Containers
Load testing your workload running on Amazon EKS with Locust
Introduction
More and more customers are using the Amazon Elastic Kubernetes Service (Amazon EKS) to run their workloads. This is why it is essential to have a process to test your EKS cluster so that you can identify weaknesses upfront and optimize your cluster before you open it to the public. Load testing focuses on the performance and reliability of a workload by generating artificial loads that mimics real-world traffic. It is especially useful for those that expect high elasticity from EKS. Locust is an open-source load testing tool that comes with a real-time dashboard and programmable test scenarios.
In this post, I walk you through the steps to build two Amazon EKS clusters, one for generating load using Locust and another for running a sample workload. The concepts in this post are applicable to any situation where you want to test the performance and reliability of your Amazon EKS cluster.
You can find all of the code and resources used throughout this post in the associated GitHub repository.
Overview of solution
The following diagram illustrates the architecture we use across this post. Your application is running as a group of pods in an EKS cluster (target cluster) and exposed via a public application load balancer. Locust, in the meantime, is running in a separate EKS cluster (Locust cluster). Cluster Autoscaler and Horizontal Pod Autoscaler will be configured on both clusters to respond to the need for scaling out in terms of the number of nodes and pods respectively.
In addition, AWS Load Balancer Controller will be installed on both clusters to create Application Load Balancers and connect them with your Kubernetes services via Ingress.
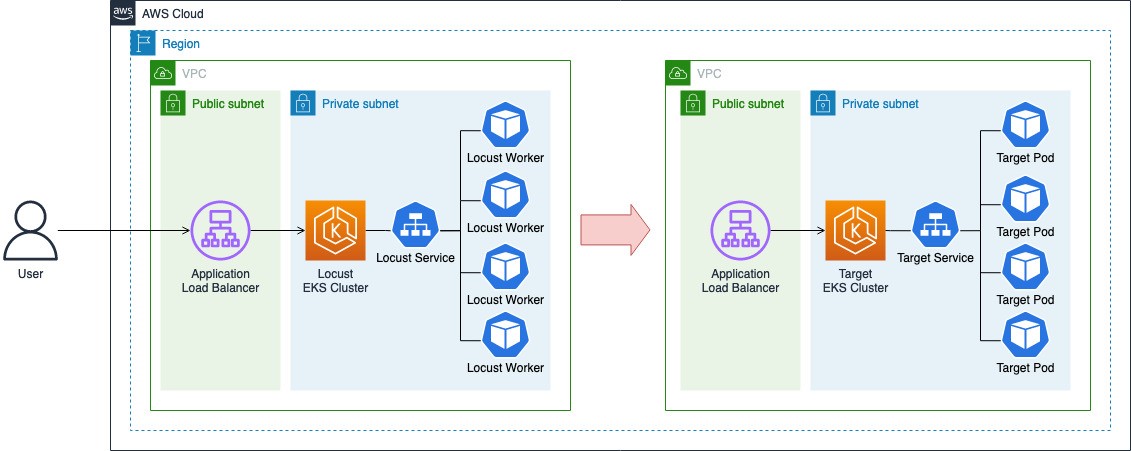
Note: All costs of our journey cannot be covered in the free tier of an AWS account
Groundwork
For our journey, we need two EKS clusters – a Locust cluster for the load generator and another for running a workload to be tested. You can setup the clusters using the following groundwork guide.
Prerequisites
Install CLI tools and settings.
- kubectl (check version release)
- eksctl (check version release)
- helm (check version release)
- jq
- awscli v2
- Setting AWS Profile (with minimum IAM policies)
- Prepare git repository:
If you already have clusters, you can skip these steps.
Please check your AWS account limits to ensure you can provision two VPCs. If you do not have enough resources in your environment, the above cluster creation will fail.
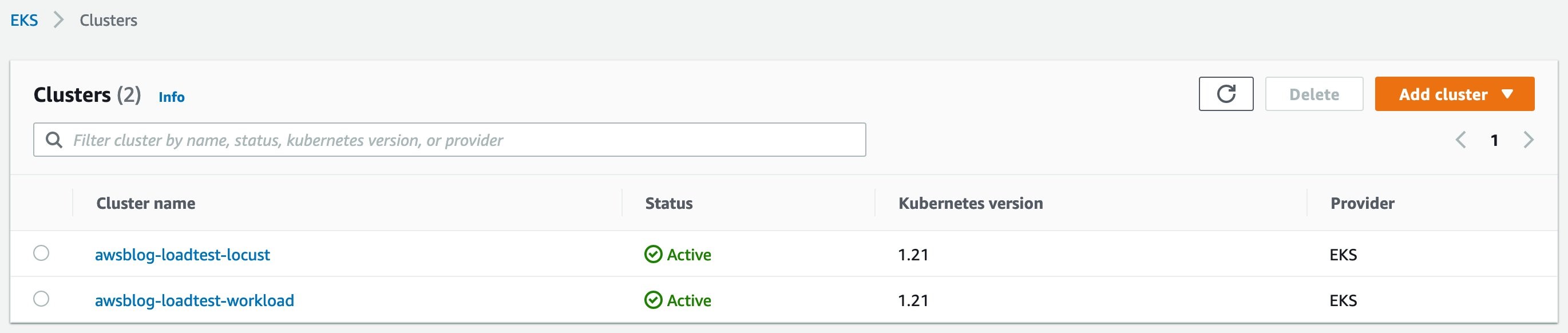
Then you can check the results in AWS consoles.

