. Instance retirements and replacements—for example, to replace failing hardware or upgrade to a newer version of the operating system—may also result in task termination. Interruptions of Spot instances, an increasingly popular option for AWS customers, similarly result in task termination.
It is important to handle these terminations gracefully, otherwise termination can result in user-facing errors or other problems. For example, a container could exit before a load balancer stops sending it requests, leading to HTTP 5xx errors in response. Similarly, a job processor connected to a work queue could be terminated before it finishes processing a long task, leading to excessive delays in reprocessing. In the worst case, the task might not get retried at all, leading to lost work or a business process failure.
This article provides best practices for handling termination for engineers and service teams who build and operate applications on ECS. We discuss in depth how ECS terminates tasks, and provide information on how to safely shut down applications while minimizing errors.
The container lifecycle
When the ECS agent starts a task, it is responsible for establishing the working environment for all containers in the task. For example, when tasks are configured to use awsvpc networking mode, the agent will provision a pause container and share its network namespace with the other containers in the task. Once finished, the agent calls the container runtime’s APIs to start the containers defined in the ECS task definition.
When a task is stopped, a SIGTERM signal is sent to each container’s entry process, usually PID 1. After a timeout has lapsed, the process will be sent a SIGKILL signal. By default, there is a 30 second delay between the delivery of SIGTERM and SIGKILL signals. This value can be adjusted by updating the ECS task parameter stopTimeout, or with EC2 Container Instances by setting the ECS agent environment variable ECS_CONTAINER_STOP_TIMEOUT. Processes that don’t exit before the timeout expires will be terminated abruptly upon receipt of the SIGKILL signal.
One PID to rule them all
Processes can spawn child processes, and in so doing, become the parent of those children. When a process is stopped by a stop signal like SIGTERM, the parent process is responsible for gracefully shutting down its children and then itself. If the parent is not designed to do that, child processes could be terminated abruptly, causing 5xx or lost work. Within a container, the process that’s specified in the Dockerfile’s ENTRYPOINT and CMD directives, also known as the entry process, will be the parent of all other processes in your container.
Let’s look at an example where the the ENTRYPOINT for the container is set to /bin/sh -c my-app. In this case, my-app will never be gracefully shutdown because:
- As the container’s entry point,
shis run as the entry process and spawnsmy-app, which runs as a child process ofsh shreceives theSIGTERMsignal when the container is stopped but never passes it on tomy-appand is not configured to perform any action on this signal- When the container receives the
SIGKILLsignal,shand all of its child processes are immediately terminated
Shells ignore SIGTERM by default. Therefore, great care must be taken when using shells as entry points for your application. There are two ways you can safely use shells in your entry point: 1) ensure the actual application run via your shell script is prefixed with exec, or 2) use a dedicated process manager such as tini (which ships with the Docker runtime on ECS-optimized instances) or dumb-init.
exec is useful when you want to run a command and no longer need the shell after the command exits. When you exec a command, it replaces the contents of the currently running process (the shell in this case) with a new executable. This is important as it relates to signal handling. For example, if you run exec server <arguments>, the server command now runs as the same PID as the shell ran. Without exec, the server would run as a separate child process and would not automatically receive the SIGTERM signal delivered to the entry process.
You can also incorporate the exec command into a shell script that serves as the entrypoint for your container. For example, including exec "$@" at the end of your script will effectively replace the current running shell with the command that "$@" references. By default, the command’s arguments.
Usage: ./entry.sh /app app arguements
#!/bin/sh
## Redirecting Filehanders
ln -sf /proc/$$/fd/1 /log/stdout.log
ln -sf /proc/$$/fd/2 /log/stderr.log
## Initialization
# TODO: put your init steps here
## Start Process
# exec into process and take over PID
>/log/stdout.log 2>/log/stderr.log exec "$@"Using a process manager such as tini or dumb-init can make termination handling a bit easier. When these programs receive a SIGTERM, they will dispatch SIGTERM to the process group of all of its children, including your application.
