Artificial Intelligence
Enhanced text classification and word vectors using Amazon SageMaker BlazingText
Today, we are launching several new features for the Amazon SageMaker BlazingText algorithm. Many downstream natural language processing (NLP) tasks like sentiment analysis, named entity recognition, and machine translation require the text data to be converted into real-valued vectors. Customers have been using BlazingText’s highly optimized implementation of the Word2Vec algorithm, for learning these vectors from several hundreds of gigabytes of text documents. The resulting vectors capture the rich meaning and context that we recognize when we read a word. BlazingText being more than 20x faster than other popular alternatives like fastText and Gensim, enables customers to train these vectors on their own datasets containing billions of words using GPUs and multiple CPU machines, hence reducing the training time from days to minutes.
If you haven’t worked with BlazingText before, you might want to start with the documentation or our previous blog post on this algorithm.
We are adding the following new features and enhancements to BlazingText:
- Learning vector representations for character n-grams to enrich word vectors with subword information. It is impossible to have all the words that we come across at the time of inference, in our training dataset, so generating semantic representations for these words is much more useful than ignoring these words altogether or using random vectors for them. BlazingText can generate meaningful vectors for out-of-vocabulary (OOV) words by representing their vectors as the sum of the character n-gram (subword) vectors.
- Ability to perform high speed multi-class and and multi-label text classification. The goal of text classification is to automatically classify the text documents into one or more defined categories, like spam detection, sentiment analysis, or user reviews categorization. BlazingText extends the fastText text classifier to leverage GPU acceleration using optimized CUDA kernels. While the deep learning text classification models (Conneau et al., 2016, Zhang and LeCun (2015)) can take several hours or days to train, BlazingText can do the training in a couple of minutes, thus being more than 100x faster while achieving similar accuracies.
- Host the models trained using BlazingText or pre-trained models provided by fastText for real-time inference. These models can either be supervised text classifiers or the unsupervised Word2Vec models. The latter, when trained with subword embeddings, can also be used to compute representations for OOV words in real time. As the training datasets of NLP models can not include all possible words, this can especially be useful during real-time inference, for e.g. intent classification in Alexa.
On a broader level, BlazingText now supports text classification (supervised mode) and Word2Vec vectors learning (Skip-gram, CBOW, and batch_skipgram modes). Both Skip-gram and CBOW support learning of subword embeddings.
Since different training modes of BlazingText support different hardware configurations, we summarize the EC2 instance compatibility in the following table:
| Word2Vec (unsupervised learning) | Text Classification (supervised learning) | |||
| Modes | Skip-gram (supports subwords) | CBOW (supports subwords) | batch_skipgram | supervised |
| Single CPU instance | ✔ | ✔ | ✔ | ✔ |
| Single GPU instance (with 1 or more GPUs) | ✔ | ✔ | ✔* | |
| Multiple CPU instances | ✔ | |||
* leverages only one GPU
Let’s talk about each of the features in detail.
Enriching word vectors with subword information
Generating word representations by assigning a distinct vector to each word has certain limitations. It can’t deal with out-of-vocabulary (OOV) words, that is, words that have not been seen during training. Typically, such words are set to the unknown (UNK) token and are assigned the same vector, which is an ineffective choice if the number of OOV words is large. Moreover, these representations ignore the morphology of words, thus limiting the representational power, especially for morphologically rich languages, such as German, Turkish, and Finnish.
Bojanowski et al proposed to learn representations for character n-grams, and to represent word vectors as the sum of the character n-gram vectors. They introduce an extension of the Skip-gram and CBOW model that takes into account the subword information. For example, the center word w in the Skip-gram model is represented as a bag of character n-grams. They add special boundary symbols < and > at the beginning and end of words, allowing the algorithm to distinguish prefixes and suffixes from other character sequences. The word w itself is included in the set of its n-grams, to learn a representation for each word (in addition to character n-grams).
Let’s take the word “fast” as an example. With a minimum character n-gram length (min_char parameter in the algorithm) as 3 and maximum character n-gram length (max_char parameter in the algorithm) as 6, “fast” will be represented by the sum of the vectors of the following character n-grams:
‘fast’, ‘<fa’, ‘<fas’, ‘<fast’, ‘<fast>’, ‘fas’, ‘fast>’, ‘ast’, ‘ast>’, ‘st>’
fastText implements this method on multi-core CPUs, which limits its scalability. In BlazingText, we have extended this method to leverage GPU acceleration using custom CUDA kernels.
Usage
Three new hyperparameters have been added to enable and tune subword embedding learning:
Subword embedding learning can be enabled by setting the subwords parameter to “true”. By default, min_char and max_char are set to be 3 and 6 respectively, as suggested by Bojanowski et al .
Currently, this feature is supported in Skipgram and CBOW modes on single CPU instances or GPU instances with 1 GPU (p3.2xlarge or p2.xlarge). To achieve the best performance in terms of speed, accuracy and cost, we recommend using a p3.2xlarge instance.