Installing basic add on charts
For load testing on EKS, we need a few Kubernetes add-ons. These add-ons can be installed either via Kubernetes manifests files in YAML/JSON format or via Helm charts. We are going to use Helm charts as they are commonly used and easy to manage. Given that both clusters awsblog-loadtest-locust and awsblog-loadtest-workload (or your other target cluster) are ready, please refer to the add-on charts installation guide to install the following charts.
- Deploy metrics server (YAML)
- Skip installation step for HPA
- Install Cluster Autoscaler (chart)
- Install AWS Load Balancer Controller (chart)
- Install Container Insights (YAML)
Installing a sample application Helm chart
As a last step of the groundwork, we need to deploy a sample application to be tested. We are going to use Helm for this as well. (If you already have an application you want to test, you can skip this step and use your own application).
Once you have the sample application installed successfully, you will be able to see a welcome message from the sample application by visiting the DNS name of the Application Load Balancer that is associated with the ingress created by the chart.

Walkthrough
You now have the Kubernetes side ready, but there are still a few things left to configure before we start testing your application.
STEP 1. Install Locust
Switch Kubernetes context to run commands on the Locust cluster:
In the previous section, we installed a sample application on the workload cluster. In order to test the application, we need to switch the Kubernetes context from the workload cluster to the Locust cluster.
Add Delivery Hero public chart repo:
Write a locustfile.py
Create a file with the code below and save it as locustfile.py. If you want to test another endpoint, edit this line from “/” to another one (like /load-gen/loop?count=50&range=1000 that we deployed in groundwork). For a more in-depth explanation of how to write locustfile.py, you can refer to the official Locust documentation.
Install and configure Locust with locustfile.py
Executing the following command will install Locust using the locustfile.py created in the previous section. It will also start Locust with five worker pods with HPA enabled. This will provide us with a good starting point for the load test that automatically scales as the size of the load increases.