Making use of these process managers can be as simple as including their binary in your container image, and prepending the process manager as an argument to your container’s ENTRYPOINT. For example:
ENTRYPOINT ["tini", "--", "/path/to/application"]For your convenience, if you configure your ECS tasks with initProcessEnabled, ECS will automatically run tini as the container’s init process. If you use this feature, you do not need to reconfigure the container’s ENTRYPOINT. More information can be found in the ECS Developer Guide and Docker documentation.
Reacting to SIGTERM
When a task is stopped, ECS sends each container in that task a stop signal. Today, ECS always sends a SIGTERM, but in the future you will be able to override this by adding the STOPSIGNAL directive in your Dockerfile and/or task definition. The stop signal informs your application that it is time to begin shutting down.
Applications that serve requests should be always be shutdown gracefully after receiving of the SIGTERM signal. As part of the shutdown, the application should finish processing all outstanding requests and stop accepting new requests.
If your service is configured to use an AWS Application Load Balancer ECS will automatically deregister your task from the load balancer’s target group before sending it a SIGTERM signal. Deregistering the task ensures that all new requests are are redirected to other tasks in the load balancer’s target group while existing connections to the task are allowed to continue until the DeregistrationDelay expires. A diagram of the workflow appears below:

If your service processes jobs asynchronously, like processing messages in a queue, your container should exit as soon as it finishes processing its existing jobs. If your jobs that take a long time to finish, consider checkpointing the work in-progress and exiting quickly to avoid a potentially costly forced termination. This is especially important for FARGATE_SPOT tasks since it is not possible to configure a stop timeout longer than 120 seconds.
- Note: Tasks run using the Task Scheduler or RunTask are not drained automatically when the EC2 container instance on which they are running is put into a draining state. If you are running tasks with RunTask you may want to create a ASG lifecycle hook and/or a Lambda function triggered by a EventBridge event to enumerate and stop the tasks running on the instance being terminated. Stopping a task like this will cause the containers to receive stop signals before the instance is scaled in or terminated.
Below are examples of termination handlers in several popular programming languages that illustrate how to handle SIGTERM:
Shell handler
Usage: ./entry.sh /app app arguments
#!/bin/sh
## Redirecting Filehanders
ln -sf /proc/$$/fd/1 /log/stdout.log
ln -sf /proc/$$/fd/2 /log/stderr.log
## Pre execution handler
pre_execution_handler() {
## Pre Execution
# TODO: put your pre execution steps here
: # delete this nop
}
## Post execution handler
post_execution_handler() {
## Post Execution
# TODO: put your post execution steps here
: # delete this nop
}
## Sigterm Handler
sigterm_handler() {
if [ $pid -ne 0 ]; then
# the above if statement is important because it ensures
# that the application has already started. without it you
# could attempt cleanup steps if the application failed to
# start, causing errors.
kill -15 "$pid"
wait "$pid"
post_execution_handler
fi
exit 143; # 128 + 15 -- SIGTERM
}
## Setup signal trap
# on callback execute the specified handler
trap 'sigterm_handler' SIGTERM
## Initialization
pre_execution_handler
## Start Process
# run process in background and record PID
>/log/stdout.log 2>/log/stderr.log "$@" &
pid="$!"
# Application can log to stdout/stderr, /log/stdout.log or /log/stderr.log
## Wait forever until app dies
wait "$pid"
return_code="$?"
