Containers
Tradeshift’s migration to Amazon EKS without downtime using Linkerd
This post was co-written by Ricardo Amato, Staff DevOps Engineer at Tradeshift, and Andreas Lindh, Specialist Solutions Architect, Containers at AWS.
Introduction
Tradeshift is a cloud-based business network and platform, which has run our applications in AWS using self-hosted Kubernetes for a number of years. In 2022, a decision was made to migrate from the self-hosted setup to Amazon Elastic Kubernetes Service (Amazon EKS) to reduce operational overhead of managing Kubernetes itself and allow focusing efforts on building a better platform for developers consuming the platform.
Migrating to Amazon EKS from a self-hosted Kubernetes cluster can be challenging, depending on the strategy used. Traditionally, teams need to create a new cluster using Amazon EKS, deploy all of their services and related Kubernetes objects such as Secrets, ConfigMaps, and Ingresses to this new cluster, so that services with dependencies on each other can successfully communicate with each other. Then, once successfully tested, they switch the traffic to the new cluster. This approach may require downtime for reasons such as Domain Name System (DNS) Time-to-Live (TTL) configuration, and doesn’t easily facilitate a rollback in the event of an issue. Fortunately, this doesn’t have to be the case.
In this post, we’ll describe how Tradeshift was able to gradually migrate services from a self-hosted cluster to Amazon EKS without downtime using the Linkerd service-mesh and its multi-cluster capabilities.
The problem
The biggest problem faced in our migration from a self-hosted Kubernetes cluster to Amazon EKS was that traditional methods of migration, using third-party solutions like Velero and Druva that can back up the state of a cluster and then restore that state onto another cluster. This approach not only requires downtime, but also makes it difficult to test if the backed up resources works properly on the new cluster. Another issue is that rolling back a service in the event of an issue is usually not straightforward, and could potentially lead to unexpected downtime and more issues down the line.
Before starting the migration, we identified our key business requirements for the migration to be successful:
- Requires no migration downtime
- A transition that is transparent to services
- A migration that can be done gradually
- Easily revert migrated services in case of any issues
Based on these requirements, an optimal solution for Tradeshift would be enabling the self-hosted cluster and the new Amazon EKS cluster to be connected and treated as a single entity. Our production environment then becomes a combination of the self-hosted cluster and the Amazon EKS cluster and services transparently communicates among them without the need for changes. This empowers teams to migrate their services gradually to the new Amazon EKS cluster. Furthermore, by having such a solution, reverting is not only feasible but easily accomplished.
Solution overview
After our initial research, we identified that we needed a component that could help us facilitate service to service communication across Kubernetes clusters, features provided by service meshes such as Linkerd and Istio. Tradeshift decided to use Linkerd due to its lightweight nature and efficient resource usage, compared to Istio’s more complex architecture. With Linkerd, we could better understand the performance of our services, and also gain insights into our services during migration to ease identification of any issues.
Using Linkerd and its multi-cluster capabilities, we were able to connect the self-hosted Kubernetes cluster to the new Amazon EKS cluster, ensuring a seamless migration and meeting our key business requirements. This ensured a safe migration to the new cluster, and that in the event of any issues, we were able to safely revert to the previous solution without downtime. Importantly, our solution didn’t require changes to be made to the services themselves during the migration process, further minimizing risk and impact for teams.
Technical details
Now that we have laid out the requirements for our migration to Amazon EKS, we need to do the following to achieve what we are setting out to do. First, we need to connect the clusters, export the services, and use a traffic splitting resource to route traffic between the clusters.
In order to achieve this, Linkerd need to be installed (docs) on both clusters with the Multicluster and Service Mesh Interface (SMI) extensions.
Connecting the clusters
By installing the linkerd-multicluster extension, the following components are created in both clusters:
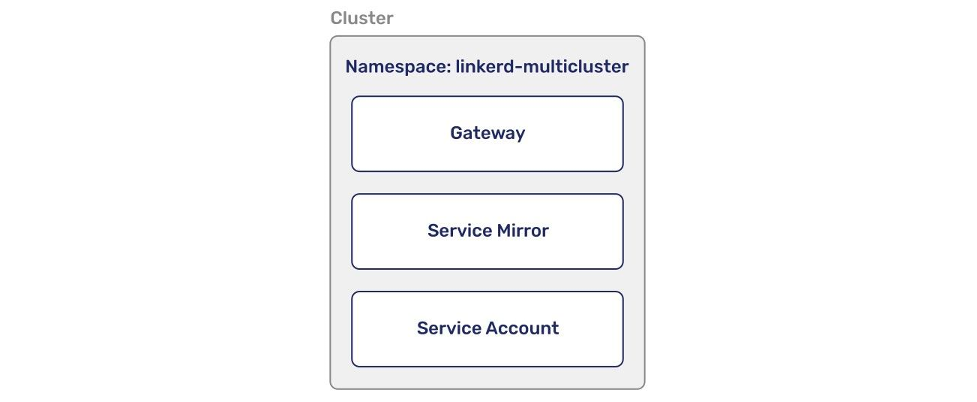
- Gateway: This is the entry point to the cluster from the outside. This is what other Linkerd clusters communicate with after a link is established.
