AWS Developer Tools Blog
Introducing Retry Throttling
Client side retries are used to avoid surfacing unnecessary exceptions back to the caller in the case of transient network or service issues. In these situations a subsequent retry will likely succeed. Although this process incurs a time penalty, it is often better than the noise from oversensitive client side exceptions. Retries are less useful in cases of longer running issues where subsequent retries will almost always fail. An extended retry loop for each request ties up a client application thread, that could otherwise be moving on to another task, only to return an exception. In cases of service degradation, the explosion of retried requests from clients can often exacerbate problems for the service, which hurts recovery times, prolonging the client side impact. To address this issue we are pleased to announce the introduction of a client retry throttling feature.
Retry throttling is designed to throttle back retry attempts when a large percentage of requests are failing and retries are unsuccessful. With retry throttling enabled, the client will drain an internal retry capacity pool and slowly roll off from retry attempts until there is no remaining capacity. At this point subsequent retries will not be attempted until the client gets successful responses, at which time the retry capacity pool will slowly begin to refill and retries will once again be permitted. Because retry throttling only kicks in when a large number of requests fail and retries are not successful, transient retries are still permitted and unaffected by this feature. Retries resulting from provisioned capacity exceptions are not throttled.
Behavior compared
To test the effectiveness of this new feature we set up a controlled environment in which we could subject the AWS SDK for Java to various failure scenarios. For this test, we drove a consistent request load through the client and placed a fault injection proxy between the client and service. The fault proxy was set up to return 5xx responses for a certain percentage of requests. Each test run lasted 30 minutes. The test, which initially began with no errors, slowly ramped up to a 100% error rate, and then back down to 0% by the end of the run.
No throttling
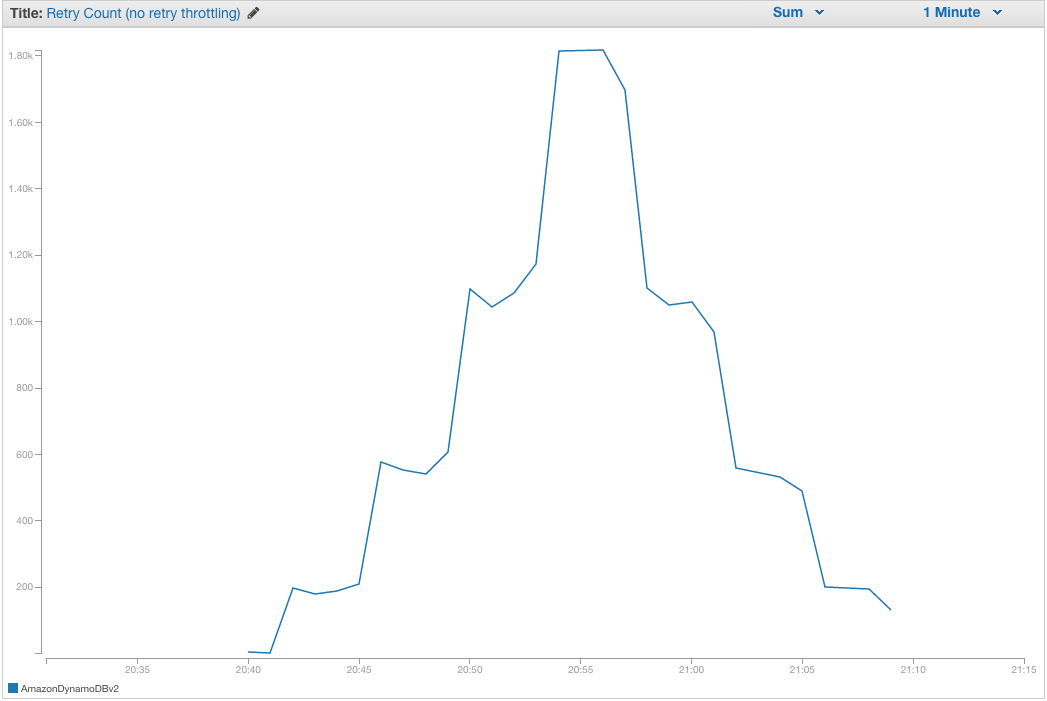
With the default retry behavior and no throttling you can clearly see the client ramping up retries proportional to the number of 5xx responses it sees. At the middle of the test run we hit the 100% error rate and retries are pegged at their maximum level. Even though none of these retries result in successful responses the client continues retrying at the same pace, tying up application threads and client connections and hammering the service with wasteful requests.
