Containers
Scaling Amazon EKS and Cassandra Beyond 1,000 Nodes
This post was written in collaboration with Matthew Overstreet from DataStax.
Introduction
With the current widespread adoption of Kubernetes as the target compute platform, many AWS customers and partners consider it the standard for both stateless and stateful workloads. Cloud scale is one of the values that AWS brings to the customers and combining this scale with Amazon EKS may require additional tuning, depending on a given use case (i.e., scaling stateful workloads and running thousands of nodes, pods and services within the same cluster).
Apache Cassandra is a distributed NoSQL database used in many of the biggest “fast data” workloads being operated today. It’s used in architectures that demand low latency access to large sets of data, as well as geo-scaled data. When consumers are distributed all over the world, the data needs to balance proximity, latency, and consistency, which is where Apache Cassandra really shines. In fact, Apple, Netflix, and others use it to manage data for global users.
Apache Cassandra helps solve some very tricky data problems; however it comes with the cost of being notoriously difficult to operate. Not because it’s buggy or unstable, but because running multiple coordinated nodes together in a larger distributed system is fraught with pitfalls. Scaling gets complicated when configurations drift and inconsistent hardware cause issues that are difficult to troubleshoot.
Because of this, DataStax released the open source K8ssandra project. K8ssandra is a Kubernetes operator that helps install, scale, upgrade, and manage Cassandra in an operational environment that isn’t specific to your Cassandra stack. As dealing with distributed applications becomes more common, sharing a common control plane (e.g., Kubernetes) helps teams simplify planning and troubleshooting.
To demonstrate the experience of running a cloud-scale, distributed stateful workload, AWS and DataStax collaborated on scaling up a Cassandra cluster entirely on Amazon EKS and performed a ramp-up performance test. The main objective of the effort was to define performance tuning configurations for large (over 1000 nodes) Amazon EKS clusters running stateful workloads and share the results with the customers. Such collaboration activities are extremely useful to AWS Engineering as well as DataStax and help not only improve the products, but also produce playbooks and guidelines for AWS customers which are approaching the scale described in this post.
AWS allows customers to move large workloads that require thousands of worker nodes and pods to Kubernetes and leverage the operational standardization of Kubernetes and Amazon EKS. No re-architecture, no workload splitting.
In this post, we discuss how to leverage the larger pod and node limits with your Amazon EKS cluster and use an actual example of the K8ssandra performance test to demonstrate it in action.
Prerequisites
- An AWS Identity and Access Management (IAM) role with permissions to create Amazon EKS and Amazon EC2 resources
Solution overview
Preparing EKS for massive scale
Account/Region Level
Besides the limits from Amazon EKS, there are limits in other AWS services, such as Elastic Load Balancing (ELB) and Amazon Virtual Private Cloud (Amazon VPC), that may affect your application performance. Sizing your Amazon VPC to account for the number of pods and nodes you plan to run in your cluster could mean attaching additional CIDRs to the default /16 VPC address space or using IPV6 addresses.
If you are optionally using Amazon EKS-managed node groups, then the default node group limit is 450 nodes (at the time of writing). You can use the AWS Service Quotas console to increase this limit and to request a limit increase for the number of Amazon EC2 instances and Amazon EBS volume resources as needed. For this performance test, the AWS Managed Node Group limit was increased to 1200 nodes.
EKS version
The recommendations in the post assume that your Amazon EKS cluster is on Kubernetes version 1.21 or higher.
Instance types
Use Amazon EC2 instances based on Nitro System for better performance and larger number of IP addresses per instance (requires Amazon VPC-CNI 1.9 or above). Depending on the selected instance type, you can also achieve encryption in transit (intra-node traffic) with no performance penalty.
Operating system
For worker nodes operating system, the recommendation for a large-scale test is Linux Kernel 5.9 or above. That means that either customers can leverage Bottlerocket (5.10) or custom Amazon Linux 2 (Amazon AL2) Amazon Machine Image (AMI) with an upgraded kernel. You can use optimized AL2 AMI as the base for the custom AMI and upgrade the kernel to 5.9+.