STEP 2. Expose Locust via ALB
After Locust is successfully installed, create an Ingress to expose Locust dashboard so that you can access it from a browser.
STEP 3. Check out the Locust dashboard
After creating an Ingress in step 2, you will be able to get a URL of an Application Load Balancer by running the following command. Maybe it needs some time (two minutes or more) to get the endpoint of the Application Load Balancer.

You can also find the same info from the AWS console. Navigate to the Load Balancer page in the Amazon EC2 console then select the load balancer. The URL will be available as “DNS name” in the “Description” tab.
Open the URL from a browser:
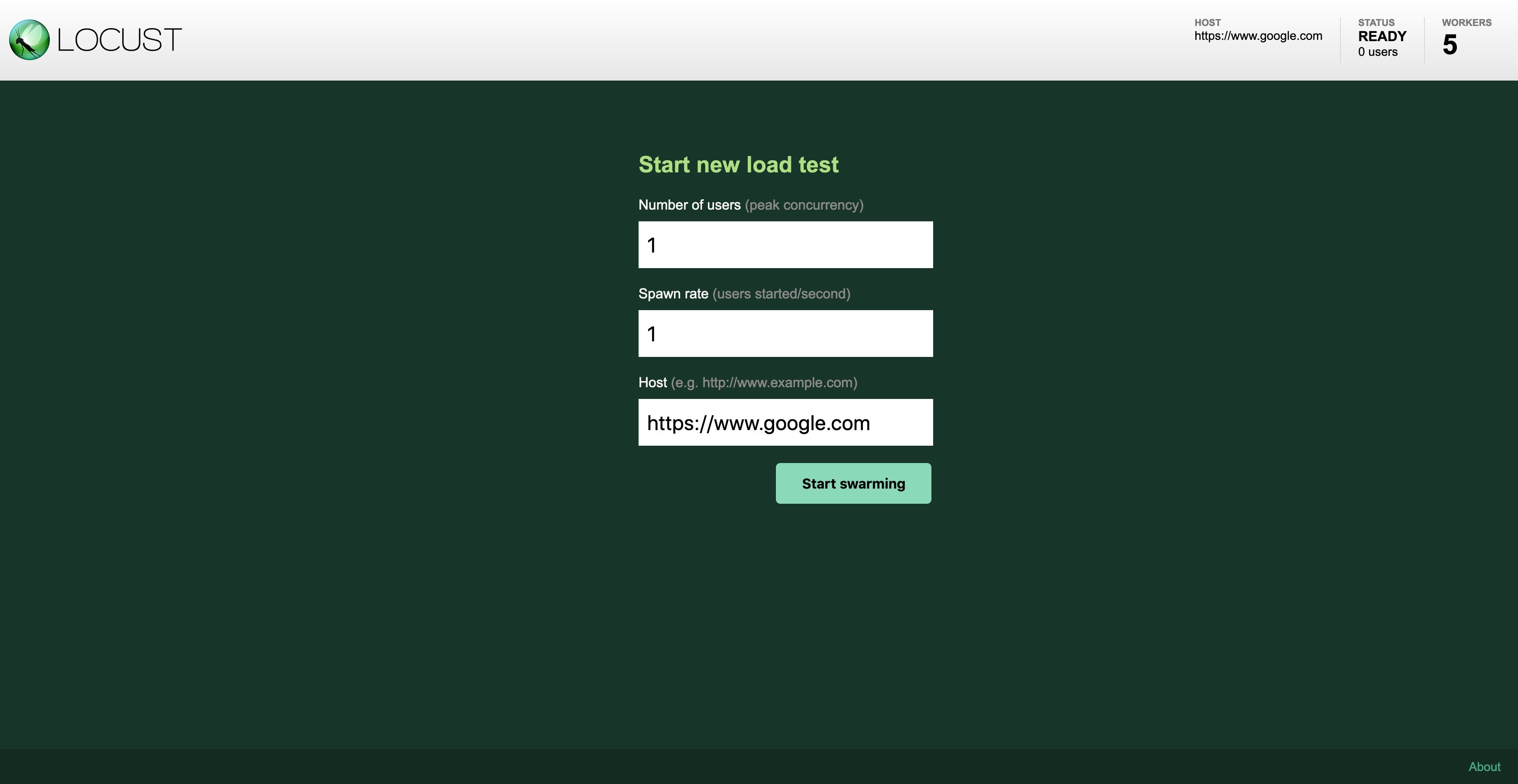
Alternatively, you can port-forward the Locust service to your local port to access the Locust dashboard without creating the Ingress resource.
Open your browser and connect to http://localhost:8089.
STEP 4. Run test
Enter the URL of your application that you deployed earlier. Let’s enter 100 for the number of users and 1 for the spawn rate. Put the endpoint URL of the workload cluster that was created before.
