AWS HPC Blog
Category: AWS Glue
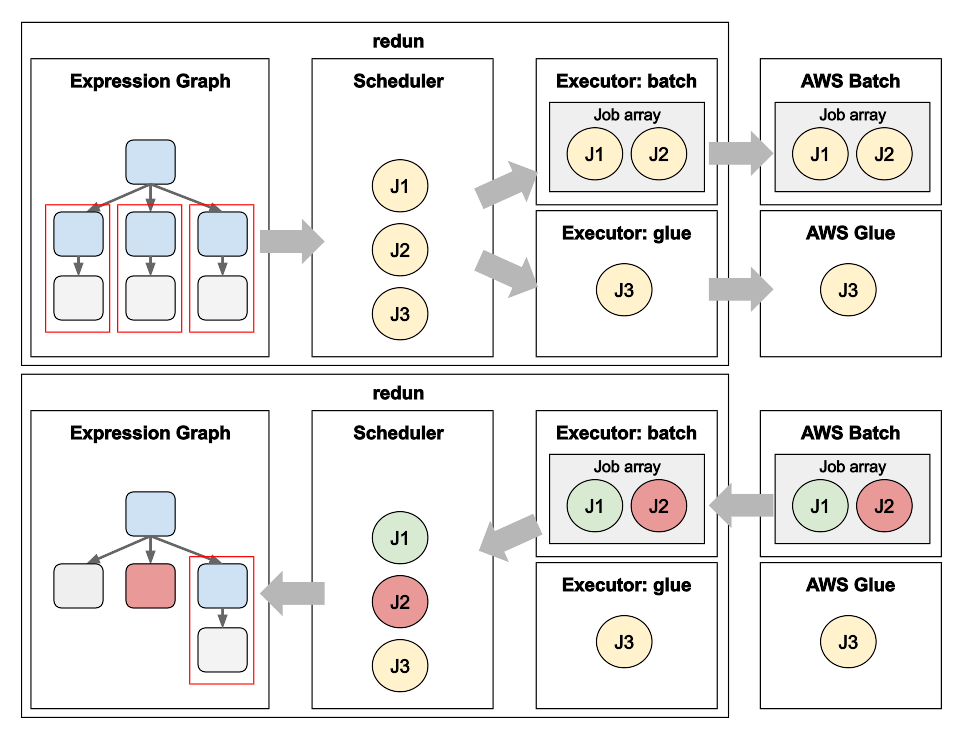
Data Science workflows at insitro: how redun uses the advanced service features from AWS Batch and AWS Glue
Matt Rasmussen, VP of Software Engineering at insitro, expands on his first post on redun, insitro’s data science tool for bioinformatics, to describe how redun makes use of advanced AWS features. Specifically, Matt describes how AWS Batch’s Array Jobs is used to support workflows with large fan-out, and how AWS Glue’s DynamicFrame is used to run computationally heterogenous workflows with different back-end needs such as Spark, all in the same workflow definition.

Data Science workflows at insitro: using redun on AWS Batch
Matt Rasmussen, VP of Software Engineering at insitro describes their recently released, open-source data science framework, redun, which allows data scientists to define complex scientific workflows that scale from their laptop to large-scale distributed runs on serverless platforms like AWS Batch and AWS Glue. I this post, Matt shows how redun lends itself to Bioinformatics workflows which typically involve wrapping Unix-based programs that require file staging to and from object storage. In the next blog post, Matt describes how redun scales to large and heterogenous workflows by leveraging AWS Batch features such as Array Jobs and AWS Glue features such as Glue DynamicFrame.