IP virtual server and kube-proxy
Configure kube-proxy in IPVS mode (IP Virtual Server) as opposed to the iptables mode when approaching 1,000 services. To enable scalability of services, kube-proxy supports IP virtual server (IPVS) mode for service load balancing on Linux virtual servers. IPVS mode uses efficient data structures (i.e., hash tables) to improve scalability beyond the limits allowed by the iptables.
kube-proxy supports iptables for packet filtering, source network address translation (SNAT), and masquerade by setting up a constant number of iptables rules with ipset-based matches. Iptables and ipset update time in IPVS mode are constant and independent of the number of endpoints or services. The connection setup latency is independent of the configuration.
To configure IPVS mode on Amazon EKS:
- Edit the
kube-proxy-configconfigmap usingkubectl:
- Change the mode value to ipvs (lower case) and save the changes.
- Restart the kube-proxy daemonset to execute the changes on all existing and future nodes immediately. Without a restart, kube-proxy will be set to ipvs on new nodes only.
Container Network Interface (CNI)
If using Amazon VPC for networking, version 1.9 or later contains the VPC IP address prefix assignment feature, which is strongly recommended for large clusters because it mitigates IP exhaustion issue for IPv4. See the documentation for the instructions on how to enable IP address prefix assignment.
Container runtime and AMI configuration
Use containerd runtime for shorter pod-startup latency and overall lower kubelet CPU and memory usage. You can follow these instructions to configure your Amazon EKS optimized AMI to use containerd using the optional flag in the bootstrap script:
When the VPC IP address prefix assignment feature is enabled on VPC CNI, make sure to disable use-max-pods and set the max pods argument explicitly. At the moment, the bootstrap script does not automatically calculate this value when containerd runtime is optionally enabled.
You can follow the instructions here to set up VPC IP address prefix assignment. Step 3 of this procedure describes how to calculate max-pods value.
Here is an example of a bootstrap script:
CoreDNS
You may need to adjust the resource requests for CPU and Memory. The default configuration of CoreDNS has a very useful pod anti-affinity policy that is necessary to avoid getting throttled by the VPC. In large clusters with a lot of DNS traffic, you may have to resort to running NodeLocal DNS. You can also use cluster-proportional-autoscaler with CoreDNS as described here.
Logging and other considerations
For a logging agent, customers can leverage Fluent Bit set up as a DaemonSet for logging. Ensure that the Use_Kubelet value is true, which enables Fluent Bit to gather metadata from the Kubelet instead of the Kubernetes API, which improves performance.
When using the Kubernetes watch interface to detect changes with collections, please apply the recommended best practices for efficient detection of changes.
Control plane
In 2022, AWS implemented a set of improvements in scalability of the Amazon EKS control plane. Consequently, customers can count on fast and automatic scaling of the control plane in response to the increased load.
Customers can also monitor the performance of the Kubernetes control plane, which is recommended for performance troubleshooting as well as spotting issues in third-party software that interacts with the control plane through API server.
Cassandra setup on Amazon EKS
Scenario
For this experiment, we imagined the experience of a development team building a new application. This application is designed to collect sensor data. Initially, the data stored is relatively small, but could grow unexpectedly over the lifetime of the application.
As the number of clients using these services grow, we want to verify that Cassandra running on Amazon EKS scales efficiently to allow for nearly unlimited application growth.
Areas of key concern
We had several goals in the construction of this test. The first goal was to ensure that as we scaled the Cassandra cluster, we continued seeing a near-linear increase in Cassandra cluster capacity. This scaling ability is one of the key features of Cassandra and running K8ssandra on Amazon EKS did not negatively impact that ability.
Additionally, we hoped the test would reveal any hidden operational issues at scale. For this reason, the Cassandra cluster was not originally optimized before the experiment begun. Some of the eventual optimizations found are detailed in this post.
Lastly, the team was interested in the operational agility that might come from the elastic scaling of Amazon EKS and K8ssandra, compared to more traditional Cassandra Deployments. The test was performed by a single engineer, who was responsible for all operations related to the test cluster beyond what is provided by Amazon EKS.
Setup and testing process
Beginning with a 15-node Cassandra cluster (i.e., 1 pod per worker node), the following steps were applied:
- Load the cluster with test data generated by NoSQLBench. This step typically took around 12 hours to ensure at least 200 GB of data was stored on each node regardless of the cluster size.
- Allow the cluster some time to perform compaction.
- Create a separate Amazon EKS Node Group for testing. The size of this group was one quarter of the cluster size, which was sufficient to generate a reasonable load on the cluster when using NoSQLBench.
- Capture two runs of stress test results.
- Truncate data in the cluster and scale to the next test tier.