- Service Mirror: This component connects to the remote clusters once a Link is established and communicates with its Kubernetes Application Programming Interface (API) to watch the services that are to be exported.
- Service Account: Needed to be able to create the resources needed like Kubernetes Services when two clusters are linked.
The Gateway is installed by default if you follow the official documentation, using the Linkerd Command Line Interface (CLI) or Helm. This component is exposed with a Service type LoadBalancer, which allows inbound traffic from anywhere (0.0.0.0/0) with mTLS enabled using the Linkerd trust anchor to validate the request.
To connect our two clusters together, we need to create links between them. Links in Linkerd multi-cluster are unidirectional, so we need to create a link in each direction between the two clusters. We achieve this by using the Linkerd CLI tool to generate the correct Kubernetes manifests for each cluster, and then apply it to the target cluster. Note how we use eks and legacy in the commands below to reference which cluster to work on.
We want to connect our legacy (self-hosted) cluster to our new Amazon EKS cluster, so we would run:
The reverse also needs to be created since Links are unidirectional:
Once this is done, the Service Mirror and Service Account are created and the clusters are ready to be used together.
Validating connectivity
The first thing we need to do is check if the multi-cluster gateways can be found on both clusters and that the services have been exposed. We confirm on the Amazon EKS cluster:
As we can see the multi-cluster gateway legacy is properly configured and the 409 Services on it are now discoverable and accessible from the Amazon EKS Cluster. We now do the same but from the legacy cluster to confirm Amazon EKS is also sharing its services with the legacy cluster:
This shows how the Amazon EKS cluster is properly set up on the legacy cluster, and that 51 services have been exposed with the legacy cluster. With this information we know that both clusters are connected properly.
Our exported services keep the original name and automatically have the name of their respective cluster added as a suffix, in the format <service>-<cluster>. This is how our services appear in Amazon EKS:
If Service A normally communicates with Service B, and Service B communicates with Service C, which is migrated to the new Amazon EKS cluster, and is shown in the following diagram:

As we can see, all services are meshed and communicated using the linkerd-proxy, which is running as a sidecar. When Service B sends a request to Service C, which is running on the Amazon EKS cluster, it’s routed automatically to the Multi-Cluster Gateway running on the Amazon EKS cluster. This is then automatically routed the traffic to Service C. The Gateway is the only entry point into the cluster and needs to be scaled depending on the amount of traffic you have. A Horizontal Pod Autoscaler can potentially be used for this component.
Exporting services
Now that the clusters have been linked in both directions, we can start exporting services between them. Exporting services is a term used specifically for linkerd-multicluster and refers to sharing services from one cluster with another cluster. For more information, please refer to the official documentation. For this migration, we assume all services need to be migrated over, so we’ll expose all the legacy services on the Amazon EKS cluster and vice versa. To do this, we modify the Link resource. We can list all links using the following command:
This command lists the links created when the clusters were connected. Once the Link has been located, you can modify it so that all services are exported as follows:
This ensures all services that aren’t mirrored are exported since we want to avoid an infinite loop.
Using TrafficSplit resources to make the migration transparent
Our clusters are now interconnected, which allows the services of each to be remotely accessed from the other. In order to seamlessly migrate our services, we must ensure that the services on the legacy cluster can still connect to those on Amazon EKS, and vice versa, and that we can switch per service traffic between clusters with minimal configuration changes.
We utilize the Service Mesh Interface (SMI) TrafficSplit Resource to achieve our goal, and is demonstrated in the following code:
If we deploy the above to the legacy cluster, then this configuration is applied to all linkerd-sidecar containers which results in traffic being sent to serviceA 100% of the time. Once serviceA has been deployed to Amazon EKS, and the service has been mirrored, serviceA-eks becomes available, as depicted below.