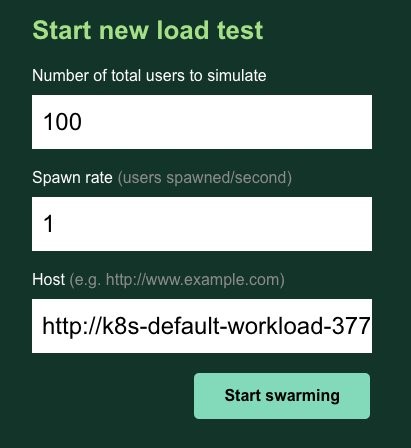
Let it run for a few minutes and, in the meantime, switch between the Statistics tab and the Charts tab to see how the test is unfolding.
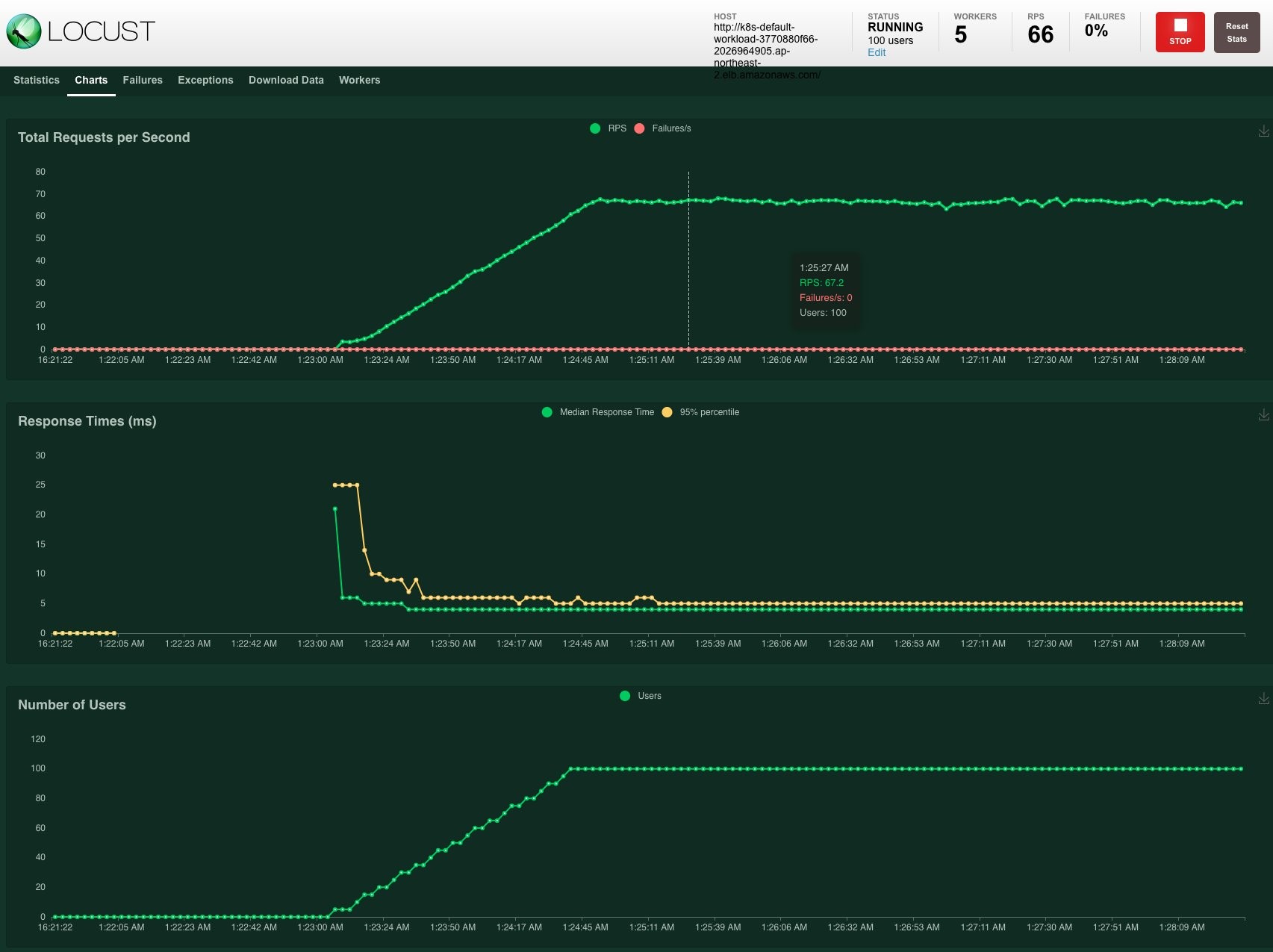
In the statistics tab, Locust briefly summarizes our loads testing result. It is important not to have any noticeable spikes in failure counts, which is depicted as the red line in the top chart.

We can watch the CloudWatch Container Insights dashboard to get a glimpse of the basic metrics of the workload cluster. We can further experiment with the visualization of various metrics, including the EKS control plane, by setting up the Prometheus/Grafana dashboard. For advice on how to monitor the EKS Kubernetes Control Plane performance please refer to the EKS Best Practices Guides.
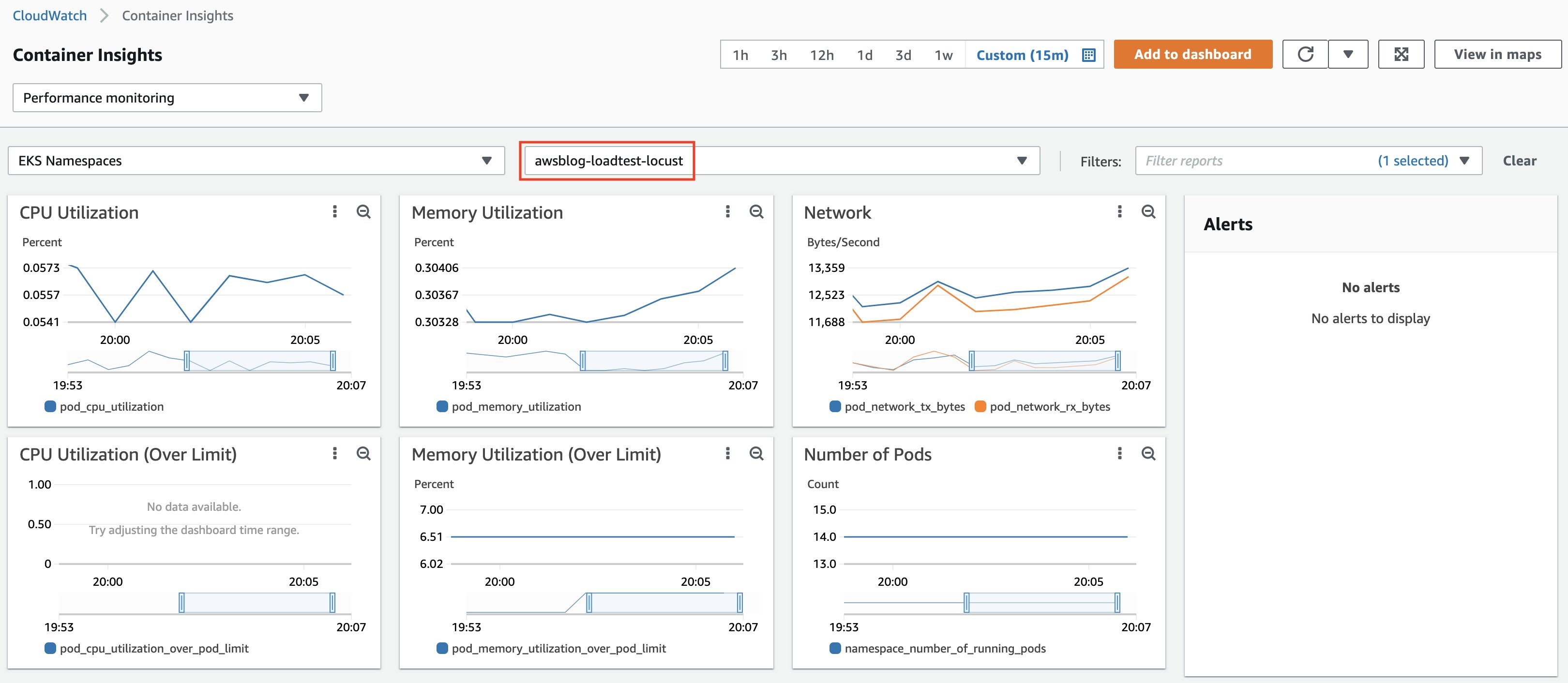
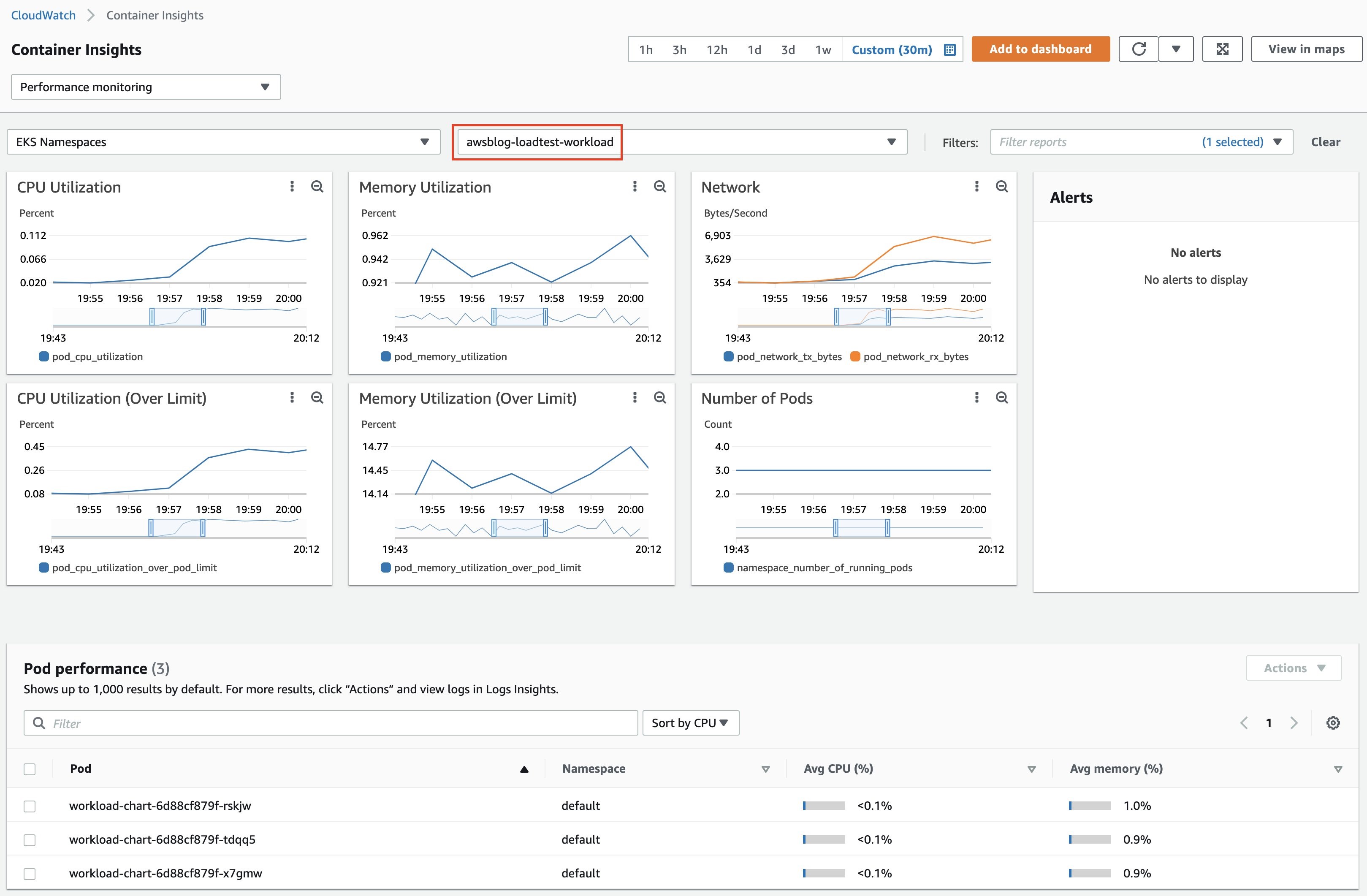
The test shows that the target workload running on EKS can handle requests from 100 users within a reasonable response time. You can take an up-close look at the performance metrics of the cluster from CloudWatch Container Insights.