Performance Benchmarks
We train both BlazingText and fastText using the same parameters on p3.2xlarge and c4.2xlarge instances, respectively. We evaluate the quality of learned representations on the task of word similarity / relatedness using the Stanford rare word dataset (RW) and WS-353 datasets. The word similarity task is to retrieve words that are similar to a given word. These datasets contain word pairs together with human-assigned similarity judgments. The learned word representations are evaluated by ranking the pairs according to their cosine similarities and measuring the Spearmans rank correlation coefficient with the human judgments.
For embeddings trained on the One Billion Word benchmark dataset, we observe that BlazingText is 17x faster than fastText for the Skip-gram mode, at the same cost and the same level of accuracy.
Further, for CBOW, BlazingText is 14.5x faster and more than 10% accurate than FastText at 1.5x the cost. For BlazingText, we compute the cost on Amazon SageMaker, whereas for fastText, we calculate the cost of running the Amazon EC2 instance for the job duration.
To train a Word2Vec model using subword embedding learning on your own dataset, take a look at this notebook.
Accelerated text classification
Text classification is an important task in Natural Language Processing with many applications, such as web search, information retrieval, ranking, and document classification. The goal of text classification is to automatically classify the text documents into one or more defined categories, like spam detection, sentiment analysis, or user reviews categorization. Recently, models based on neural networks have become increasingly popular (Johnson et al., 2017, Conneau et al., 2016). Although these models achieve very good performance in practice, they tend to be relatively slow both at train and test time, which limits their use on very large datasets.
To keep the right balance between scalability and accuracy, BlazingText implements the fastText text classification model, which can train on more than a billion words within ten minutes while achieving performance on par with the state of the art. BlazingText on Amazon SageMaker further extends this model by leveraging GPU acceleration using CUDA kernels, along with other add-ons like Early Stopping and Model Tuning, so that the users don’t have to worry about setting the right hyperparameters.
The following figure depicts the simple yet powerful text classification model:
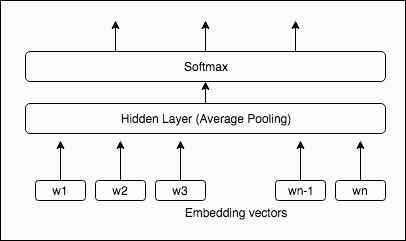
A lookup is done on the embedding matrix to get the vector representations of the words in the document. The word representations are then averaged into a text representation, which is in turn fed to a linear classifier. The text representation is a hidden variable that can potentially be reused.
Since bag-of-words is invariant to word order, the model uses bag-of-words n-grams as additional features to capture some partial information about the local word order. For instance, in the previous figure, if 2-word n-grams are used for training, then vectors representations for w1w2, w2w3,…. wn-1wn will be learned and used for computing the hidden layer along with the individual word vectors. This obviously results in more memory usage, which is bounded by using the hashing trick. The size of embedding matrix for the word n-grams is fixed: buckets x vector_dim. The number of buckets is set to 2 million by default. A hash function is used to map the word n-grams to the bucket indices for vector lookups.
Usage
The following hyperparameters can be defined for text classification using BlazingText:
Early stopping can be enabled (by setting the early_stopping parameter to true) if you want the training to stop after n successive epochs with no improvement in validation accuracy, where n is patience (patience parameter), set to 4 by default. For early stopping to work, you must specify validation data in the “validation” channel.
BlazingText text classification (“supervised” mode) is supported on single CPU instances or single GPU instances with 1 GPU (p3.2xlarge or p2.xlarge).
Have a look at the BlazingText documentation and the Text Classification notebook for more details.
Hosting pre-trained fastText models
A trained model is of no use until it is used for real-time or batch inference. In addition to supporting hosting for text classification and Word2Vec models trained using BlazingText, BlazingText also supports hosting of pre-trained FastText models. FastText models can be hosted without any hassle, with a few lines of code. You need to compress the fastText model files (.bin or .vec) to .tar.gz format, upload to Amazon S3 and execute the following lines:
Conclusion
Amazon SageMaker BlazingText hosting will automatically identify the text classification or the Word2Vec (with or without subwords) model underneath and will start serving requests. The predictor can be used in the following manner:
See this notebook if you want to host a pre-trained fastText model.
About the Authors
 Saurabh Gupta is an Applied Scientist with AWS Deep Learning. He did his MS in AI and Machine Learning from UC San Diego. He is currently working on building Natural Language Processing algorithms for Amazon SageMaker.
Saurabh Gupta is an Applied Scientist with AWS Deep Learning. He did his MS in AI and Machine Learning from UC San Diego. He is currently working on building Natural Language Processing algorithms for Amazon SageMaker.
 Vineet Khare is a Sciences Manager for AWS Deep Learning. He focuses on building Artificial Intelligence and Machine Learning applications for AWS customers using techniques that are at the forefront of research. In his spare time, he enjoys reading, hiking and spending time with his family.
Vineet Khare is a Sciences Manager for AWS Deep Learning. He focuses on building Artificial Intelligence and Machine Learning applications for AWS customers using techniques that are at the forefront of research. In his spare time, he enjoys reading, hiking and spending time with his family.