AWS Database Blog

Use Key Management Service (AWS KMS) to securely manage Ethereum accounts: Part 1
Ethereum is a popular public blockchain that makes it possible to create unstoppable applications in a permissionless fashion. It’s available to every user that has an Ethereum account. These Ethereum accounts consist of a private and an associated public key. The main challenge as a user participating in a public blockchain such as Ethereum is […]
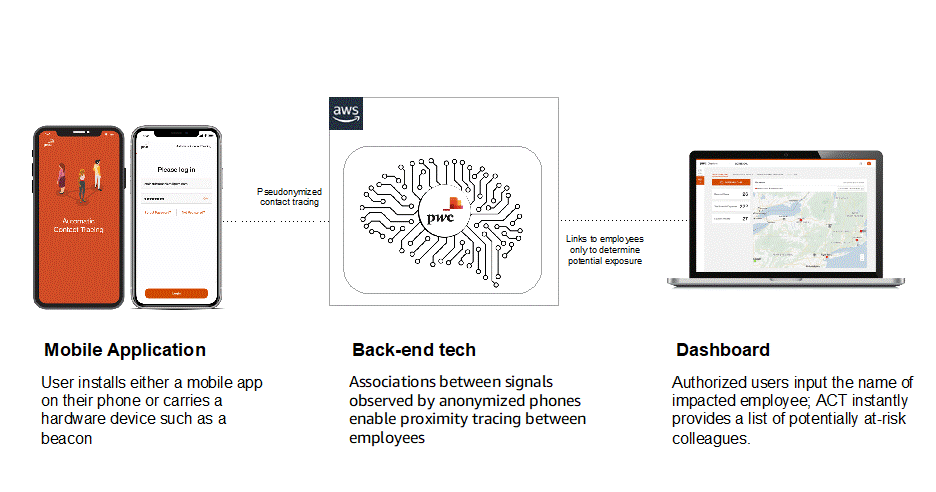
Idea to product: PricewaterhouseCoopers launches Check-In within three months on Amazon Keyspaces
The COVID-19 pandemic presented enterprises with various challenges. Enterprises notably need to safeguard employees, partners, and customers when they return to the office. Holistic workforce strategies require a combination of preventative screening tools and detailed contact tracing solutions. PricewaterhouseCoopers LLP (PwC) quickly responded and adapted to develop Check-In, powered by AWS. Check-In provides companies with […]

Access Amazon Location Service from Amazon Aurora
Organizations typically store business and customer data in databases like Amazon Relational Database Service (Amazon RDS) and Amazon Redshift, and often want to enrich this data by integrating with external services. One such enrichment is to add spatial attributes such as location coordinates for an address. With the introduction of Amazon Location Service, you now […]

Implement Oracle Database Resident Connection Pool with Amazon RDS for Oracle
This post describes how to configure Oracle Database Resident Connection Pool (DRCP) in an Amazon Relational Database Service (Amazon RDS) for Oracle environment. You can use DRCP with application servers that can’t do middle-tier connection pooling. You can also use DRCP to manage hundreds or thousands of database connections from clients spread across multiple application […]
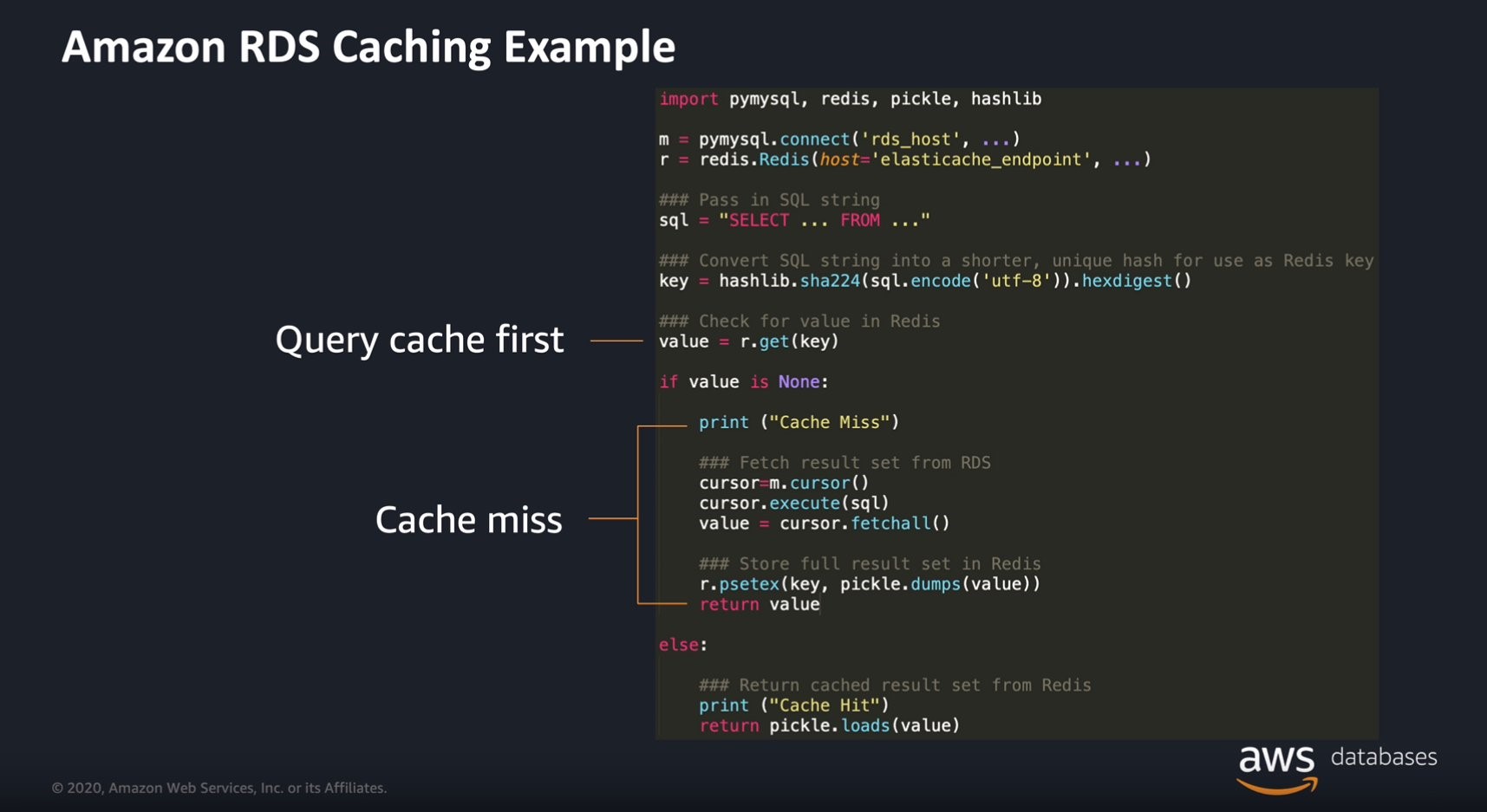
Get started with Amazon ElastiCache for Redis and Memcached: Introducing the ElastiCache learning path
Ready to get started with Amazon ElastiCache? Introducing the new learning path Amazon ElastiCache: In-memory data store fundamentals, use cases, and examples. ElastiCache is a managed in-memory caching service compatible with Redis and Memcached, enabling you to seamlessly set up, run, and scale in-memory data stores in the cloud. In this new learning path, follow […]