- Update our Helm
values.yamlandhelm updateto grow the cluster. Then enjoy a coffee while Amazon EKS did all the work.
Tiers used in this test were 15 nodes, 60 nodes, 150 nodes and 1002 nodes. This reflects an almost three orders of magnitude growth in data over the life of our application.
K8ssandra settings
Our K8ssandra installation was deployed using multiple availability zones (AZ) within a single Region. This is a strongly recommended best practice in production Amazon EKS and Cassandra clusters in order to ensure high availability. K8ssandra is aware of the AZs used and ensures that data is replicated across them.
The following is an example of an eksctl configuration used during the creation of our cluster:
A note about IP addresses. Make sure you understand how IP addresses are assigned to nodes within Amazon EKS. Amazon VPC-CNI attempts to reserve a number of IP addresses for your pods based on the number of network interfaces on your instance type. For very large Cassandra clusters this can require a large IP address range.
Follow the instructions on K8ssandra.io (1.2 at the time of writing). Our changes to the default values.yaml were minor. The StorageClass needs to be updated to gp2 and sized appropriately, where 2000 GB is usually the correct choice.
The datacenters key should also be updated to reflect the AZs that your Amazon EKS node group is configured to use.
When running a cluster with more than 60 nodes, reduce the number of metrics collected by the Prometheus deployment within K8ssandra. Additional tuning is required to support metrics for more than 60 nodes. It should be possible to scale the Prometheus instance, or substitute for another option like Victoria Metrics; however, this is beyond the scope of this post.
Finally, adjust the number of Stargate replicas to match your use case. If you are using Stargate and are unsure of the number of replicas, then it’s easy to start with three replicas and scale as required.
With those updates to the default values.yml, follow the instructions on k8ssandra.io to install the Helm chart to your cluster. More detailed information, including an alternative method to setting up with Terraform is available here.
What our testing showed
First, the caveats! This test was performed using a schema with a Replication Factor (RF) of 1. This is not a common configuration for Cassandra, where a RF of 3 is much more common. RF=3 is exceptionally good when you have configured your cluster to run in 3 AZs, and K8ssandra makes sure data is replicated across AZs. RF=1 has a big impact on request throughput, which is important to remember when looking at latency numbers. These RF values are not meant to predict performance, but are an important part in how the numbers scaled with the cluster. Workloads vary, and this workload was very low latency by design.
All nodes were pre-loaded with more that 200 GB of data. During stress test, Cassandra nodes generally operated at 50–60% CPU under load.
| A | B | C | D | |