Now we can give it a little more stress. Stop the test for now and increase the number of users. Let’s put 1,000 users with a spawn rate of 10 and compare it with the previous graph.
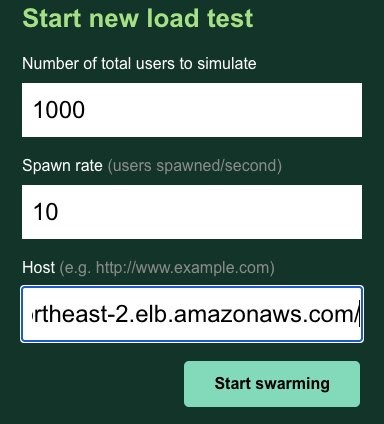
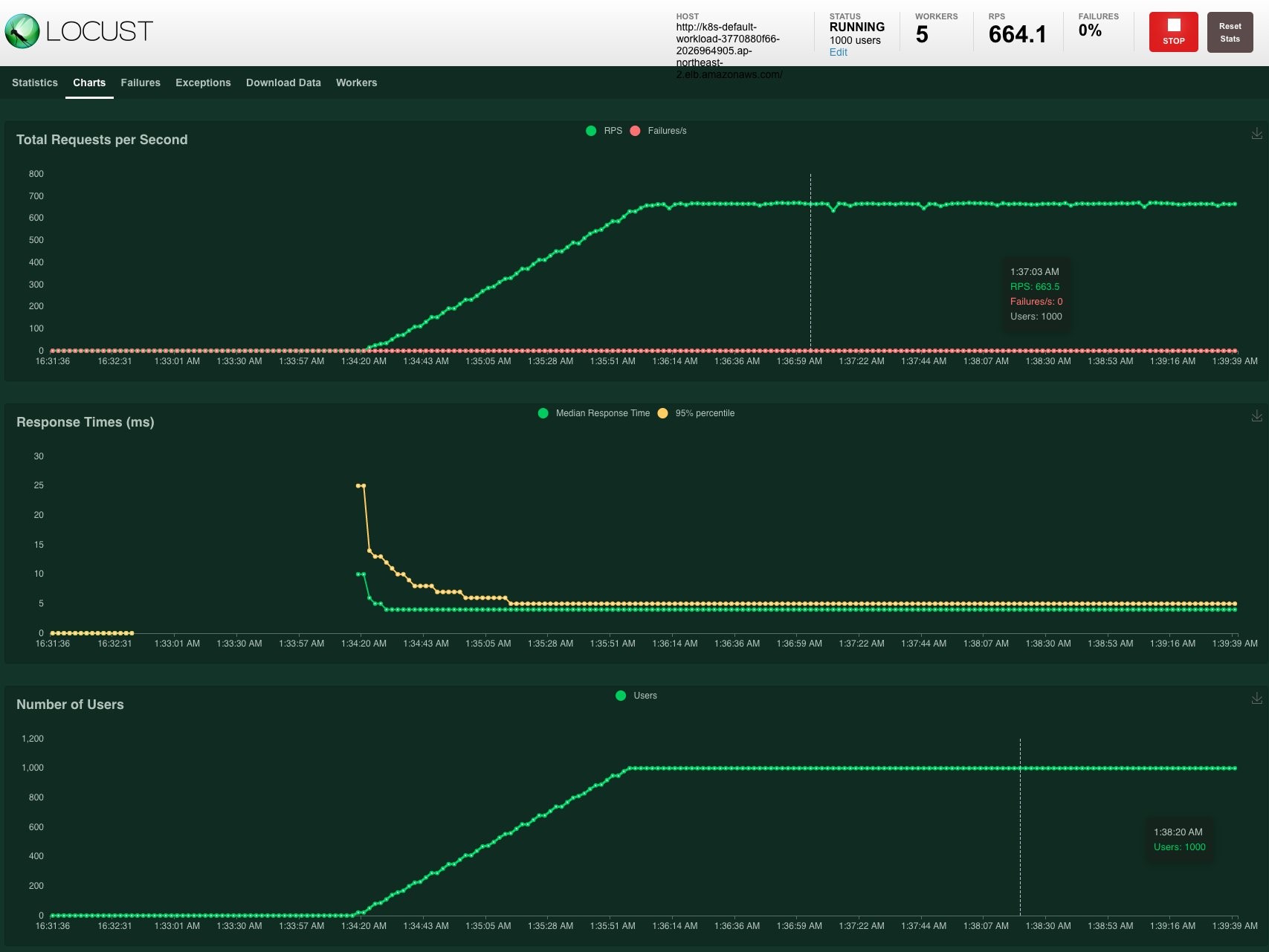

It looks similar to the previous test. It seems that the workload cluster can cover these loads.