## Cleanup
post_execution_handler
# echo the return code of the application
exit $return_codeGo handler
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
sigs := make(chan os.Signal, 1)
done := make(chan bool, 1)
//registers the channel
signal.Notify(sigs, syscall.SIGTERM)
go func() {
sig := <-sigs
fmt.Println("Caught SIGTERM, shutting down")
// Finish any outstanding requests, then...
done <- true
}()
fmt.Println("Starting application")
// Main logic goes here
<-done
fmt.Println("exiting")
}Python handler
import signal, time, os
def shutdown(signum, frame):
print('Caught SIGTERM, shutting down')
# Finish any outstanding requests, then...
exit(0)
if __name__ == '__main__':
# Register handler
signal.signal(signal.SIGTERM, shutdown)
# Main logic goes hereNode handler
process.on('SIGTERM', () => {
console.log('The service is about to shut down!');
// Finish any outstanding requests, then...
process.exit(0);
});Java handler
import sun.misc.Signal;
import sun.misc.SignalHandler;
public class ExampleSignalHandler {
public static void main(String... args) throws InterruptedException {
final long start = System.nanoTime();
Signal.handle(new Signal("TERM"), new SignalHandler() {
public void handle(Signal sig) {
System.out.format("\nProgram execution took %f seconds\n", (System.nanoTime() - start) / 1e9f);
System.exit(0);
}
});
int counter = 0;
while(true) {
System.out.println(counter++);
Thread.sleep(500);
}
}
}Handling Spot terminations
In addition to on-demand, ECS gives you the option to run your applications on EC2 Spot instances or as FARGATE_SPOT tasks. If you elect to use EC2 Spot, you should set the ECS Agent’s ECS_ENABLE_SPOT_INSTANCE_DRAINING environment variable to true. This will cause the ECS Agent to put the instance into DRAINING state when it receives the two-minute Spot termination warning.
Marking an instance as DRAINING will cause all tasks from that instance to be migrated to ACTIVE instances in your cluster. The process begins by starting a new task on an ACTIVE instance first and then waiting for it to become healthy. Once the replacement task is healthy, the task on the DRAINING instance will begin to shut down. If that task was registered with a load balancer’s target group, it will be deregistered, giving it the opportunity to finish processing existing requests before it is stopped. This process reduces the likelihood that your applications will experience disruptions during Spot terminations and EC2 shutdowns.
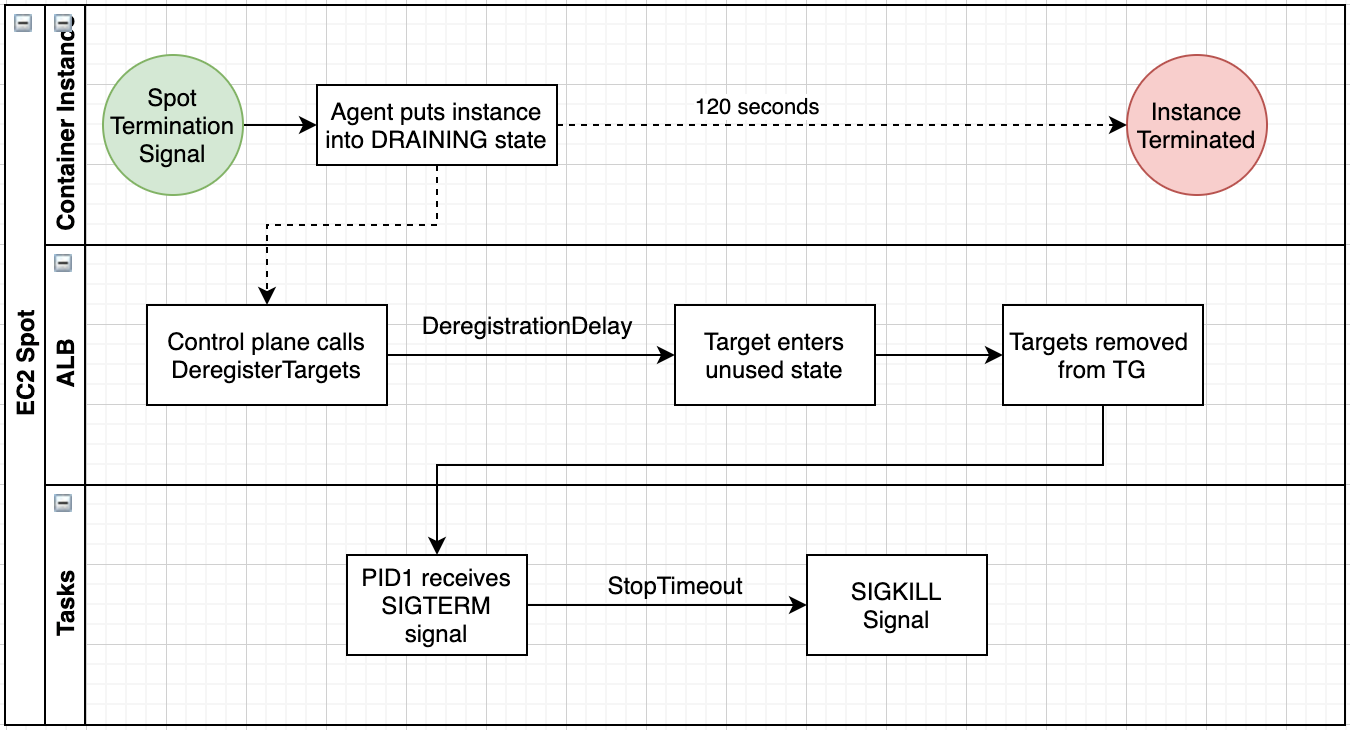
IMPORTANT NOTE: Tasks can only be migrated to other instances when there is spare capacity in your cluster. If you are hosting mission-critical container services on EC2 Spot, consider provisioning additional capacity to accommodate tasks that need to continue running after a Spot instance is terminated.