| 1 | Cassandra Nodes | Stress Nodes | Individual Stress Node ops/second | P50 latency
(NoSqlBench) ns |
| 2 | 15 | 3 | 11412 | 5,300 |
| 3 | 60 | 15 | 11734 | 5,600 |
| 4 | 150 | 38 | 8819 | 6,200 |
| 5 | 1002 | 250 | 8473 | 7,700 |
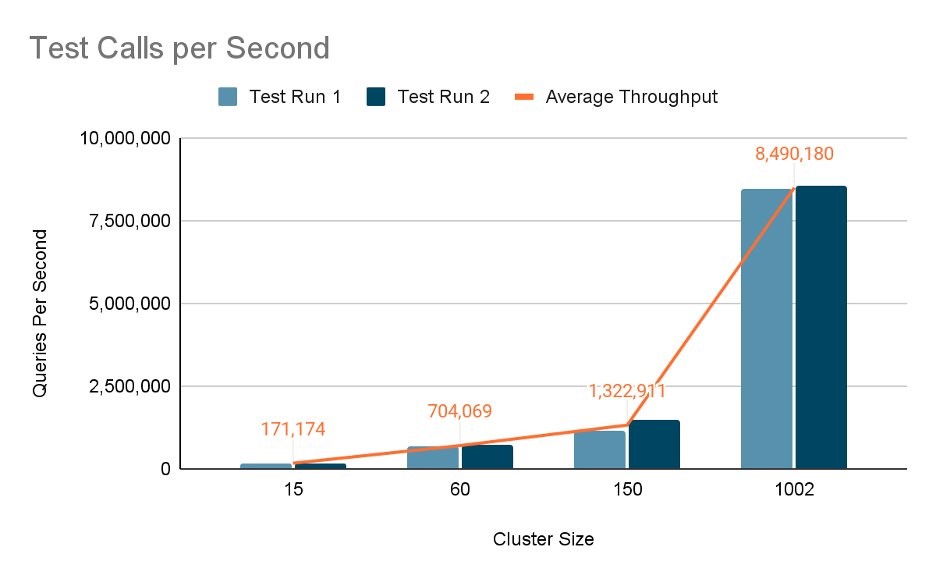
The chart below shows that average throughput reached 8,490,000 test calls per second when running with 1002 nodes:
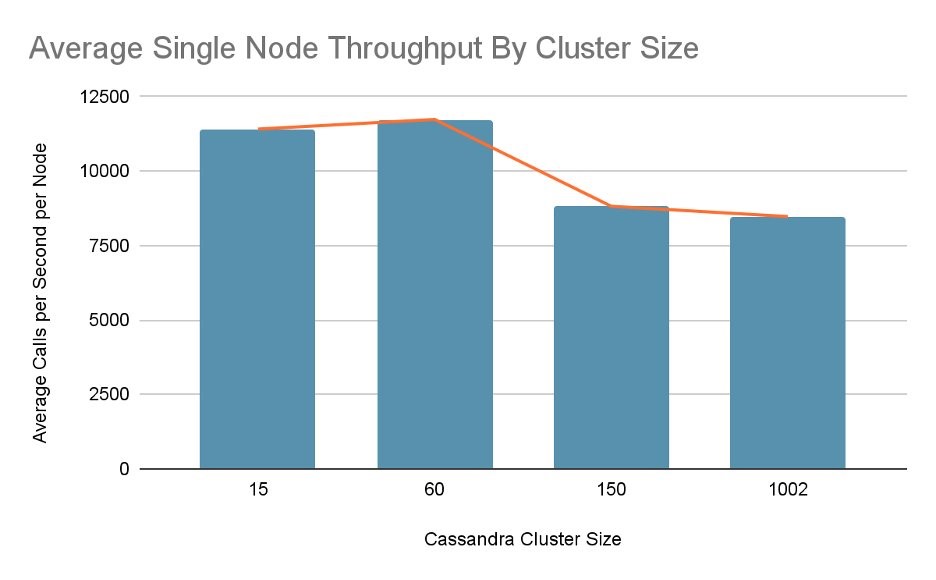
Average single node throughput came to roughly 12,000 calls per node (with 15 nodes) and 8,000 calls per node (with 1002 nodes):
Findings
- The ability to grow a cluster 66-fold from its initial size while maintaining performance is amazing, even more so when it can be done singlehandedly!
- After testing the 1002 node cluster, we continued to push to find the limits of this platform. Without specific configuration and optimization, the Amazon EKS and Cassandra cluster began to fail when scaling at around 1200 nodes. This is likely related to issues with maintaining Gossip information inside Cassandra.
- Cluster creation is awesome on AWS. The cost of testing a 1,000-node cluster is much lower than the cost of scaling a production cluster and finding a limit.
- IP addresses matter, so it’s important to apply proper VPC scaling and VPC-CNI recommendations. Originally, the subnet mask we selected for the test was too narrow to accommodate the full rollout. Adjusting it caused re-provisioning of the cluster and tearing down an 800-node Cassandra cluster. The ability to tear down a massive cluster in under 5 minutes is amazing.
Cleaning up
To avoid incurring any additional costs, make sure you destroy all the infrastructure that you provisioned in relation to the solution described in this post.
Conclusion
In this post, we described a concrete experiment to prove k8ssandra scalability on Amazon EKS. We also extracted general performance and scaling configurations of Amazon EKS that enables customers to scale workloads while maintaining linear performance.
A separate note of appreciation to the AWS Engineering and Product Management for Amazon EKS performance and scalability: great professionalism, agility, and customer obsession.
If you are interested in more information about this effort in a less formal atmosphere, I encourage you to watch the Containers from the Couch video that we recorded with DataStax: Cassandra on 1200 EKS Nodes with DataStax.
If you are an AWS partner and would like to participate in a similar experiment with a goal to apply the findings in production and/or share with a broader community, then please reach out to your Partner Development Manager or AWS Partner Specialist.

Matt Overstreet, Principal Architect, DataStax
Matt Overstreet is a Principal Architect at DataStax focused on the cloud and cloud providers. He has worked with Federal, Fortune 100, and small businesses to help collect, mine and interact with data. He shares DataStax’s mission of connecting every developer in the world to the power of Apache Cassandra.