STEP 5. Run a second test
Now it’s time for a million users and a prolonged examination time. Let’s put 1,000,000 users with a spawn rate of 100. Both workloads cluster and the Locust cluster itself have enough resources to cover this traffic. It shows a steady upward sloping graph. Suppose we had smaller instances for our clusters, or we gave the load generator more CPU burden, then we will be able to see the Cluster Autoscaler kicking in to add more nodes and the graph would have reflected several sudden bumps.
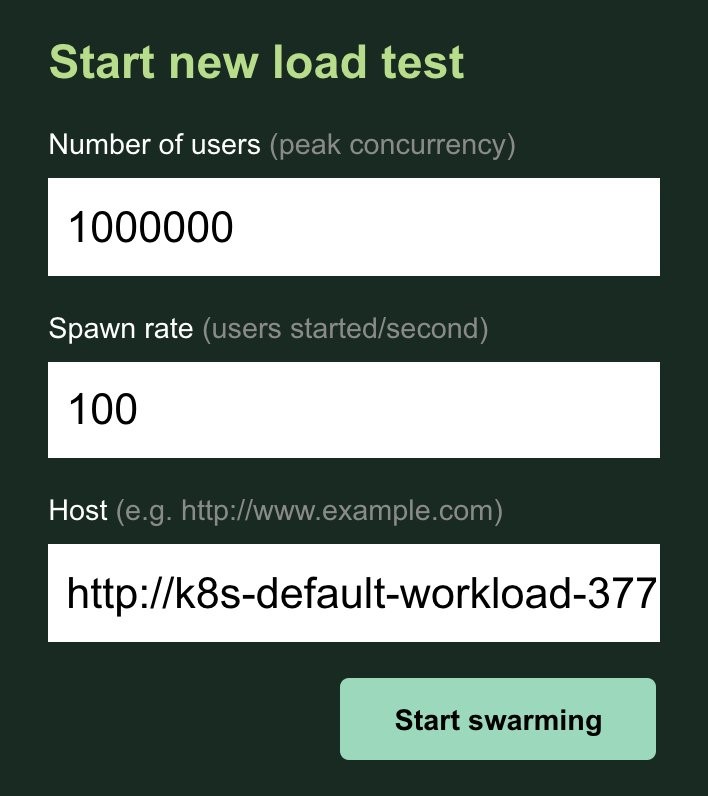
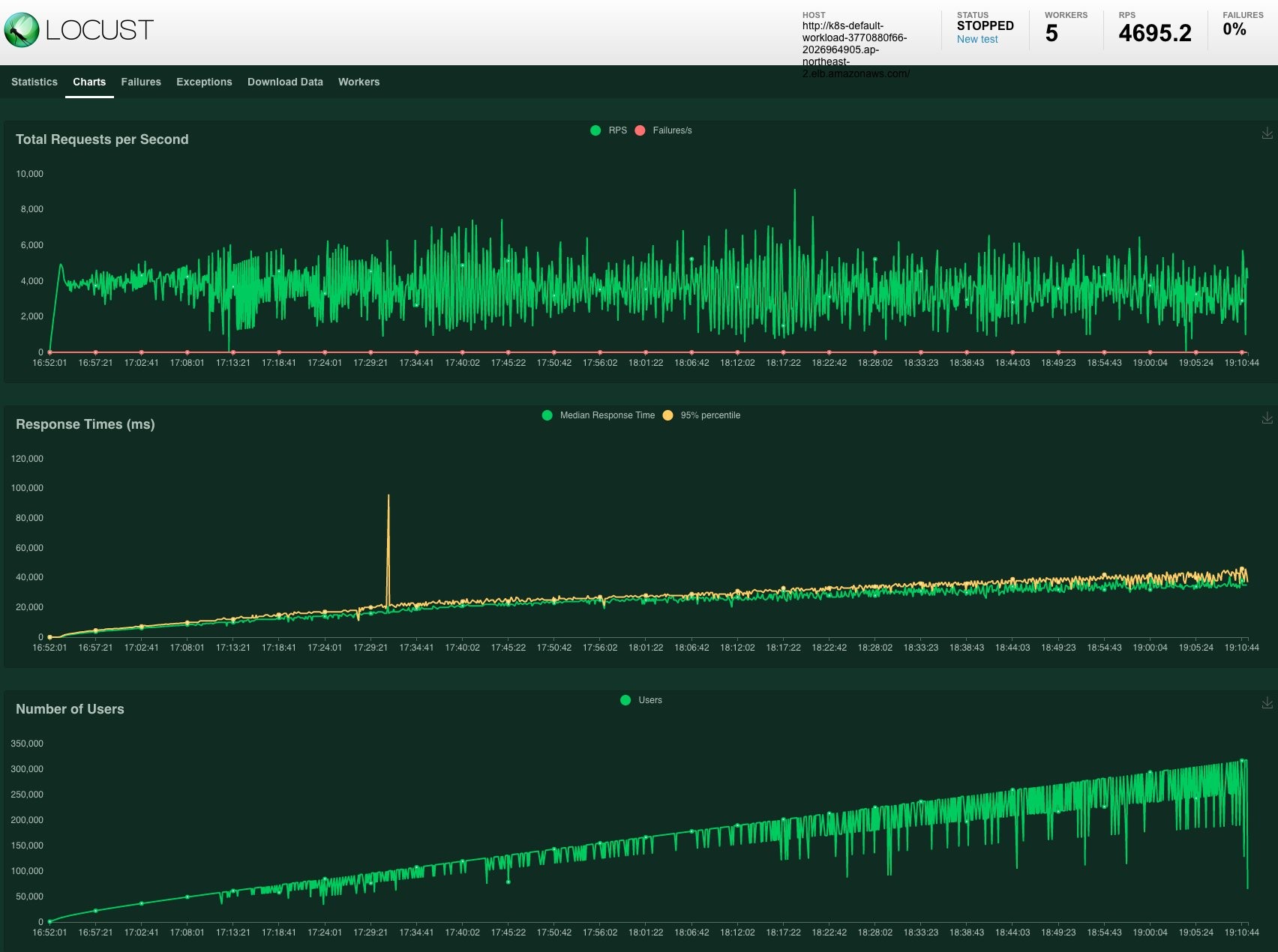

When our cluster needs to scale during the high peak of loads, we may see slower response time and even get 50X HTTP responses. Then we need some techniques for our clusters to be more responsive and fault-tolerant. Here are some tips that might be useful when you load test your own.
- Find the optimal pod’s readiness probes to minimize the time to wait for newly scaled pods.
- Fine-tune the HPA/CA configuration for the specific workloads in order for the Autoscaler to scale out within a tolerable time span.
- HPA reaction time + CA reaction time + node provisioning takes time, and node provisioning usually takes most of that time. Therefore it is useful to have a lighter AMI based on Amazon EKS optimized Amazon Linux AMIs and set resource limits for containers to ensure better bin-packing.
- Check with the scaling pod’s entire lifecycle to see if there is any bottleneck, such as a metric scraping delay, HPA trigger for pods to scale out, container image pulling, application loading time, readiness probe, and so on.