While Automated Spot Instance Draining works on EC2 Spot Instances, tasks that are run as FARGATE_SPOT are not guaranteed to be deregistered from a load balancer’s target group until the task transitions to a STOPPED state. To avoid unwanted errors, we recommend that you call the requisite APIs to deregister the task from the load balancer’s target group. There are a couple of ways you can handle this:
- As part of your
SIGTERMhandler, deregister the task from the target group by calling DeregisterTargets. This method requires you to embed the AWS SDK in your application. Alternatively, you can run a sidecar container that includes the logic to deregister the task from the load balancer. - Write a Lambda function that fires when a task state change event appears in the event stream. You can find an example on GitHub. When the event’s
StopCodeequalsTerminationNotice, have the function deregister the task from the load balancer.
These methods will also work with tasks that are registered with multiple target groups.
When using Spot, be cognizant of the deregistration delay for any Target Groups associated with your tasks. Spot only gives you two minutes before the task is shutdown, so the deregistration delay for any Target Groups associated with Spot should be set to a value less than two minutes.
If a deregistering target has no in-flight requests and no active connections, Elastic Load Balancing completes the deregistration process immediately. Even though target deregistration is complete, the status of the target will be displayed as draining until the deregistration delay elapses. Additionally, when a FARGATE_SPOT task is marked for termination, all the containers within the task will immediately receive the SIGTERM signal. Upon receiving this signal, you may want your application’s signal handler to sleep for the duration of the deregistration delay before closing connections and terminating all child processes.

Conclusion
Failure to respond to the SIGTERM signal can cause your application to stop abruptly. This can have serious ramifications including 4xx and 5xx errors and possibly forcing you to re-run jobs that were interrupted. When running applications as ECS tasks, you should always include a SIGTERM handler, though if you’re running an application like NGINX, you may need to research how it responds to the container stop signal and/or change the container’s STOPSIGNAL. When your handler runs, it should finish processing in-flight requests and reject all new, incoming requests before the container receives the SIGKILL signal.
Spot presents challenges because you only have two minutes before your task is forcibly terminated. If you’re planning to use ECS FARGATE_SPOT, you should plan to include logic in your handler to deregister the task from the load balancer’s target group or invoke a Lambda function to do it for you. On EC2 Spot, the automated spot instance draining feature will drain targets from the load balancer before sending the containers the SIGTERM signal.
As they say in the scouts, “be prepared.” Be sure that your applications gracefully shutdown upon receipt of the stop signal to avoid problems when deploying new versions or running on Spot.