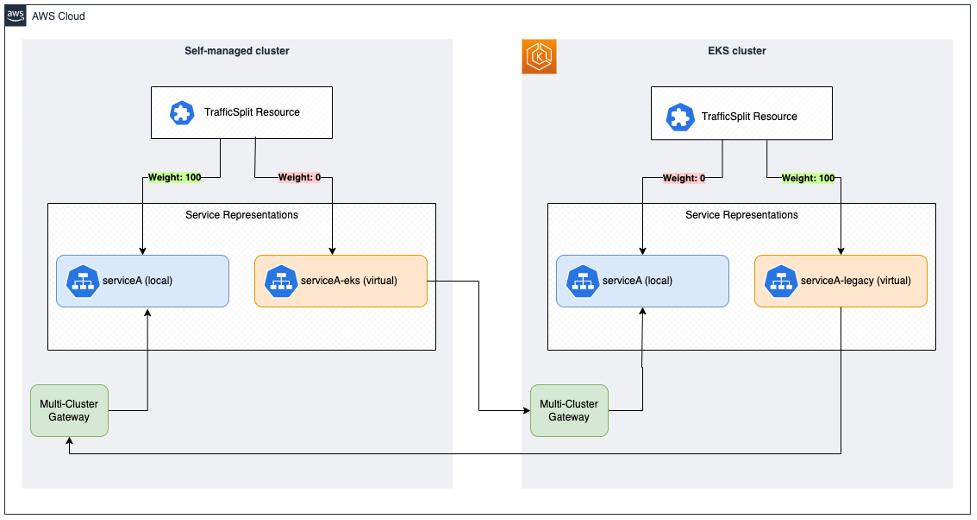
Now, we can simply change the weights so that all traffic is now sent to the service running on Amazon EKS by changing the following:
This ensures the legacy services calling serviceA send the traffic to serviceA-eks in a transparent manner. No further changes are required on the legacy cluster. On the Amazon EKS cluster, we need to ensure that the TrafficSplit is routing all the traffic to the local serviceA instead as the following configuration shows:
The following diagram illustrates this solution:
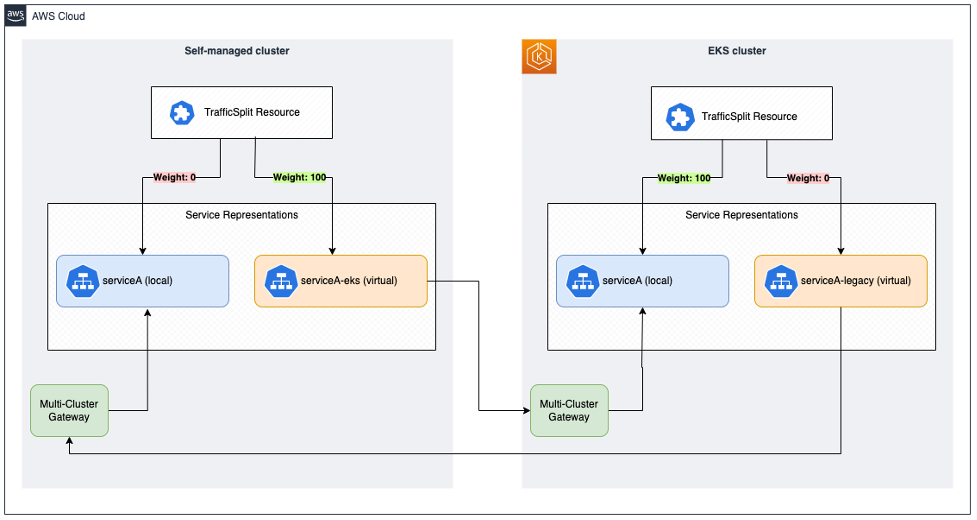
With this the service migrated to Amazon EKS, other services that depend on serviceA simply access the service on the Amazon EKS cluster. In case of an error or if the legacy service needs to be used again, we just change the values so that the legacy cluster uses serviceA and the Amazon EKS cluster uses serviceA-legacy for 100% of the traffic. To accomplish this, just reverse the steps followed above and apply the resources using kubectl to both clusters.
This migration of a single service to the Amazon EKS cluster is now complete! To complete the migration to Amazon EKS, we repeated the same process for every single service until all of them were running on Amazon EKS. Once that is the case, the self-hosted (i.e., legacy) cluster can be safely shut down and removed.
Conclusion
In this post, we have discussed how using the multi-cluster capabilities of Linkerd, Tradeshift was able to migrate its services from a self-hosted cluster to Amazon EKS seamlessly. Connecting two Kubernetes clusters (self-hosted and Amazon EKS) together, to migrate services from one cluster to another with no downtime, while giving us the peace of mind knowing that reverting in case of any issues was simple and straightforward.
Migrating from a self-hosted cluster to Amazon EKS can seem like a daunting task – and it can be if you’re not prepared. You can mitigate any issues by following with the details shown in this post to ensure the migration is approached in a manageable, efficient, and safe manner.
To learn more about Amazon EKS, have a look at the documentation, or explore EKS Workshop, and to learn more about Linkerd, you can find the documentation here.

Ricardo Amato, Tradeshift
Ricardo is currently working as a Staff DevOps Engineer at Tradeshift, specializing in designing and implementing cloud solutions. He is passionate about DevOps and has built his career on implementing state-of-the-art solutions. He is constantly motivated to push the boundaries of what’s possible in the field.