Monitor errors in Amazon Aurora MySQL and Amazon RDS for MySQL using Amazon CloudWatch and send notifications using Amazon SNS
May 2023: This post was reviewed and updated for accuracy. Monitoring databases is essential for any DBA, from dev-test databases to mission-critical databases. You want to capture system and user-defined events for monitoring and troubleshooting problems related to your database instance. MySQL records these events in error logs. In this post, we show you how […]

Schedule jobs with pg_cron on your Amazon RDS for PostgreSQL or Amazon Aurora for PostgreSQL databases
Scheduling jobs is an important part of every database environment. On a traditional on-premises database, you can schedule database maintenance jobs on the operating system where the database runs. When you migrate your databases to Amazon Relational Database Service (Amazon RDS) or Amazon Aurora, you lose the ability to log in to the host and […]

Managed disaster recovery with Amazon RDS for SQL Server using cross-Region automated backups
Amazon Relational Database Service (Amazon RDS) for SQL Server now supports managed disaster recovery (DR) using Amazon RDS cross-Region automated backups. This feature extends the existing Amazon RDS backup functionality, giving you the ability to set up automatic replication of system snapshots and transaction logs from a primary AWS Region to a secondary Region. The […]
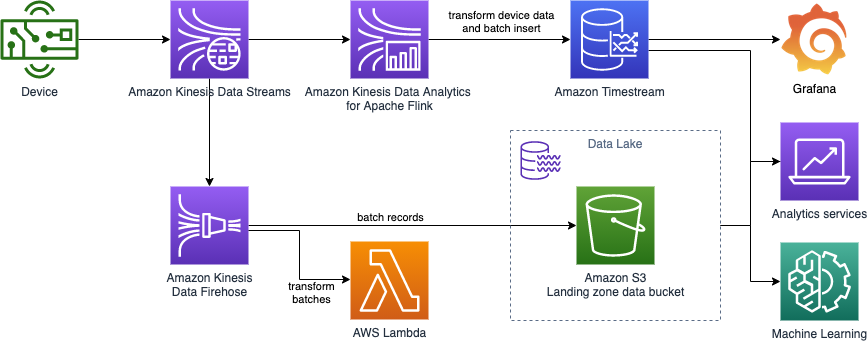
Near real-time processing with Amazon Kinesis, Amazon Timestream, and Grafana
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. As organizations adopt and deploy home-connected smart devices, they face challenges utilizing device telemetry data in narrow and broad contexts. Examples of such home-connected devices are smart […]

Automate post-database creation scripts or steps in an Amazon RDS for Oracle database
In some cases, Database Administrators (DBAs) need to run post-database creation steps such as running SQL statements for creating users and database objects, resetting passwords, or standardizing Oracle database builds. This is mainly done during the database creation phase of new application deployment or during database refreshes that occur in non-production environments. AWS CloudFormation gives […]