- Overprovisioning employs temporary pods with negative priority and takes ample space in the cluster. In the event of scaling action, it can dramatically reduce the node provisioning time because there already is a node ready to host scaling pods.
- Prevent scale down eviction to the CA if your node scales down during the load testing. For more information about preventing scale down eviction, refer to Cluster-Autoscaler – EKS Best Practices Guides.
- Understand the tradeoff between performance and cost. Run load tests on a regular basis to find and adjust the optimal spec of your cluster in terms of the number and type of nodes, ratio of spot instances, autoscaling threshold and algorithm etc.
- For more information about Autoscaling on EKS, please read the EKS Best Practices Guides.
Cleaning up
When you are done with your tests, clean up all the testing resources.
It’s done. One thing to note, the script above will only take down the awsblog-loadtest-locust cluster. Please make sure that you set TARGET_GROUP_NAME to workload and repeat the process again to take down the awsblog-loadtest-workload cluster as well.
Conclusion
In this blog, we set up two EKS clusters and tools for load testing a workload running on EKS. With the Cluster Autoscaler in action, we could clearly observe that high loads generated by Locust were handled smoothly, as expected. Locust dashboard and CloudWatch Container Insights are useful to identify the maximum loads our cluster can withstand.
We can experiment further by customizing locustfile.py script with various testing scenarios reflecting real-world use cases. In our next blog post, we will introduce various techniques to make our EKS cluster better handle high, spiky loads of traffic during load testing.