Throttling enabled
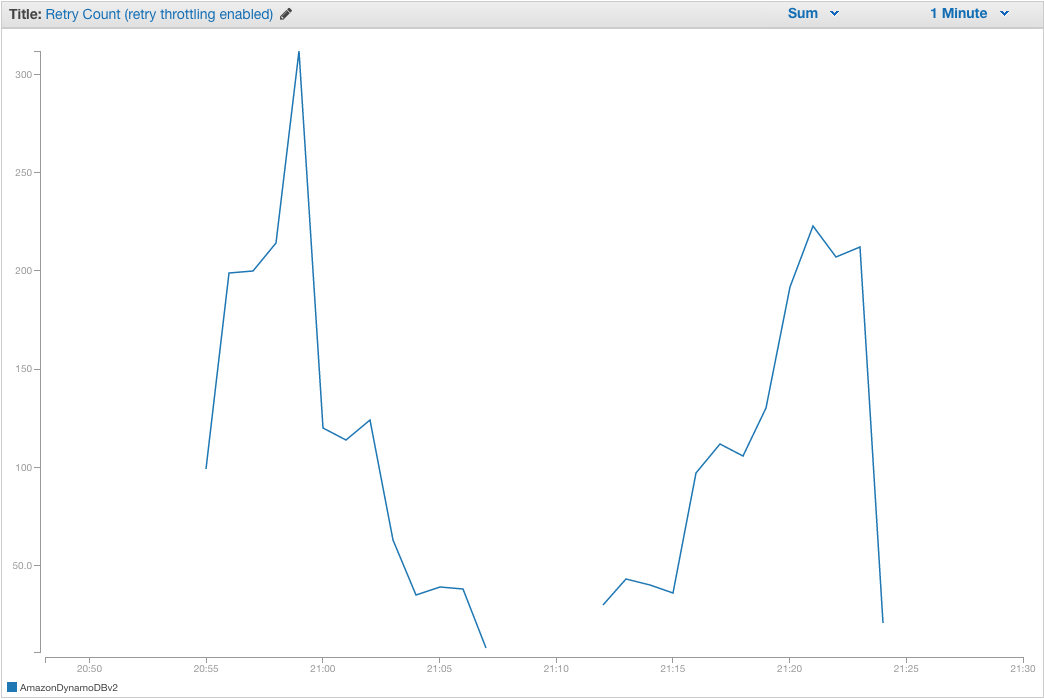
With retry throttling enabled you can see the client initially ramp up its retry attempts as 5xx errors are introduced but begin to tail off as errors increase. After the 100% error rate is reached the client abandons retry attempts because there are no successful responses. As the error rate drops below 100% and the client begins to get successful responses, retries are slowly re-enabled.
In situations where retries have been throttled this feature will result in fail-fast behavior from the client. Because retries are circumvented an exception will be immediately returned to the caller immediately if the initial request is unsuccessful. Although this will result in more up-front exceptions, it will avoid tying up connections and client application threads for longer periods of time. This is particularly important in latency sensitive applications.
Enabling retry throttling
Retry throttling can be enabled by explicitly setting it on the ClientConfiguration, as shown in this example:
ClientConfiguration clientConfig = new ClientConfiguration();
clientConfig.setUseThrottleRetries(true);
AmazonSQS sqs = new AmazonSQSClient(clientConfig);
Alternatively, it can be enabled by including this system property when you start up the JVM. Retry throttling will apply to all client instances running in that VM:
-Dcom.amazonaws.sdk.enableThrottledRetry
As you can see, it’s easy to opt in to this feature. Retry throttling can improve the ability of the SDK to adapt to suboptimal situations. Have you used this feature? Feel free to leave questions or comments below!